Reading List
The most recent articles from a list of feeds I subscribe to.
If Not React, Then What?
Over the past decade, my work has centred on partnering with teams to build ambitious products for the web across both desktop and mobile. This has provided a ring-side seat to a sweeping variety of teams, products, and technology stacks across more than 100 engagements.
While I'd like to be spending most of this time working through improvements to web APIs, the majority of time spent with partners goes to remediating performance and accessibility issues caused by “modern” frontend frameworks and the culture surrounding them. Today, these issues are most pronounced in React-based stacks.
This is disquieting because React is legacy technology, but it continues to appear in greenfield applications.
Surprisingly, some continue to insist that React is “modern.” Perhaps we can square the circle if we understand “modern” to apply to React in the way it applies to art. Neither demonstrate contemporary design and construction. They are not built for current needs and do not meet contemporary performance standards, but pose as expensive objets harkening back to an earlier era's antiquated methods.
In the hope of steering the next team away from the rocks, I've found myself penning advocacy pieces and research into the state of play, as well as giving talks to alert managers and developers of the dangers of today's frontend orthodoxy.
In short, nobody should start a new project in the 2020s based on React. Full stop.1
The Rule Of Least Client-Side Complexity
Code that runs on the server can be fully costed. Performance and availability of server-side systems are under the control of the provisioning organisation, and latency can be actively managed.
Code that runs on the client, by contrast, is running on The Devil's Computer.2 Almost nothing about the latency, client resources, or even API availability are under the developer's control.
Client-side web development is perhaps best conceived of as influence-oriented programming. Once code has left the datacentre, all a web developer can do is send thoughts and prayers.
As a direct consequence, an unreasonably effective strategy is to send less code. Declarative forms generate more functional UI per byte sent. In practice, this means favouring HTML and CSS over JavaScript, as they degrade gracefully and feature higher compression ratios. These improvements in resilience and reductions in costs are beneficial in compounding ways over a site's lifetime.
Stacks based on React, Angular, and other legacy-oriented, desktop-focused JavaScript frameworks generally take the opposite bet. These ecosystems pay lip service to the controls necessary for preventing horrific proliferations of unnecessary client-side cruft. The predictable consequence are NPM-amalgamated bundles full of redundancies like core-js, lodash, underscore, polyfills for browsers that no longer exist, userland ECC libraries, moment.js, and a hundred other horrors.
This culture is so out of hand that it seems 2024's React developers are constitutionally unable to build chatbots without including all of these 2010s holdovers, plus at least one chonky MathML or TeX library in the critical path to display an <input>. A tiny fraction of query responses need to display formulas — and yet.
Tech leads and managers need to break this spell. Ownership has to be created over decisions affecting the client. In practice, this means forbidding React in new work.
OK, But What, Then?
This question comes in two flavours that take some work to tease apart:
-
The narrow form:
"Assuming we have a well-qualified need for client-side rendering, what specific technologies would you recommend instead of React?"
-
The broad form:
"Our product stack has bet on React and the various mythologies that the cool kids talk about on React-centric podcasts. You're asking us to rethink the whole thing. Which silver bullet should we adopt instead?"
Teams that have grounded their product decisions appropriately can work through the narrow form by running objective bake offs. Building multiple small PoCs to determine each approach's scaling factors and limits can even be a great deal of fun.3 It's the rewarding side of real engineering; trying out new materials under well-understood constraints to improve outcomes.
Just the prep work to run bake offs tends to generate value.
In most teams, constraints on tech stack decisions have materially shifted since they were last examined. For some, identifying use-cases reveals a reality that's vastly different than managers and tech leads expect. Gathering data on these factors allows for first-pass cuts about stack choices, winnowing quickly to a smaller set of options to run bake offs for.4
But the teams we spend the most time with don't have good reasons to stick with client-side rendering in the first place.
Many folks asking "if not React, then what?" think they're asking in the narrow form but are grappling with the broader version. A shocking fraction of decent, well-meaning product managers and engineers haven't thought through the whys and wherefores of their architectures, opting instead to go with what's popular in a responsibility fire brigade.5
For some, provocations to abandon React induce an unmoored feeling; a suspicion that they might not understand the world any more.6
Teams in this position are working through the epistemology of their values and decisions.7 How can they know their technology choices are better than the alternatives? Why should they pick one stack over another?
Many need help deciding which end of the telescope to use when examining frontend challenges because frameworkism has become the dominant creed of our discourse.
Frameworkism insists that all problems will be solved if teams just framework hard enough. This is non-sequitur, if not entirely backwards. In practice, the only thing that makes web experiences good is caring about the user experience — specifically, the experience of folks at the margins. Technologies come and go, but what always makes the difference is giving a toss about the user.
In less vulgar terms, the struggle is to convince managers and tech leads that they need to start with user needs. Or as Public Digital puts it, "design for user needs, not organisational convenience"
The essential component of this mindset shift is replacing hopes based on promises with constraints based on research and evidence. This aligns with what it means to commit wanton acts of engineering, because engineering is the practice of designing solutions for users and society under known constraints.
The opposite of engineering is imagining that constraints do not exist, or do not apply to your product. The shorthand for this is “bullshit.”
Ousting an engrained practice of bullshitting does not come easily. Frameworkism preaches that the way to improve user experiences is to adopt more (or different) tooling from within the framework's ecosystem. This provides adherents with something to do that looks plausibly like engineering, but isn't.
It can even become a totalising commitment; solutions to user problems outside the framework's expanded cinematic universe are unavailable to the frameworkist. Non-idiomatic patterns that unlock wins for users are bugs to be squashed, not insights to be celebrated. Without data or evidence to counterbalance the bullshit artist's assertions, who's to say they're wrong? So frameworkists root out and devalue practices that generate objective criteria in decision-making. Orthodoxy unmoored from measurement predictably spins into absurdity. Eventually, heresy carries heavy sanctions.
And it's all nonsense.
Realists do not wallow in abstraction-induced hallucinations about user experiences; they measure them. Realism requires reckoning with the world as it is, not as we wish it to be. In that way, realism is the opposite of frameworkism.
The most effective tools for breaking the spell are techniques that give managers a user-centred view of system performance. This can take the form of RUM data, such as Core Web Vitals (check yours now!), or lab results from well-configured test-benches (e.g., WPT). Instrumenting critical user journeys and talking through business goals are quick follow-ups that enable teams to seize the momentum and formulate business cases for change.
RUM and bench data sources are essential antidotes to frameworkism because they provide data-driven baselines to argue from, creating a shared observable reality. Instead of accepting the next increment of framework investment on faith, teams armed with data can weigh up the costs of fad chasing versus likely returns.
And Nothing Of Value Was Lost
Prohibiting the spread of React (and other frameworkist totems) by policy is both an incredible cost savings and a helpful way to reorient teams towards delivery for users. However, better results only arrive once frameworkism itself is eliminated from decision-making. It's no good to spend the windfall from avoiding one sort of mistake on errors within the same category.
A general answer to the broad form of the problem has several parts:
-
User focus
Decision-makers must accept that they are directly accountable for the results of their engineering choices. Either systems work well for users,8 including those at the margins, or they don't. Systems that do not perform must be replaced. No sacred cows, only problems to be solved with the appropriate application of constraints.
-
Evidence
The essential shared commitment between management and engineering is a dedication to realism. Better evidence must win.
-
Guardrails
Policies must be implemented to ward off hallucinatory frameworkist assertions about how better experiences are delivered. Good examples of this include the UK Government Digital Service's requirement that services be built using progressive enhancement techniques.
Organisations can tweak guidance as appropriate — e.g., creating an escalation path for exceptions — but the important thing is to set a baseline. Evidence boiled down into policy has power.
-
Bake Offs
No new system should be deployed without a clear list of critical user journeys. Those journeys embody what we users do most frequently, and once those definitions are in hand, teams can do bake offs to test how well various systems deliver given the constraints of the expected marginal user.
All of this casts the product manager's role in stark relief. Instead of suggesting an endless set of experiments to run (poorly), they must define a product thesis and commit to defining success as improving services for users. This will be uncomfortable. It's also the job. Graciously accept the resignations of PMs who decide managing products is not in their wheelhouse.
Vignettes
To see how realism and frameworkism differ in practice, it's helpful to work a few examples. As background, recall that our rubric9 for choosing technologies is based on the number of incremental updates to primary data in a session. Some classes of app, like editors, feature long sessions and many incremental updates where a local data model can be helpful in supporting timely application of updates, but this is the exception.

It's only in these exceptional instances that SPA architectures should be considered.

And only when an SPA architecture is required should tools designed to support optimistic updates against a local data model — including "frontend frameworks" and "state management" tools — ever become part of a site's architecture.
The choice isn't between JavaScript frameworks, it's whether SPA-oriented tools should be entertained at all.
For most sites, the answer is clearly "no".
We can examine broad classes of site to understand why this is true:
Informational
Sites built to inform should almost always be built using semantic HTML with optional progressive enhancement as necessary.
Static site generation tools like Hugo, Astro, 11ty, and Jekyll work well for many of these cases. Sites that have content that changes more frequently should look to "classic" CMSes or tools like WordPress to generate HTML and CSS.
Blogs, marketing sites, company home pages, and public information sites should minimise client-side JavaScript to the greatest extent possible. They should never be built using frameworks that are designed to enable SPA architectures.10
Why Semantic Markup and Optional Progressive Enhancement Are The Right Choice
Informational sites have short sessions and server-owned application data models; that is, the source of truth for what's displayed on the page is always the server's to manage and own. This means that there is no need for a client-side data model abstraction or client-side component definitions that might be updated from such a data model.
Note: many informational sites include productivity components as distinct sub-applications, which can be evaluated independently. For example, CMSes such as Wordpress are comprised of two distinct surfaces; post editors that are low-traffic but high-interactivity, and published pages, which are high-traffic, low-interactivity viewers. Progressive enhancement should be considered for both, but is an absolute must for reader views which do not feature long sessions.9:1
E-Commerce
E-commerce sites should be built using server-generated semantic HTML and progressive enhancement.
Many tools are available to support this architecture. Teams building e-commerce experiences should prefer stacks that deliver no JavaScript by default, and buttress that with controls on client-side script to prevent regressions in material business metrics.
Why Progressive Enhancement Is The Right Choice
The general form of e-commerce sites has been stable for more than 20 years:
- Landing pages with current offers and a search function for finding products.
- Search results pages which allow for filtering and comparison of products.
- Product-detail pages that host media about products, ratings, reviews, and recommendations for alternatives.
- Cart management, checkout, and account management screens.
Across all of these page types, a pervasive login and cart status widget will be displayed. Sometimes this widget, and the site's logo, are the only consistent elements.
Long experience demonstrates very little shared data across these page types, highly variable session lengths, and a need for fresh content (e.g., prices) from the server. The best way to reduce latency in e-commerce sites is to optimise for lightweight, server-generated pages. Aggressive caching, image optimisation, and page-weight reduction strategies all help.
Media
Media consumption sites vary considerably in session length and data update potential. Most should start as progressively-enhanced markup-based experiences, adding complexity over time as product changes warrant it.
Why Progressive Enhancement and Islands May Be The Right Choice
Many interactive elements on media consumption sites can be modelled as distinct islands of interactivity (e.g., comment threads). Many of these components present independent data models and can therefore be constructed as progressively-enhanced Web Components within a larger (static) page.
When An SPA May Be Appropriate
This model breaks down when media playback must continue across media browsing (think "mini-player" UIs). A fundamental limitation of today's web platform is that it is not possible to preserve some elements from a page across top-level navigations. Sites that must support features like this should consider using SPA technologies while setting strict guardrails for the allowed size of client-side JS per page.
Another reason to consider client-side logic for a media consumption app is offline playback. Managing a local (Service Worker-backed) media cache requires application logic and a way to synchronise information with the server.
Lightweight SPA-oriented frameworks may be appropriate here, along with connection-state resilient data systems such as Zero or Y.js.
Social
Social media apps feature significant variety in session lengths and media capabilities. Many present infinite-scroll interfaces and complex post editing affordances. These are natural dividing lines in a design that align well with session depth and client-vs-server data model locality.
Why Progressive Enhancement May Be The Right Choice
Most social media experiences involve a small, fixed number of actions on top of a server-owned data model ("liking" posts, etc.) as well as distinct update phase for new media arriving at an interval. This model works well with a hybrid approach as is found in Hotwire and many HTMX applications.
When An SPA May Be Appropriate
Islands of deep interactivity may make sense in social media applications, and aggressive client-side caching (e.g., for draft posts) may aid in building engagement. It may be helpful to think of these as unique app sections with distinct needs from the main site's role in displaying content.
Offline support may be another reason to download a snapshot of user data to the client. This should be as part of an approach that builds resilience against flaky networks. Teams in this situation should consider a Service Worker-based, multi-page apps with "stream stitching". This allows sites to stick with HTML, while enabling offline-first logic and synchronisation. Because offline support is so invasive to an architecture, this requirement must be identified up-front.
Note: Many assume that SPA-enabling tools and frameworks are required to build compelling Progressive Web Apps that work well offline. This is not the case. PWAs can be built using stream-stitching architectures that apply the equivalent of server-side templating to data on the client, within a Service Worker.
With the advent of multi-page view transitions, MPA architecture PWAs can present fluid transitions between user states without heavyweight JavaScript bundles clogging up the main thread. It may take several more years for the framework community to digest the implications of these technologies, but they are available today and work exceedingly well, both as foundational architecture pieces and as progressive enhancements.
Productivity
Document-centric productivity apps may be the hardest class to reason about, as collaborative editing, offline support, and lightweight "viewing" modes with full document fidelity are hard product requirements.
Triage-oriented experiences (e.g. email clients) are also prime candidates for the potential benefits of SPA-based technology. But as with all SPAs, the ability to deliver a better experience hinges both on session depth and up-front payload cost. It's easy to lose this race, as this blog has examined in the past.
Editors of all sorts are a natural fit for local data models and SPA-based architectures to support modifications to them. However, the endemic complexity of these systems ensures that performance will remain a constant struggle. As a result, teams building applications in this style should consider strong performance guardrails, identify critical user journeys up-front, and ensure that instrumentation is in place to ward off unpleasant performance surprises.
Why SPAs May Be The Right Choice
Editors frequently feature many updates to the same data (e.g., for every keystroke or mouse drag). Applying updates optimistically and only informing the server asynchronously of edits can deliver a superior experience across long editing sessions.
However, teams should be aware that editors may also perform double duty as viewers and that the weight of up-front bundles may not be reasonable for both cases. Worse, it can be hard to tease viewing sessions apart from heavy editing sessions at page load time.
Teams that succeed in these conditions build extreme discipline about the modularity, phasing, and order of delayed package loading based on user needs (e.g., only loading editor components users need when they require them). Teams that get stuck tend to fail to apply controls over which team members can approve changes to critical-path payloads.
Other Application Classes
Some types of apps are intrinsically interactive, focus on access to local device hardware, or center on manipulating media types that HTML doesn't handle intrinsically. Examples include 3D CAD systems, programming editors, game streaming services, web-based games, media-editing, and music-making systems. These constraints often make client-side JavaScript UIs a natural fit, but each should be evaluated critically:
- What are the critical user journeys?
- How long will average sessions be?
- Do many updates to the same data take place in a session?
- What metrics will we track to ensure that performance remains acceptable?
- How will we place tight controls on critical-path script and other resources?
Success in these app classes is possible on the web, but extreme care is required.
A Word On Enterprise Software: Some of the worst performance disasters I've helped remediate are from a category we can think of, generously, as "enterprise line-of-business apps". Dashboards, worfklow systems, corporate chat apps, that sort of thing.
Teams building these excruciatingly slow apps often assert that "startup performance isn't important because people start our app in the morning and keep it open all day". At the limit, this can be true, but what this attempted deflection obscures is that performance is cultural. Teams that fail to define and measure critical user journeys (include loading) always fail to manage post-load interactivity too.
The old saying "how you do anything is how you do everything" is never more true than in software usability.
One consequence of cultures that fail to put the user first are products whose usability is so poor that attributes which didn't matter at the time of sale (like performance) become reasons to switch.
If you've ever had the distinct displeasure of using Concur or Workday, you'll understand what I mean. Challengers win business from them not by being wonderful, but simply by being usable. These incumbents are powerless to respond because their problems are now rooted deeply in the behaviours they rewarded through hiring and promotion along the way. The resulting management blindspot becomes a self-reinforcing norm that no single leader can shake.
This is why it's caustic to product success and brand value to allow a culture of disrespect towards users in favour of venerating developers (e.g., "DX"). The only antidote is to stamp it out wherever it arises by demanding user-focused realism in decision making.
"But..."
To get unstuck, managers and tech leads that become wedded to frameworkism have to work through a series of easily falsified rationales offered by Over Reactors in service of their chosen ideology. Note, as you read, that none of these protests put the user experience front-and-centre. This admission by omission is a reliable property of the conversations these sketches are drawn from.
"...we need to move fast"
This chestnut should be answered with the question: "for how long?"
The dominant outcome of fling-stuff-together-with-NPM, feels-fine-on-my-$3K-laptop development is to get teams stuck in the mud much sooner than anyone expects.
From major accessibility defects to brand-risk levels of lousy performance, the consequence of this approach has been crossing my desk every week for a decade. The one thing I can tell you that all of these teams and products have in common is that they are not moving faster.
Brands you've heard of and websites you used this week have come in for help, which we've dutifully provided. The general prescription is "spend a few weeks/months unpicking this Gordian knot of JavaScript."
The time spent in remediation does fix the revenue and accessibility problems that JavaScript exuberance cause, but teams are dead in the water while they belatedly add ship gates and bundle size controls and processes to prevent further regression.
This necessary, painful, and expensive remediation generally comes at the worst time and with little support, owing to the JavaScript-industrial-complex's omerta. Managers trapped in these systems experience a sinking realisation that choices made in haste are not so easily revised. Complex, inscrutable tools introduced in the "move fast" phase are now systems that teams must dedicate time to learn, understand deeply, and affirmatively operate. All the while the pace of feature delivery is dramatically reduced.
This isn't what managers think they're signing up for when accepting "but we need to move fast!"
But let's take the assertion at face value and assume a team that won't get stuck in the ditch (🤞): the idea embedded in this statement is, roughly, that there isn't time to do it right (so React?), but there will be time to do it over.
This is in direct opposition to identifying product-market-fit. After all, the way to find who will want your product is to make it as widely available as possible, then to add UX flourishes.
Teams I've worked with are frequently astonished to find that removing barriers to use opens up new markets and leads to growth in parts of a world they had under-valued.
Now, if you're selling Veblen goods, by all means, prioritise anything but accessibility. But in literally every other category, the returns to quality can be best understood as clarity of product thesis. A low-quality experience — which is what is being proposed when React is offered as an expedient — is a drag on the core growth argument for your service. And if the goal is scale, rather than exclusivity, building for legacy desktop browsers that Microsoft won't even sell you at the cost of harming the experience for the majority of the world's users is a strategic error.
"...it works for Facebook"
To a statistical certainty, you aren't making Facebook. Your problems likely look nothing like Facebook's early 2010s problems, and even if they did, following their lead is a terrible idea.
And these tools aren't even working for Facebook (or IG, or Threads). They just happen to be a monopoly in various social categories and can afford to light money on fire. If that doesn't describe your situation, it's best not to over index on narratives premised on Facebook's perceived success.
"...our teams already know React"
React developers are web developers. They have to operate in a world of CSS, HTML, JavaScript, and DOM. It's inescapable. This means that React is the most fungible layer in the stack. Moving between templating systems (which is what JSX is) is what web developers have done fluidly for more than 30 years. Even folks with deep expertise in, say, Rails and ERB, can easily knock out Django or Laravel or WordPress or 11ty sites. There are differences, sure, but every web developer is a polyglot.
React knowledge is also not particularly valuable. Any team familiar with React's...baroque...conventions can easily master Preact, Stencil, Svelte, Lit, FAST, Qwik, or any of a dozen faster, smaller, reactive client-side systems that demand less mental bookkeeping.
"...we need to be able to hire easily"
The tech industry has just seen many of the most talented, empathetic, and user-focused engineers I know laid off for no reason other than their management couldn't figure out that there would be some mean reversion post-pandemic. Which is to say, there's a fire sale on talent right now, and you can ask for whatever skills you damn well please and get good returns.
If you cannot attract folks who know web standards and fundamentals, reach out. I'll help you formulate recs, recruiting materials, hiring rubrics, and promotion guides to value these folks the way you should: unreasonably effective collaborators that will do incredible good for your products at a fraction of the cost of solving the next problem the React community is finally acknowledging that React caused.
Resumes Aren't Murder/Suicide Pacts
But even if you decide you want to run interview loops to filter for React knowledge, that's not a good reason to use it! Anyone who can master the dark thicket of build tools, typescript foibles, and the million little ways that JSX's fork of HTML and JavaScript syntax trips folks up is absolutely good enough to work in a different system.
Heck, they're already working in an ever-shifting maze of faddish churn. The treadmill is real, which means that the question isn't "will these folks be able to hit the ground running?" (answer: no, they'll spend weeks learning your specific setup regardless), it's "what technologies will provide the highest ROI over the life of our team?"
Given the extremely high costs of React and other frameworkist prescriptions, the odds that this calculus will favour the current flavour of the week over the lifetime of even a single project are vanishingly small.
The Bootcamp Thing
It makes me nauseous to hear managers denigrate talented engineers, and there seems to be a rash of it going around. The idea that folks who come out of bootcamps — folks who just paid to learn whatever was on the syllabus — aren't able or willing to pick up some alternative stack is bollocks.
Bootcamp grads might be junior, and they are generally steeped in varying strengths of frameworkism, but they're not stupid. They want to do a good job, and it's management's job to define what that is. Many new grads might know React, but they'll learn a dozen other tools along the way, and React is by far the most (unnecessarily) complex of the bunch. The idea that folks who have mastered the horrors of useMemo and friends can't take on board DOM lifecycle methods or the event loop or modern CSS is insulting. It's unfairly stigmatising and limits the organisation's potential.
In other words, definitionally atrocious management.
"...everyone has fast phones now"
For more than a decade, the core premise of frameworkism has been that client-side resources are cheap (or are getting increasingly inexpensive) and that it is, therefore, reasonable to trade some end-user performance for developer convenience.
This has been an absolute debacle. Since at least 2012, the rise of mobile falsified this contention, and (as this blog has meticulously catalogued) we are only just starting to turn the corner.
Frameworkist assertion that "everyone has fast phones" is many things, but first and foremost it's an admission that the folks offering it don't know what they're talking about — and they hope you don't either.
No business trying to make it on the web can afford what they're selling, and you are under no obligation to offer your product as sacrifice to a false god.
"...React is industry-standard"
This is, at best, a comforting fiction.
At worst, it's a knowing falsity that serves to omit the variability in React-based stacks because, you see, React isn't one thing. It's more of a lifestyle, complete with choices to make about React itself (function components or class components?) languages and compilers (typescript or nah?), package managers and dependency tools (npm? yarn? pnpm? turbo?), bundlers (webpack? esbuild? swc? rollup?), meta-tools (vite? turbopack? nx?), "state management" tools (redux? mobx? apollo? something that actually manages state?) and so on and so forth. And that's before we discuss plugins to support different CSS transpilation, among other optional side-quests frameworkists insist are necessary.
Across more than 100 consulting engagements, I've never seen two identical React setups, save smaller cases where the defaults of Create React App were unchanged. CRA itself changed dramatically over the years before finally being removed from the React docs as the best way to get started.
There's nothing standard about any of this. It's all change, all the time, and anyone who tells you differently is not to be trusted.
The Bare (Assertion) Minimum
Hopefully, if you've made it this far, you'll forgive a digression into how the "React is industry standard" misdirection became so embedded.
Given the overwhelming evidence that this stuff isn't even working on the sites of the titular React poster children, how did we end up with React in so many nooks and crannies of contemporary frontend?
Pushy know-it-alls, that's how. Frameworkists have a way of hijacking every conversation with assertions like "virtual DOM is fast" without ever understanding anything about how browsers work, let alone the GC costs of their (extremely chatty) alternatives. This same ignorance allows them to confidently assert that React is "fine" when cheaper alternatives exist in every dimension.
These are not serious people. You do not have to entertain arguments offered without evidence. But you do have to oppose them and create data-driven structures that put users first. The long-term costs of these errors are enormous, as witnessed by the parade of teams needing our help to achieve minimally decent performance using stacks that were supposed to be "performant" (sic).
"...the ecosystem..."
Which part, exactly? Be extremely specific. Which packages are so valuable, yet wedded entirely to React, that a team should not entertain alternatives? Do they really not work with Preact? How much money is exactly the right amount to burn to use these libraries? Because that's the debate.
Even if you get the benefits of "the ecosystem" at Time 0, why do you think that will continue to pay out at T+1? Or T+N?
Every library presents a separate, stochastic risk of abandonment. Even the most heavily used systems fall out of favour with the JavaScript-industrial-complex's in-crowd. This strands teams in the same position they'd have been in if they accepted ownership of more of the stack up-front, but with less experience and agency. Is that a good trade? Does your boss agree?
And how's that "CSS-in-JS" adventure working out? Still writing class components, or did you have a big forced (and partial) migration that's still creating headaches?
The truth is that every single package that is part of a repo's devDependencies is, or will be, fully owned by the consumer of the package. The only bulwark against uncomfortable surprises is to consider NPM dependencies a high-interest loan collateralized by future engineering capacity.
The best way to prevent these costs spiralling out of control is to fully examine and approve each and every dependency for UI tools and build systems. If your team is not comfortable agreeing to own, patch, and improve every single one of those systems, they should not be part of your stack.
"...Next.js can be fast (enough)"
Do you feel lucky, punk? Do you?
You'll have to be lucky to beat the odds.
Sites built with Next.js perform materially worse than those from HTML-first systems like 11ty, Astro, et al.
It simply does not scale, and the fact that it drags React behind it like a ball and chain is a double demerit. The chonktastic default payload of delay-loaded JS in any Next.js site will compete with ads and other business-critical deferred content for bandwidth, and that's before custom components and routes are added. Even when using React Server Components. Which is to say, Next.js is a fast way to lose a lot of money while getting locked in to a VC-backed startup's proprietary APIs.
Next.js starts bad and only gets worse from a shocking baseline. No wonder the only Next sites that seem to perform well are those that enjoy overwhelmingly wealthy user bases, hand-tuning assistance from Vercel, or both.
So, do you feel lucky?
"...React Native!"
React Native is a good way to make a slow app that requires constant hand-tuning and an excellent way to make a terrible website. It has also been abandoned by it's poster children.
Companies that want to deliver compelling mobile experiences into app stores from the same codebase as their website are better served investigating Trusted Web Activities and PWABuilder. If those don't work, Capacitor and Cordova can deliver similar benefits. These approaches make most native capabilities available, but centralise UI investment on the web side, providing visibility and control via a single execution path. This, in turn, reduces duplicate optimisation and accessibility headaches.
References
These are essential guides for frontend realism. I recommend interested tech leads, engineering managers, and product managers digest them all:
- "Building a robust frontend using progressive enhancement" from the UK's Government Digital Service.
- "JavaScript dos and donts" by Github alumnus Mu-An Chiou.
- "Choosing Your Stack" from Cancer Research UK
- "The Monty Hall Rewrite" by Alex Sexton, which breaks down the essential ways that a failure to run an honest bake off harms decision-making.
- "Things you forgot (or never knew) because of React" by Josh Collinsworth, which enunciates just how baroque and parochial React's culture has become.
- "The Frontend Treadmill" by Marco Rogers explains the costs of frameworkism better than I ever could.
- "Questions for a new technology" by Kellan Elliott-McCrea and Glyph's "Against Innovation Tokens". Together, they set a well-focused lens for thinking about how frameworkism is antithetical to functional engineering culture.
These pieces are from teams and leaders that have succeeded in outrageously effective ways by applying the realist tenants of looking around for themselves and measuring. I wish you the same success.
Thanks to Mu-An Chiou, Hasan Ali, Josh Collinsworth, Ben Delarre, Katie Sylor-Miller, and Mary for their feedback on drafts of this post.
FOOTNOTES
Why not React? Dozens of reasons, but a shortlist must include:
- React is legacy technology. It was built for a world where IE 6 still had measurable share, and it shows.
- React's synthetic event system and hard-coded element list are a direct consequence of IE's limitations. Independently, these create portability and performance hazards. Together, they become a driver of lock-in.
- No contemporary framework contains equivalents because no other framework is fundamentally designed around the need to support IE.
- It's beating a dead horse, but Microsoft's own flagship apps do not support IE. You cannot buy support for IE. It has even been forcibly removed from Windows 10 machines and has not appeared above the noise in global browser market share stats for more than 4 years.
New projects will never encouter IE, and it's vanishingly unlikely that existing applications need to support it — which is helpful, because nobody can securely test on it anyway.
- Virtual DOM was never fast.
- React was forced to back away from misleading performance claims almost immediately.11
- In addition to being unnecessary to achieve reactivity, React's diffing model and poor support for dataflow management conspire to regularly generate extra main-thread work in the critical path. The "solution" is to learn (and zealously apply) a set of extremely baroque, React-specific solutions to problems React itself causes.
- The only (positive) contribution to performance that React's doubled-up work model can, in theory, provide is a structured lifecycle that helps programmers avoid reading back style and layout information at the moments when it's most expensive.
- In practice, React does not prevent forced layouts and is not able to even warn about them. Unsurprisingly, every React app that crosses my desk is littered with layout thrashing bugs.
- The only defensible performance claims Reactors make for their work-doubling system are phrased as a trade; e.g. "CPUs are fast enough now that we can afford to do work twice for developer convenience."
- Except they aren't. CPUs stopped getting faster about the same time as Reactors began to perpetuate this myth. This did not stop them from pouring JS into the ecosystem as though the old trends had held, with predictably disasterous results
- It isn't even necessary to do all the work twice to get reactivity! Every other reactive component system from the past decade is significantly more efficient, weighs less on the wire, and preserves the advantages of reactivitiy without creating horrible "re-render debugging" hunts that take weeks away from getting things done.
- Except they aren't. CPUs stopped getting faster about the same time as Reactors began to perpetuate this myth. This did not stop them from pouring JS into the ecosystem as though the old trends had held, with predictably disasterous results
- React's thought leaders have been wrong about frontend's constraints for more than a decade.
- Why would you trust them now? Their own websites perform poorly in the real world.
- The money you'll save can be measured in truck-loads.
- Teams that correctly cabin complexity to the server side can avoid paying inflated salaries to begin with.
- Teams that do build SPAs can more easily control the costs of those architectures by starting with a cheaper baseline and building a mature performance culture into their organisations from the start.
- Not for nothing, but avoiding React will insulate your team from the assertion-heavy, data-light React discourse.
Why pick a slow, backwards-looking framework whose architecture is compromised to serve legacy browsers when smaller, faster, better alternatives with all of the upsides (and none of the downsides) have been production-ready and successful for years? ⇐
- React is legacy technology. It was built for a world where IE 6 still had measurable share, and it shows.
Frontend web development, like other types of client-side programming, is under-valued by "generalists" who do not respect just how freaking hard it is to deliver fluid, interactive experiences on devices you don't own and can't control. Web development turns this up to eleven, presenting a wicked effective compression format for UIs (HTML & CSS) but forces experiences to load at runtime across high-latency, narrowband connections. To low-end devices. With no control over which browser will execute the code.
And yet, browsers and web developers frequently collude to deliver outstanding interactivity under these conditions. Often enough, that "generalists" don't give a second thought to the miracle of HTML-centric Wikipedia and MDN articles loading consistently quickly, as they gleefully clog those narrow pipes with JavaScript payloads so large that they can't possibly deliver similarly good experiences. All because they neither understand nor respect client-side constraints.
It's enough to make thoughtful engineers tear their hair out. ⇐ ⇐
Tom Stoppard's classic quip that "it's not the voting that's democracy; it's the counting" chimes with the importance of impartial and objective criteria for judging the results of bake offs.
I've witnessed more than my fair share of stacked-deck proof-of-concept pantomimes, often inside large organisations with tremendous resources and managers who say all the right things. But honesty demands more than lip service.
Organisations looking for a complicated way to excuse pre-ordained outcomes should skip the charade. It will only make good people cynical and increase resistance. Teams that want to set bales of benajmins on fire because of frameworkism shouldn't be afraid to say what they want.
They were going to get it anyway; warts and all. ⇐
An example of easy cut lines for teams considering contemporary development might be browser support versus bundle size.
In 2024, no new application will need to support IE or even legacy versions of Edge. They are not a measurable part of the ecosystem. This means that tools that took the design constraints imposed by IE as a given can be discarded from consideration. The extra client-side weight they require to service IE's quirks makes them uncompetitive from a bundle size perspective.
This eliminates React, Angular, and Ember from consideration without a single line of code being written; a tremendous savings of time and effort.
Another example is lock-in. Do systems support interoperability across tools and frameworks? Or will porting to a different system require a total rewrite? A decent proxy for this choice is Web Components support.
Teams looking to avoid lock-in can remove frameworks from consideration that do not support Web Components as both an export and import format. This will still leave many contenders, and management can rest assured they will not leave the team high-and-dry.14 ⇐
The stories we hear when interviewing members of these teams have an unmistakable buck-passing flavour. Engineers will claim (without evidence) that React is a great13 choice for their blog/e-commerce/marketing-microsite because "it needs to be interactive" — by which they mean it has a Carousel and maybe a menu and some parallax scrolling. None of this is an argument for React per se, but it can sound plausible to managers who trust technical staff about technical matters.
Others claim that "it's an SPA". But should it be a Single Page App? Most are unprepared to answer that question for the simple reason they haven't thought it through.9:2
For their part, contemporary product managers seem to spend a great deal of time doing things that do not have any relationship to managing the essential qualities of their products.
Most need help making sense of the RUM data already available to them. Few are in touch with device and network realities of their current and future (🤞) users. PMs that clearly articulate critical-user-journeys for their teams are like hen's teeth. And I can count on one hand teams that have run bake offs — without resorting to binary. ⇐
It's no exaggeration to say that team leaders encountering evidence that their React (or Angular, etc.) technology choices are letting down users and the business go through some things.
Following the herd is an adaptation to prevent their specific decisions from standing out — tall poppies and all that — and it's uncomfortable when those decisions receive belated scrutiny. But when the evidence is incontrovertible, needs must. This creates cognitive dissonance.
Few are so entitled and callous that they wallow in denial. Most want to improve. They don't come to work every day to make a bad product; they just thought the herd knew more than they did. It's disorienting when that turns out not to be true. That's more than understandable.
Leaders in this situation work through the stages of grief in ways that speak to their character.
Strong teams own the reality and look for ways to learn more about their users and the constraints that should shape product choices. The goal isn't to justify another rewrite, but to find targets the team should work towards, breaking down the problem into actionable steps. This is hard and often unfamiliar work, but it is rewarding. Setting accurate goalposts helps teams take credit as they make progress remediating the current mess. These are all markers of teams on the way to improving their performance management maturity.
Some get stuck in anger, bargaining, or depression. Sadly, these teams are taxing to help. Supporting engineers and PMs through emotional turmoil is a big part of a performance consultant's job. The stronger the team's attachment to React community narratives, the harder it can be to accept responsibility for defining team success in terms of user success. But that's the only way out of the deep hole they've dug.
Consulting experts can only do so much. Tech leads and managers that continue to prioritise "Developer Experience" (without metrics, obviously) and "the ecosystem" (pray tell, which parts?) in lieu of user outcomes can remain beyond reach, no matter how much empathy and technical analysis is provided. Sometimes, you have to cut bait and hope time and the costs of ongoing failure create the necessary conditions for change. ⇐
Most are substituting (perceived) popularity for the work of understanding users and their needs. Starting with user needs creates constraints to work backwards from.
Instead of doing this work-back, many sub in short-term popularity contest winners. This goes hand-in-glove with a predictable failure to deeply understand business goals.
It's common to hear stories of companies shocked to find the PHP/Python/etc. systems they are replacing with React will require multiples of currently allocated server resources for the same userbase. The impacts of inevitably worse client-side lag cost dearly, but only show up later. And all of these costs are on top of the salaries for the bloated teams frameworkists demand.
One team shared that avoidance of React was tantamount to a trade secret. If their React-based competitors understood how expensive React stacks are, they'd lose their (considerable) margin advantage. Wild times. ⇐
UIs that works well for all users aren't charity, they're hard-nosed business choices about market expansion and development cost.
Don't be confused: every time a developer makes a claim without evidence that a site doesn't need to work well on a low-end device, understand it as a true threat to your product's success, if not your own career.
The point of building a web experience is to maximize reach for the lowest development outlay, otherwise you'd build a bunch of native apps for every platform instead. Organisations that aren't spending bundles to build per-OS proprietary apps...well...aren't doing that. In this context, unbacked claims about why it's OK to exclude large swaths of the web market to introduce legacy desktop-era frameworks designed for browsers that don't exist any more work directly against strategy. Do not suffer them gladly.
In most product categories, quality and reach are the product attributes web developers can impact most directly. It's wasteful, bordering insubbordinate, to suggest that not delivering those properties is an effective use of scarce funding. ⇐
Should a site be built as a Single Page App?
A good way to work this question is to ask "what's the point of an SPA?". The answer is that they can (in theory) reduce interaction latency, which implies many interactions per session. It's also an (implicit) claim about the costs of loading code up-front versus on-demand. This sets us up to create a rule of thumb.
Sites should only be built as SPAs, or with SPA-premised technologies if and only if:
- They are known to have long sessions (more than ten minutes) on average
- More than ten updates are applied to the same (primary) data
This instantly disqualifies almost every e-commerce experience, for example, as sessions generally involve traversing pages with entirely different primary data rather than updating a subset of an existing UI. Most also feature average sessions that fail the length and depth tests. Other common categories (blogs, marketing sites, etc.) are even easier to disqualify. At most, these categories can stand a dose of progressive enhancement (but not too much!) owing to their shallow sessions.
What's left? Productivity and social apps, mainly.
Of course, there are many sites with bi-modal session types or sub-apps, all of which might involve different tradeoffs. For example, a blogging site is two distinct systems combined by a database/CMS. The first is a long-session, heavy interaction post-writing and editing interface for a small set of users. The other is a short-session interface for a much larger audience who mostly interact by loading a page and then scrolling. As the browser, not developer code, handles scrolling, we omit from interaction counts. For most sessions, this leaves us only a single data update (initial page load) to divide all costs by.
If the denominator of our equation is always close to one, it's nearly impossible to justify extra weight in anticipation of updates that will likely never happen.12
To formalise slightly, we can understand average latency as the sum of latencies in a session, divided by the number of interactions. For multi-page architectures, a session's average latency () is simply a session's summed 's divided by the number of navigations in a session ():
SPAs need to add initial navigation latency to the latencies of all other session interactions (). The total number of interactions in a session is:
The general form is of SPA average latency is:
We can handwave a bit and use for each individual update (via the Performance Timeline) as our measure of in-page update lag. This leaves some room for gamesmanship — the React ecosystem is famous for attempting to duck metrics accountability with scheduling shenanigans — so a real measurement system will need to substitute end-to-end action completion (including server latency) for , but this is a reasonable bootstrap.
also helpfully omits scrolling unless the programmer does something problematic. This is correct for the purposes of metric construction as scrolling gestures are generally handled by the browser, not application code, and our metric should only measure what developers control. SPA average latency simplifies to:
As a metric for architecture, this is simplistic and fails to capture variance, which SPA defenders will argue matters greatly. How might we incorporate it?
Variance () across a session is straightforward if we have logs of the latencies of all interactions and an understanding of latency distributions. Assuming latencies follows the Erlang distribution, we would have to work to assess variance, except that complete logs simplify this to the usual population variance formula. Standard deviation () is then just the square root:
Where is the mean (average) of the population , the set of measured latencies in a session, with this value summed across all sessions.
We can use these tools to compare architectures and their outcomes, particularly the effects of larger up-front payloads for SPA architecture for sites with shallow sessions. Suffice to say, the smaller the deonominator (i.e., the shorter the session), the worse average latency will be for JavaScript-oriented designs and the more sensitive variance will be to population-level effects of hardware and networks.
A fuller exploration will have to wait for a separate post. ⇐ ⇐ ⇐
Certain frameworkists will claim that their framework is fine for use in informational scenarios because their systems do "Server-Side Rendering" (a.k.a., "SSR").
Parking for a moment discussion of the linguistic crime that "SSR" represents, we can reject these claims by substituting a test: does the tool in question send a copy of a library to support SPA navigations down the wire by default?
This test is helpful, as it shows us that React-based tools like Next.js are wholly unsuitable for this class of site, while React-friendly tools like Astro are appropriate.
We lack a name for this test today, and I hope readers will suggest one. ⇐
React's initial claims of good performance because it used a virtual DOM were never true, and the React team was forced to retract them by 2015. But like many zombie ideas, there seems to have been no reduction in the rate of junior engineers regurgitating this long-falsified idea as a reason to continue to choose React.
How did such a baldly incorrect claim come to be offered in the first place? The options are unappetising; either the React team knew their work-doubling machine was not fast but allowed others to think it was, or they didn't know but should have.15
Neither suggest the sort of grounded technical leadership that developers or businesses should invest heavily in. ⇐
It should go without saying, but sites that aren't SPAs shouldn't use tools that are premised entirely on optimistic updates to client-side data because sites that aren't SPAs shouldn't be paying the cost of creating a (separate, expensive) client-side data store separate from the DOM representation of HTML.
Which is the long way of saying that if there's React or Angular in your blogware, 'ya done fucked up, son. ⇐
When it's pointed out that React is, in fact, not great in these contexts, the excuses come fast and thick. It's generally less than 10 minutes before they're rehashing some variant of how some other site is fast (without traces to prove it, obvs), and it uses React, so React is fine.
Thus begins an infinite regression of easily falsified premises.
The folks dutifully shovelling this bullshit aren't consciously trying to invoke Brandolini's Law in their defence, but that's the net effect. It's exhausting and principally serves to convince the challenged party not that they should try to understand user needs and build to them, but instead that you're an asshole. ⇐
Most managers pay lip service to the idea of preferring reversible decisions. Frustratingly, failure to put this into action is in complete alignment with social science research into the psychology of decision-making biases (open access PDF summary).
The job of managers is to manage these biases. Working against them involves building processes and objective frames of reference to nullify their effects. It isn't particularly challenging, but it is work. Teams that do not build this discipline pay for it dearly, particularly on the front end, where we program the devil's computer.2:1
But make no mistake: choosing React is a one-way door; an irreversible decision that is costly to relitigate. Teams that buy into React implicitly opt into leaky abstractions like timing quirks of React's unique (as in, nobody else has one because it's costly and slow) synthentic event system and non-portable concepts like portals. React-based products are stuck, and the paths out are challenging.
This will seem comforting, but the long-run maintenance costs of being trapped in this decision are excruciatingly high. No wonder Over Reactors believe they should command a salary premium.
Whatcha gonna do, switch? ⇐
Where do I come down on this?
My interactions with React team members over the years, combined with their confidently incorrect public statements about how browsers work, have convinced me that honest ignorance about their system's performance sat underneath misleading early claims.
This was likely exascerbated by a competitive landscape in which their customers (web developers) were unable to judge the veracity of the assertions, and a deference to authority; surely Facebook wouldn't mislead folks?
The need for an edge against Angular and other competitors also likely played a role. It's underappreciated how tenuous the position of frontend and client-side framework teams are within Big Tech companies. The Closure library and compiler that powered Google's most successful web apps (Gmail, Docs, Drive, Sheets, Maps, etc.) was not staffed for most of its history. It was literally a 20% project that the entire company depended on. For the React team to justify headcount within Facebook, public success was likely essential.
Understood in context, I don't entirely excuse the React team for their early errors, but they are understandable. What's not forgivable are the material and willful omissions by Facebook's React team once the evidence of terrible performance began to accumulate. The React team took no responsibility, did not explain the constraints that Facebook applied to their JavaScript-based UIs to make them perform as well as they do — particularly on mobile — and benefited greatly from pervasive misconceptions that continue to cast React is a better light than hard evidence can support. ⇐
Platform Strategy and Its Discontents
This post is an edited and expanded version of a now-mangled Mastodon thread.
Some in the JavaScript community imagine that I harbour an irrational dislike of their tools when, in fact, I want nothing more than to stop thinking about them. Live-and-let-live is excellent guidance, and if it weren't for React et. al.'s predictably ruinous outcomes, the public side of my work wouldn't involve educating about the problems JS-first development has caused.
But that's not what strategy demands, and strategy is my job.1
I've been holding my fire (and the confidences of consulting counterparties) for most of the last decade. Until this year, I only occasionally posted traces documenting the worsening rot. I fear this has only served to make things look better than they are.
Over the past decade, my work helping teams deliver competitive PWAs gave me a front-row seat to a disturbing trend. The rate of failure to deliver usable experiences on phones was increasing over time, despite the eye-watering cost of JS-based stacks teams were reaching for. Worse and costlier is a bad combo, and the opposite of what competing ecosystems did.
Native developers reset hard when moving from desktop to mobile, getting deeply in touch with the new constraints. Sure, developing a codebase multiple times is more expensive than the web's write-once-test-everywhere approach, but at least you got speed for the extra cost.
That's not what web developers did. Contemporary frontend practice pretended that legacy-oriented, desktop-focused tools would perform fine in this new context, without ever checking if they did. When that didn't work, the toxic-positivity crowd blamed the messenger.2
Frontend's tragically timed turn towards JavaScript means the damage isn't limited to the public sector or "bad" developers. Some of the strongest engineers I know find themselves mired in the same quicksand. Today's popular JS-based approaches are simply unsafe at any speed. The rot is now ecosystem-wide, and JS-first culture owns a share of the responsibility.
But why do I care?
Platforms Are Competitions
I want the web to win.
What does that mean? Concretely, folks should be able to accomplish most of their daily tasks on the web. But capability isn't sufficient; for the web to win in practice, users need to turn to the browser for those tasks because it's easier, faster, and more secure.
A reasonable metric of success is time spent as a percentage of time on device.3
But why should we prefer one platform over another when, in theory, they can deliver equivalently good experiences?
As I see it, the web is the only generational software platform that has a reasonable shot at delivering a potent set of benefits to users:
- Fresh
- Frictionless
- Safe by default
- Portable and interoperable
- Gatekeeper-free (no prior restraint on publication)4
- Standards-based, and therefore...
- User-mediated (extensions, browser settings, etc.)
- Open Source compatible
No other successful platform provides all of these, and others that could are too small to matter.
Platforms like Android and Flutter deliver subsets of these properties but capitulate to capture by the host OS agenda, allowing their developers to be taxed through app stores and proprietary API lock-in. Most treat user mediation like a bug to be fixed.
The web's inherent properties have created an ecosystem that is unique in the history of software, both in scope and resilience.
...and We're Losing
So why does this result in intermittent antagonism towards today's JS community?
Because the web is losing, and instead of recognising that we're all in it together, then pitching in to right the ship, the Lemon Vendors have decided that predatory delay and "I've got mine, Jack"-ism is the best response.
What do I mean by "losing"?
Going back to the time spent metric, the web is cleaning up on the desktop. The web's JTBD percentage and fraction of time spent both continue to rise as we add new capabilities to the platform, displacing other ways of writing and delivering software, one fraction of a percent every year.5
The web is desktop's indispensable ecosystem. Who, a decade ago, thought the web would be such a threat to Adobe's native app business that it would need to respond with a $20BN acquisition attempt and a full-fledged version of Photoshop (real Photoshop) on the web?
Model advantages grind slowly but finely. They create space for new competitors to introduce the intrinsic advantages of their platform in previously stable categories. But only when specific criteria are met.
Win Condition
First and foremost, challengers need a cost-competitive channel. That is, users have to be able to acquire software that runs on this new platform without a lot of extra work. The web drops channel costs to nearly zero, assuming...
80/20 capability. Essential use-cases in the domain have to be (reliably) possible for the vast majority (90+%) of the TAM. Some nice-to-haves might not be there, but the model advantage makes up for it. Lastly...
It has to feel good. Performance can't suck for core tasks.6 It's fine for UI consistency with native apps to wander a bit.7 It's even fine for there to be a large peak performance delta. But the gap can't be such a gulf that it generally changes the interaction class of common tasks.
So if the web is meeting all these requirements on desktop – even running away with the lead – why am I saying "the web is losing"?
Because more than 75% of new devices that can run full browsers are phones. And the web is getting destroyed on mobile.
Utterly routed.

This is what I started warning about in 2019, and more recently on this blog. The terrifying data I had access to five years ago is now visible from space.

If that graph looks rough-but-survivable, understand that it's only this high in the US (and other Western markets) because the web was already a success in those geographies when mobile exploded.
That history isn't shared in the most vibrant growth markets, meaning the web has fallen from "minuscule" to "nonexistent" as a part of mobile-first daily life globally.
This is the landscape. The web is extremely likely to get cast in amber and will, in less than a technology generation, become a weird legacy curio.
What happens then? The market for web developers will stop expanding, and the safe, open, interoperable, gatekeeper-free future for computing will be entirely foreclosed — or at least the difficulty will go from "slow build" to "cold-start problem"; several orders of magnitude harder (and therefore unlikely).
This failure has many causes, but they're all tractable. This is why I have worked so hard to close the capability gaps with Service Workers, PWAs, Notifications, Project Fugu, and structural solutions to the governance problems that held back progress. All of these projects have been motivated by the logic of platform competition, and the urgency that comes from understanding that that web doesn't have a natural constituency.8
If you've read any of my writing over this time, it will be unsurprising that this is why I eventually had to break silence and call out what Apple has done on iOS, and what Facebook and Android have done to more quietly undermine browser choice.
These gatekeepers are kneecapping the web in different, but overlapping and reinforcing ways. There's much more to say here, but I've tried to lay out the landscape over the past few years,. But even if we break open the necessary 80/20 capabilities and restart engine competition, today's web is unlikely to succeed on mobile.
You Do It To Yourself, And That's What Really Hurts
Web developers and browsers have capped the web's mobile potential by ensuring it will feel terrible on the phones most folks have. A web that can win is a web that doesn't feel like sludge. And today it does.
This failure has many fathers. Browsers have not done nearly enough to intercede on users' behalf; hell, we don't even warn users that links they tap on might take them to sites that lock up the main thread for seconds at a time!
Things have gotten so bad that even the extremely weak pushback on developer excess that Google's Core Web Vitals effort provides is a slow-motion earthquake. INP, in particular, is forcing even the worst JS-first lemon vendors to retreat to the server — a tacit acknowledgement that their shit stinks.
So this is the strategic logic of why web performance matters in 2024; for the web to survive, it must start to grow on mobile. For that growth to start, we need the web to be a credible way to deliver these sorts of 80/20 capability-enabled mobile experiences with not-trash performance. That depends both on browsers that don't suck (we see you, Apple) and websites that don't consistently lock up phones and drain batteries.
Toolchains and communities that retreat into the numbing comfort of desktop success are a threat to that potential.
There's (much) more for browsers to do here, but developers that want the web to succeed can start without us. Responsible, web-ecology-friendly development is more than possible today, and the great news is that it tends to make companies more money, too!
The JS-industrial-complex culture that pooh-poohs responsibility is self-limiting and a harm to our collective potential.
Groundhog Day
Nobody has ever hired me to work on performance.
It's (still) on my plate because terrible performance is a limiting factor on the web's potential to heal and grow. Spending nearly half my time diagnosing and remediating easily preventable failure is not fun. The teams I sit with are not having fun either, and goodness knows there are APIs I'd much rather be working on instead.
My work today, and for the past 8 years, has only included performance because until it's fixed the whole web is at risk.
It's actually that dire, and the research I publish indicates that we are not on track to cap our JS emissions or mitigate them with CPUs fast enough to prevent ecosystem collapse.
Contra the framework apologists, pervasive, preventable failure to deliver usable mobile experiences is often because we're dragging around IE 9 compat and long toolchains premised on outdated priors like a ball and chain.9
Reboot
Things look bad, and I'd be remiss if I didn't acknowledge that it could just be too late. Apple and Google and Facebook, with the help of a pliant and credulous JavaScript community, might have succeeded where 90s-era Microsoft failed — we just don't know it yet.
But it seems equally likely that the web's advantages are just dormant. When browser competition is finally unlocked, and when web pages aren't bloated with half a megabyte of JavaScript (on average), we can expect a revolution. But we need to prepare for that day and do everything we can to make it possible.
Failure and collapse aren't pre-ordained. We can do better. We can grow the web again. But to do that, the frontend community has to decide that user experience, the web's health, and their own career prospects are more important than whatever JS-based dogma VC-backed SaaS vendors are shilling this month.
FOOTNOTES
My business card says "Product Manager" which is an uncomfortable fudge in the same way "Software Engineer" was an odd fit in my dozen+ years on the Chrome team.
My job on both teams has been somewhat closer to "Platform Strategist for the Web". But nobody hires platform strategists, and when they do, it's to support proprietary platforms. The tactics, habits of mind, and ways of thinking about platform competition for open vs. closed platforms could not be more different. Indeed, I've seen many successful proprietary-platform folks try their hand at open systems and bounce hard off the different constraints, cultures, and "soft power" thinking they require.
Doing strategy on behalf of a collectively-owned, open system is extremely unusual. Getting paid to do it is almost unheard of. And the job itself is strange; because facts about the ecosystem develop slowly, there isn't a great deal to re-derive from current events.
Companies also don't ask strategists to design and implement solutions in the opportunity spaces they identify. But solving problems is the only way to deliver progress, so along with others who do roughly similar work, I have camped out in roles that allow arguments about the health of the web ecosystem to motivate the concrete engineering projects necessary to light the fuse of web growth.
Indeed, nobody asked me to work on web performance, just as nobody asked me to develop PWAs, in the same way that nobody asked me to work on the capability gap between web and native. Each one falls out of the sort of strategy analysis I'm sharing in this post for the first time. These projects are examples of the sort of work I think anyone would do once they understood the stakes and marinated in the same data.
Luckily, inside of browser teams, I've found that largely to be true. Platform work attracts long-term thinkers, and those folks are willing to give strategy analysis a listen. This, in turn, has allowed the formation of large collaborations (like Project Fugu and Project Sidecar to tackle the burning issues that pro-web strategy analysis yields.
Strategy without action isn't worth a damn, and action without strategy can easily misdirect scarce resources. It's a strange and surprising thing to have found a series of teams (and bosses) willing to support an oddball like me that works both sides of the problem space without direction.
So what is it that I do for a living? Whatever working to make the web a success for another generation demands. ⇐
Just how bad is it?
This table shows the mobile Core Web Vitals scores for every production site listed on the Next.js showcase web page as of Oct 2024. It includes every site that gets enough traffic to report mobile-specific data, and ignores sites which no longer use Next.js:10
Mobile Core Web Vitals statistics for Next.js sites from Vercel's showcase, as well as the fraction of mobile traffic to each site. The last column indicates CWV stats (LCP, INP, and CLS) that consistently passed over the past 90 days.
Tap column headers to sort.Site mobile LCP (ms) INP (ms) CLS 90d pass Sonos 70% 3874 205 0.09 1 Nike 75% 3122 285 0.12 0 OpenAI 62% 2164 387 0.00 2 Claude 30% 7237 705 0.08 1 Spotify 28% 3086 417 0.02 1 Nerdwallet 55% 2306 244 0.00 2 Netflix Jobs 42% 2145 147 0.02 3 Zapier 10% 2408 294 0.01 1 Solana 48% 1915 188 0.07 2 Plex 49% 1501 86 0.00 3 Wegmans 58% 2206 122 0.10 3 Wayfair 57% 2663 272 0.00 1 Under Armour 78% 3966 226 0.17 0 Devolver 68% 2053 210 0.00 1 Anthropic 30% 4866 275 0.00 1 Runway 66% 1907 164 0.00 1 Parachute 55% 2064 211 0.03 2 The Washington Post 50% 1428 155 0.01 3 LG 85% 4898 681 0.27 0 Perplexity 44% 3017 558 0.09 1 TikTok 64% 2873 434 0.00 1 Leonardo.ai 60% 3548 736 0.00 1 Hulu 26% 2490 211 0.01 1 Notion 4% 6170 484 0.12 0 Target 56% 2575 233 0.07 1 HBO Max 50% 5735 263 0.05 1 realtor.com 66% 2004 296 0.05 1 AT&T 49% 4235 258 0.18 0 Tencent News 98% 1380 78 0.12 2 IGN 76% 1986 355 0.18 1 Playstation Comp Ctr. 85% 5348 192 0.10 0 Ticketmaster 55% 3878 429 0.01 1 Doordash 38% 3559 477 0.14 0 Audible (Marketing) 21% 2529 137 0.00 1 Typeform 49% 1719 366 0.00 1 United 46% 4566 488 0.22 0 Hilton 53% 4291 401 0.33 0 Nvidia NGC 3% 8398 635 0.00 0 TED 28% 4101 628 0.07 1 Auth0 41% 2215 292 0.00 2 Hostgator 34% 2375 208 0.01 1 TFL "Have your say" 65% 2867 145 0.22 1 Vodafone 80% 5306 484 0.53 0 Product Hunt 48% 2783 305 0.11 1 Invision 23% 2555 187 0.02 1 Western Union 90% 10060 432 0.11 0 Today 77% 2365 211 0.04 2 Lego Kids 64% 3567 324 0.02 1 Staples 35% 3387 263 0.29 0 British Council 37% 3415 199 0.11 1 Vercel 11% 2307 247 0.01 2 TrueCar 69% 2483 396 0.06 1 Hyundai Artlab 63% 4151 162 0.22 1 Porsche 59% 3543 329 0.22 0 elastic 11% 2834 206 0.10 1 Leafly 88% 1958 196 0.03 2 GoPro 54% 3143 162 0.17 1 World Population Review 65% 1492 243 0.10 1 replit 26% 4803 532 0.02 1 Redbull Jobs 53% 1914 201 0.05 2 Marvel 68% 2272 172 0.02 3 Nubank 78% 2386 690 0.00 2 Weedmaps 66% 2960 343 0.15 0 Frontier 82% 2706 160 0.22 1 Deliveroo 60% 2427 381 0.10 2 MUI 4% 1510 358 0.00 2 FRIDAY DIGITAL 90% 1674 217 0.30 1 RealSelf 75% 1990 271 0.04 2 Expo 32% 3778 269 0.01 1 Plotly 8% 2504 245 0.01 1 Sumup 70% 2668 888 0.01 1 Eurostar 56% 2606 885 0.44 0 Eaze 78% 3247 331 0.09 0 Ferrari 65% 5055 310 0.03 1 FTD 61% 1873 295 0.08 1 Gartic.io 77% 2538 394 0.02 1 Framer 16% 8388 222 0.00 1 Open Collective 49% 3944 331 0.00 1 Õhtuleht 80% 1687 136 0.20 2 MovieTickets 76% 3777 169 0.08 2 BANG & OLUFSEN 56% 3641 335 0.08 1 TV Publica 83% 3706 296 0.23 0 styled-components 4% 1875 378 0.00 1 MPR News 78% 1836 126 0.51 2 Me Salva! 41% 2831 272 0.20 1 Suburbia 91% 5365 419 0.31 0 Salesforce LDS 3% 2641 230 0.04 1 Virgin 65% 3396 244 0.12 0 GiveIndia 71% 1995 107 0.00 3 DICE 72% 2262 273 0.00 2 Scale 33% 2258 294 0.00 2 TheHHub 57% 3396 264 0.01 1 A+E 61% 2336 106 0.00 3 Hyper 33% 2818 131 0.00 1 Carbon 12% 2565 560 0.02 1 Sanity 10% 2861 222 0.00 1 Elton John 70% 2518 126 0.00 2 InStitchu 27% 3186 122 0.09 2 Starbucks Reserve 76% 1347 87 0.00 3 Verge Currency 67% 2549 223 0.04 1 FontBase 11% 3120 170 0.02 2 Colorbox 36% 1421 49 0.00 3 NileFM 63% 2869 186 0.36 0 Syntax 40% 2531 129 0.06 2 Frog 24% 4551 138 0.05 2 Inflect 55% 3435 289 0.01 1 Swoosh by Nike 78% 2081 99 0.01 1 Passing % 38% 28% 72% 8% Needless to say, these results are significantly worse than those of responsible JS-centric metaframeworks like Astro or HTML-first systems like Eleventy. Spot-checking their results gives me hope.
Failure doesn't have to be our destiny, we only need to change the way we build and support efforts that can close the capability gap. ⇐
This phrasing — fraction of time spent, rather than absolute time — has the benefit of not being thirsty. It's also tracked by various parties.
The fraction of "Jobs To Be Done" happening on the web would be the natural leading metric, but it's challenging to track. ⇐
Web developers aren't the only ones shooting their future prospects in the foot.
It's bewildering to see today's tech press capitulate to the gatekeepers. The Register and The New Stack stand apart in using above-the-fold column inches to cover just how rancid and self-dealing Apple, Google, and Facebook's suppression of the mobile web has been.
Most can't even summon their opinion bytes to highlight how broken the situation has become, or how the alternative would benefit everyone, even though it would directly benefit those outlets.
If the web has a posse, it doesn't include The Verge or TechCrunch. ⇐
There are rarely KOs in platform competitions, only slow, grinding changes that look "boring" to a tech press that would rather report on social media contratemps.
Even the smartphone revolution, which featured never before seen device sales rates, took most of a decade to overtake desktop as the dominant computing form-factor. ⇐
The web wasn't always competitive with native on desktop, either. It took Ajax (new capabilities), Moore's Law (RIP), and broadband to make it so. There had to be enough overhang in CPUs and network availability to make the performance hit of the web's languages and architecture largely immaterial.
This is why I continue to track the mobile device and network situation. For the mobile web to take off, it'll need to overcome similar hurdles to usability on most devices.
The only way that's likely to happen in the short-to-medium term is for developers to emit less JS per page. And that is not what's happening. ⇐
One common objection to metaplatforms like the web is that the look and feel versus "native" UI is not consistent. The theory goes that consistent affordances create less friction for users as they navigate their digital world. This is a nice theory, but in practice the more important question in the fight between web and native look-and-feel is which one users encounter more often.
The dominant experience is what others are judged against. On today's desktops, browsers that set the pace, leaving OSes with reduced influence. OS purists decry this as an abomination, but it just is what it is. "Fixing" it gains users very little.
This is particularly true in a world where OSes change up large aspects of their design languages every half decade. Even without the web's influence, this leaves a trail of unreconciled experiences sitting side-by-side uncomfortably. Web apps aren't an unholy disaster, just more of the same. ⇐
No matter how much they protest that they love it (sus) and couldn't have succeeded without it (true), the web is, at best, an also-ran in the internal logic of today's tech megacorps. They can do platform strategy, too, and know that that exerting direct control over access to APIs is worth its weight in Californium. As a result, the preferred alternative is always the proprietary (read: directly controlled and therefore taxable) platform of their OS frameworks. API access gatekeeping enables distribution gatekeeping, which becomes a business model chokepoint over time.
Even Google, the sponsor of the projects I pursued to close platform gaps, couldn't summon the organisational fortitude to inconvenience the Play team for the web's benefit. For its part, Apple froze Safari funding and API expansion almost as soon as the App Store took off. Both benefit from a cozy duopoly that forces businesses into the logic of heavily mediated app platforms.
The web isn't suffering on mobile because it isn't good enough in some theoretical sense, it's failing on mobile because the duopolists directly benefit from keeping it in a weakened state. And because the web is a collectively-owned, reach-based platform, neither party has to have their fingerprints on the murder weapon. At current course and speed, the web will die from a lack of competitive vigour, and nobody will be able to point to the single moment when it happened.
That's by design. ⇐
Real teams, doing actual work, aren't nearly as wedded to React vs., e.g., Preact or Lit or FAST or Stencil or Qwik or Svelte as the JS-industrial-complex wants us all to believe. And moving back to the server entirely is even easier.
React is the last of the totalising frameworks. Everyone else is living in the interoperable, plug-and-play future (via Web Components). Escape doesn't hurt, but it can be scary. But teams that want to do better aren't wanting for off-ramps. ⇐
It's hard to overstate just how fair this is to the over-Reactors. The (still) more common Create React App
metaframeworkstarter kit would suffer terribly by comparison, and Vercel has had years of browser, network, and CPU progress to water down the negative consequences of Next.js's blighted architecture.Next has also been pitched since 2018 as "The React Framework for the Mobile Web" and "The React Framework for SEO-Friendly Sites". Nobody else's petard is doing the hoisting; these are the sites that Vercel is chosing to highlight, built using their technology, which has consistently advertised performance-oriented features like code-splitting and SSG support. ⇐
Reckoning: Part 4 — The Way Out
Other posts in the series:
Frontend took ill with a bad case of JavaScript fever at the worst possible moment. The predictable consequence is a web that feels terrible most of the time, resulting in low and falling use of the web on smartphones.1
If nothing changes, eventually, the web will become a footnote in the history of computing; a curio along side mainframes and minicomputers — never truly gone but lingering with an ashen palour and a necrotic odour.
We don't have to wait to see how this drama plays out to understand the very real consequences of JavaScript excess on users.2
Everyone in a site's production chain has agency to prevent disaster. Procurement leads, in-house IT staff, and the managers, PMs, and engineers working for contractors and subcontractors building the SNAP sites we examined all had voices that were more powerful than the users they under-served. Any of them could have acted to steer the ship away from the rocks.
Unacceptable performance is the consequence of a chain of failures to put the user first. Breaking the chain usually requires just one insistent advocate. Disasters like BenefitsCal are not inevitable.
The same failures play out in the commercial teams I sit with day-to-day. Failure is not a foregone conclusion, yet there's an endless queue of sites stuck in the same ditch, looking for help to pull themselves out. JavaScript overindulgence is always an affirmative decision, no matter how hard industry "thought leaders" gaslight us.
Marketing that casts highly volatile, serially failed frontend frameworks as "standard" or required is horse hockey. Nobody can force an entire industry to flop so often it limits its future prospects.
These are choices.
Teams that succeed resolve to stand for the users first, then explore techniques that build confidence.
So, assuming we want to put users first, what approaches can even the odds? There's no silver bullet,3 but some techniques are unreasonably effective.
Managers
Engineering managers, product managers, and tech leads can make small changes to turn the the larger ship dramatically.
First, institute critical-user-journey analysis.
Force peers and customers to agree about what actions users will take, in order, on the site most often. Document those flows end-to-end, then automate testing for them end-to-end in something like WebPageTest.org's scripting system. Then define key metrics around these journeys. Build dashboards to track performance end-to-end.
Next, reform your frontend hiring processes.
Never, ever hire for JavaScript framework skills. Instead, interview and hire only for fundamentals like web standards, accessibility, modern CSS, semantic HTML, and Web Components. This is doubly important if your system uses a framework.
The push-back to this sort of change comes from many quarters, but I can assure you from deep experience that the folks you want to hire can learn anything, so the framework on top of the platform is the least valuable part of any skills conversation. There's also a glut of folks with those talents on the market, and they're vastly underpriced vs. their effectiveness, so "ability to hire" isn't a legitimate concern. Teams that can't find those candidates aren't trying.
Some teams are in such a sorry state regarding fundamentals that they can't even vet candidates on those grounds. If that's your group, don't hestitate to reach out.
In addition to attracting the most capable folks at bargain-basement prices, delivering better work more reliably, and spending less on JavaScript treadmill taxes, publicising these criteria sends signals that will attract more of the right talent over time. Being the place that "does it right" generates compound value. The best developers want to work in teams that prize their deeper knowledge. Demonstrate that respect in your hiring process.
Next, issue every product and engineering leader cheap phones and laptops.
Senior leaders should set the expectation those devices will be used regularly and for real work, including visibly during team meetings. If we do not live as our customers, blind spots metastasise.
Lastly, climb the Performance Management Maturity ladder, starting with latency budgets for every project, based on the previously agreed critical user journeys. They are foundational in building a culture that does not backslide.
Engineers and Designers
Success or failure is in your hands, literally. Others in the equation may have authority, but you have power.
Begin to use that power to make noise. Refuse to go along with plans to build YAJSD (Yet Another JavaScript Disaster). Engineering leaders look to their senior engineers for trusted guidance about what technologies to adopt. When someone inevitably proposes the React rewrite, do not be silent. Do not let the bullshit arguments and nonsense justifications pass unchallenged. Make it clear to engineering leadership that this stuff is expensive and is absolutely not "standard".
Demand bakeoffs and testing on low-end devices.
The best thing about cheap devices is they're cheap! So inexpensive that you can likely afford a low-end phone out-of-pocket, even if the org doesn't issue one. Alternatively, WebPageTest.org can generate high-quality, low-noise simulations and side-by-side comparisons of the low-end situation.
Write these comparisons into testing plans early.
Advocate for metrics and measurements that represent users at the margins.
Teams that have climbed the Performance Management Maturity ladder intuitively look at the highest percentiles to understand system performance. Get comfortable doing the same, and build that muscle in your engineering practice.
Build the infrastructure you'll need to show, rather than tell. This can be dashboards or app-specific instrumentation. Whatever it is, just build it. Nobody in a high-performing engineering organisation will be ungrateful for additional visibility.
Lastly, take side-by-side traces and wave them like a red shirt.
Remember, none of the other people in this equation are working to undercut users, but they rely on you to guide their decisions. Be a class traitor; do the right thing and speak up for users on the margins who can't be in the room where decisions are made.
Public Sector Agencies
If your organisation is unfamiliar with the UK Government Digital Service's excellent Service Manual, get reading.
Once everyone has put their copy down, institute the UK's progressive enhancement standard and make it an enforceable requirement in procurement.4 The cheapest architecture errors to fix are the ones that weren't committed.
Next, build out critical-user-journey maps to help bidders and in-house developers understand system health. Insist on dashboards to monitor those flows.
Use tender processes to send clear signals that proposals which include SPA architectures or heavy JS frameworks (React, Angular, etc.) will face acceptance challenges.
Next, make space in your budget to hire senior technologists and give them oversight power with teeth.
The root cause of many failures is the continuation of too-big-to-fail contracting. The antidote is scrutiny from folks versed in systems, not only requirements. An effective way to build and maintain that skill is to stop writing omnibus contracts in the first place.
Instead, farm out smaller bits of work to smaller shops across shorter timelines. Do the integration work in-house. That will necessitate maintaining enough tech talent to own and operate these systems, building confidence over time.
Reforming procurement is always challenging; old habits run deep. But it's possible to start with the very next RFP.
Values Matter
Today's frontend community is in crisis.
If it doesn't look that way, it's only because the instinct to deny the truth is now fully ingrained. But the crisis is incontrovertable in the data. If the web had grown at the same pace as mobile computing, mobile web browsing would be more than a 1/3 larger than it is today. Many things are holding the web back — Apple springs to mind — but pervasive JavaScript-based performance disasters are doing their fair share.
All of the failures I documented in public sector sites are things I've seen dozens of times in industry. When an e-commerce company loses tens or hundreds of millions of dollars because the new CTO fired the old guard out to make way for a bussload of Reactors, it's just (extremely stupid) business. But the consequences of frontend's accursed turn towards all-JavaScript-all-the-time are not so readily contained. Public sector services that should have known better are falling for the same malarkey.
Frontend's culture has more to answer for than lost profits; we consistently fail users and the companies that pay us to serve them because we've let unscrupulous bastards sell snake oil without consequence.
Consider the alternative.
Canadian engineers graduating college are all given an iron ring. It's a symbol of professional responsibility to society. It also recognises that every discipline must earn its social license to operate. Lastly, it serves as a reminder of the consequences of shoddy work and corner-cutting.

I want to be a part of a frontend culture that accepts and promotes our responsibilities to others, rather than wallowing in self-centred "DX" puffery. In the hierarchy of priorities, users must come first.
What we do in the world matters, particularly our vocations, not because of how it affects us, but because our actions improve or degrade life for others. It's hard to imagine that culture while the JavaScript-industrial-complex has seized the commanding heights, but we should try.
And then we should act, one project at a time, to make that culture a reality.
Thanks to Marco Rogers, and Frances Berriman for their encouragement in making this piece a series and for their thoughtful feedback on drafts.
FOOTNOTES
Users and businesses aren't choosing apps because they love downloading apps. They're choosing them because experiences built with these technologies work as advertised as least as often as they fail.
The same cannot be said for contemporary web development. ⇐
This series is a brief, narrow tour of the consequences of these excesses. Situating these case studies in the US, I hope, can dispel the notion that "the problem" is "over there".
It never was and still isn't. Friends, neighbours, and family all suffer when we do as terrible a job as has now become normalized in the JavaScript-first frontend conversation. ⇐
Silver bullets aren't possible at the technical level, but culturally, giving a toss is always the secret ingreedient. ⇐
Exceptions to a blanket policy requiring a Progressive Enhancement approach to frontend development should be carved out narrowly and only for sub-sections of progressively enhanced primary interfaces.
Specific examples of UIs that might need islands of non-progressively enhanced, JavaScript-based UI include:
- Visualisations, including GIS systems, complex charting, and dashboards.
- Editors (rich text, diagramming tools, image editors, IDEs, etc.).
- Real-time collaboration systems.
- Hardware interfaces to legacy systems.
- Videoconferencing.
In cases where an exception is granted, a process must be defined to characterise and manage latency. ⇐
Reckoning: Part 3 — Caprock
Other posts in the series:
Last time, we looked at how JavaScript-based web development compounded serving errors on US public sector service sites, slowing down access to critical services. These defects are not without injury. The pain of accessing SNAP assistance services in California, Massachusetts, Maryland, Tennessee, New Jersey, and Indiana likely isn't dominated by the shocking performance of their frontends, but their glacial delivery isn't helping.
Waits are a price that developers ask users to pay and loading spinners only buy so much time.
Complexity Perplexity
These SNAP application sites create hurdles to access because the departments procuring them made or green-lit inappropriate architecture choices. In fairness, those choices may have seemed reasonable given JavaScript-based development's capture of the industry.
Betting on JavaScript-based, client-side rendered architectures leads to complex and expensive tools. Judging by the code delivered over the wire, neither CalSAWS nor Deloitte understand those technologies well enough to operate them proficiently.
From long experience and a review of the metrics (pdf) the CalSAWS Joint Management Authority reports, it is plain as day that the level of organisational and cultural sophistication required to deploy a complex JavaScript frontend is missing in Sacramento:
It's safe to assume a version of the same story played out in Annapolis, Nashville, Boston, Trenton, and Indianapolis.
JavaScript-based UIs are fundamentally more challenging to own and operate because the limiting factors on their success are outside the data center and not under the control of procuring teams. The slow, flaky networks and low-end devices that users bring to the party define the envelope of success for client-side rendered UI.
This means that any system that puts JavaScript in the critical path starts at a disadvantage. Not only does JavaScript cost 3x more in processing power, byte-for-byte, than HTML and CSS, but it also removes the browser's ability to parallelise page loading. SPA-oriented stacks also preload much of the functionality needed for future interactions by default. Preventing over-inclusion of ancilliary code generally requires extra effort; work that is not signposted up-front or well-understood in industry.
This, in turn, places hard limits on scalability that arrive much sooner than with HTML-first progressive enhancement.
Consider today's 75-percentile mobile phone1, a device like the Galaxy A50 or the Nokia G100:

This isn't much of a an improvement on the Moto G4 I recommended for testing in 2016, and it's light years from the top-end of the market today.
A device like this presents hard limits on network, RAM, and CPU resources. Because JavaScript is more expensive than HTML and CSS to process, and because SPA architectures frontload script, these devices create a cap on the scalability of SPAs.2 Any feature that needs to be added once the site's bundle reaches the cap is in tension with every other feature in the site until exotic route-based code-splitting tech is deployed.
JavaScript bundles tend to grow without constraint in the development phase and can easily tip into territory that creates an unacceptable experience for users on slow devices.
Only bad choices remain once a project has reached this state. I have worked with dozens of teams surprised to have found themselves in this ditch. They all feel slightly ashamed because they've been led to believe they're the first; that the technology is working fine for other folks.3 Except it isn't.
I can almost recite the initial remediation steps in my sleep.4
The remaining options are bad for compounding reasons:
- Digging into an experience that has been broken with JS inevitably raises a litany of issues that all need unplanned remediation.
- Every new feature on the backlog would add to, rather than subtract from, bundle size. This creates pressure on management as feature work grinds to a halt.
- Removing code from the bundle involves investigating and investing in new tools and deeply learning parts of the tower of JS complexity everyone assumed was "fine".
These problems don't generally arise in HTML-first, progressively-enhanced experiences because costs are lower at every step in the process:
- HTML and CSS are byte-for-byte cheaper for building an equivalent interface.
- "Routing" is handled directly by the browser and the web platform through forms, links, and REST. This removes the need to load code to rebuild it.
- Component definitions can live primarily on the server side, reducing code sent to the client.
- Many approaches to progressive enhancement (rather than "rehydration") use browser-native Web Components, eliminating both initial and incremental costs of larger, legacy-oriented frameworks.
- Because there isn't an assumption that script is critical to the UX, users succeed more often when it isn't there.
This model reduces the initial pressure level and keeps the temperature down by limiting the complexity of each page to what's needed.
Teams remediating underperforming JavaScript-based sites often make big initial gains, but the difficulty ramps up once egregious issues are fixed. The residual challenges highlight the higher structural costs of SPA architectures, and must be wrestled down the hard (read: "expensive") way.
Initial successes also create cognitive dissonance within the team. Engineers and managers armed with experience and evidence will begin to compare themselves to competitors and, eventually, question the architecture they adopted. Teams that embark on this journey can (slowly) become masters of their own destinies.
From the plateau of enlightenment, it's simple to look back and acknowledge that for most sites, the pain, chaos, churn, and cost associated with SPA technology stacks are entirely unnecessary. From that vantage point, a team can finally, firmly set policy.
Carrying Capacity
Organisations that purchase and operate technology all have a base carrying capacity. The cumulative experience, training, and OpEx budgets of teams set the level.
Traditional web development presents a model that many organisations have learned to manage. The incremental costs of additional HTML-based frontends are well understood, from authorisation to database capacity to the intricacies of web servers
SPA-oriented frameworks? Not so much.
In practice, the complex interplay of bundlers, client-side routing mechanisms, GraphQL API endpoints, and the need to rebuild monitoring and logging infrastructure creates wholly unowned areas of endemic complexity. This complexity is experienced as a shock to the operational side of the house.
Before, developers deploying new UIs would cabin the complexity and cost within the data center, enabling mature tools to provide visibility. SPAs and client-side rendered UIs invalidate all of these assumptions. A common result is that the operational complexity of SPA-based technologies creates new, additive points of poorly monitored system failure — failures like the ones we have explored in this series.
This is an industry-wide scandal. Promoters of these technologies have not levelled with their customers. Instead, they continue to flog each new iteration as "the future" despite the widespread failure of these models outside sophisticated organisations.
The pitch for SPA-oriented frameworks like React and Angular has always been contingent — we might deliver better experiences if long chains of interactions can be handled faster on the client.
It's time to acknowledge this isn't what is happening. For most organisations building JavaScript-first, the next dollar spent after launch day is likely go towards recovering basic functionality rather than adding new features.
That's no way to run a railroad.
Should This Be An SPA?
Public and private sector teams I consult with regularly experience ambush-by-JavaScript.
This is the predictable result of buying into frontend framework orthodoxy. That creed hinges on the idea that toweringly complex and expensive stacks of client-side JavaScript are necessary to deliver better user experiences.
But this has always been a contingent claim, at least among folks introspective enough to avoid suggesting JS frameworks for every site. Indeed, most web experiences should explicitly avoid both client-side rendered SPA UI and the component systems built to support them. Nearly all sites would be better off opting for progressive enhancement instead.
Doing otherwise is to invite the complexity fox into the OpEx henhouse. Before you know it, you're fighting with "SSR" and "islands" and "hybrid rendering" and "ISR" to get back to the sorts of results a bit of PHP or Ruby and some CSS deliver for a tenth the price.
So how can teams evaluate the appropriateness of SPAs and SPA-inspired frameworks? By revisiting the arguments offered by the early proponents of these approaches.
The entirety of SPA orthodoxy springs from the logic of the Ajax revolution. As a witness to, and early participant in, that movement, I can conclusively assert that the buzz around GMail and Google Maps and many other "Ajax web apps" was their ability to reduce latency for subsequent interactions once an up-front cost had been paid.
The logic of this trade depends, then, on the length of sessions. As we have discussed before, it's not clear that even GMail clears the bar in all cases.
The utility of the next quanta of script is intensely dependent on session depth.

Very few sites match the criteria for SPA architectures.
Questions managers can use to sort wheat from chaff:
- Does the average session feature more than 20 updates to, or queries against, the same subset of global data?
- Does this UI require features that naturally create long-lived sessions (e.g., chat, videoconferencing, etc.), and are those the site's primary purpose?
- Is there a reason the experience can't be progressively enhanced (e.g., audio mixing, document editing, photo manipulation, video editing, mapping, hardware interaction, or gaming)?
Answering these questions requires understanding critical user journeys. Flows that are most important to a site or project should be written down, and then re-examined through the lens of the marginal networks and devices of the user base.
The rare use-cases that are natural fits for today's JS-first dogma include:
- Document editors of all sorts
- Chat and videoconferencing apps
- Maps, geospatial, and BI visualisations
Very few sites should lead with JS-based, framework-centric development.
Teams can be led astray when sites include mutliple apps under a single umberella. The canonical example is WordPress; a blog reading experience for millions and a blog editing UI for dozens. Treating these as independent experiences with their own constraints and tech stacks is more helpful than pretending that they're actually a "single app". This is also the insight behind the "islands architecture", and transfers well to other contexts, assuming the base costs of an experience remain low.
The Pits
DevTools product managers use the phrase "pit of success" to describe how they hope teams experience their tools. The alternative is the (more common) "pit of ignorance".
The primary benefit of progressive enhancement over SPAs and SPA-begotten frameworks is that they leave teams with simpler problems, closer to the metal. Those challenges require attention and focus on the lived experience, which can be remediated cheaply once identified.
The alternative is considerably worse. In a previous post I claimed that:
SPAs are "YOLO" for web development.
This is because an over-reliance on JavaScript moves responsibility for everything into the main thread in the most expensive way.
Predictably, teams whose next PR adds to JS weight rather than HTML and CSS payloads will find themselves in the drink faster, and with tougher path out.
What's gobsmacking is that so many folks have seen these bets go sideways, yet continue to participate in the pantomime of JavaScript framework conformism. These tools aren't delivering except in the breach, but nobody will say so.
And if we were only lighting the bonuses of overpaid bosses on fire through under-delivery, that might be fine. But the JavaScript-industrial-complex is now hurting families in my community trying to access the help they're entitled to.
It's not OK.
Aftermath
Frontend is mired in a practical and ethical tar pit.
Not only are teams paying unexpectedly large premiums to keep the lights on, a decade of increasing JavaScript complexity hasn't even delivered the better user experiences we were promised.
We are not getting better UX for the escalating capital and operational costs. Instead, the results are getting worse for folks on the margins. JavaScript-driven frontend complexity hasn't just driven out the CSS and semantic-markup experts that used to deliver usable experiences for everyone, it is now a magnifier of inequality.
As previously noted, engineering is designing under constraint to develop products that serve users and society. The opposite of engineering is bullshitting, substituting fairy tales for inquiry and evidence.
For the frontend to earn and keep its stripes as an engineering discipline, frontenders need to internalise the envelope of what's possible on most devices.
Then we must take responsibility.
Next: The Way Out.
Thanks to Marco Rogers, and Frances Berriman for their encouragement in making this piece a series and for their thoughtful feedback on drafts.
FOOTNOTES
3/4 of all devices are faster than this phone, which means 1/4 of phones are slower. Teams doing serious performance work tend to focus on even higher percentiles (P90, P95, etc.).
The Nokia G100 is by no means a hard target. Teams aspiring to excellence should look further down the price and age curves for representative compute power. Phones with 28nm-fabbed A53 cores are still out there in volume. ⇐
One response to the regressive performance of the sites enumerated here is a version of "they're just holding it wrong; everybody knows you should use Server-Side Rendering (SSR) to paint content quickly".
Ignoring the factual inaccuracies undergirding SPA apologetics5, the promised approaches ("SSR + hydration", "concurrent mode", etc.) have not worked.
We can definitively see they haven't worked because the arrival of INP has shocked the body politic. INP has created a disturbance in the JS ecosystem because, for the first time, it sets a price on main-thread excesses backed by real-world data.
Teams that adopt all these techniques are still are not achieving minimally good results. This is likely why "React Server Components" exists; it represents a last-ditch effort to smuggle some of the most costly aspects of the SPA-based tech stack back to the server where it always belonged.
At the risk of tedious repetition, what these INP numbers mean is that these are bad experiences for real users. And these bad experiences can be laid directly at the feet of tools and architectures that promised better experiences.
Putting the lie to SPA theatrics doesn't require inventing a new, more objective value system. The only petard needed to hoist the React ecosystem into the stratosphere is its own sales pitch, which it has miserably and consistently failed to achieve in practice. ⇐
The JavaScript community's omertà regarding the consistent failure of frontend frameworks to deliver reasonable results at acceptable cost is likely to be remembered as one of the most shameful aspects of frontend's lost decade.
Had the risks been prominently signposted, dozens of teams I've worked with personally could have avoided months of painful remediation, and hundreds more sites I've traced could have avoided material revenue losses.
Too many engineering leaders have found their teams beached and unproductive for no reason other than the JavaScript community's dedication to a marketing-over-results ethos of toxic positivity.
Shockingly, cheerleaders for this pattern of failure have not recanted, even when confronted with the consequences. They are not trustworthy. An ethical frontend practice will never arise from this pit of lies and half-truths. New leaders who reject these excesses are needed, and I look forward to supporting their efforts. ⇐
The first steps in remediating JS-based performance disasters are always the same:
- Audit server configurations, including:
- Check caching headers and server compression configurations.
- Enable HTTP/2 (if not already enabled).
- Removing extraneous critical-path connections, e.g. by serving assets from the primary rather than a CDN host.
- Audit the contents of the main bundle and remove unneeded or under-used dependencies.
- Implement code-splitting and dynamic imports.
- Set bundle size budgets and implement CI/CD enforcement.
- Form a group of senior engineers to act as a "latency council".
- Require the group meet regularly to review key performance metrics.
- Charter them to approve all changes that will impact latency.
- Have them institute an actionable "IOU" system for short-term latency regression.
- Require their collective input when drafting or grading OKRs.
- Beg, borrow, or
stealbuy low-end devices for all product managers and follow up to ensure they're using them regularly.
There's always more to explore. SpeedCurve's Performance Guide and WebPageTest.org's free course make good next steps. ⇐
- Audit server configurations, including:
Apologists for SPA architectures tend to trot out arguments with the form "nobody does X any more" or "everybody knows not to do Y" when facing concrete evidence that sites with active maintenance are doing exactly the things they have recently dissavowed, proving instead that not only are wells uncapped, but the oil slicks aren't even boomed.
It has never been true that in-group disfavour fully contains the spread of once-popular techniques. For chrissake, just look at the CSS-in-JS delusion! This anti-pattern appears in a huge fraction of the traces I look at from new projects today, and that fraction has only gone up since FB hipsters (who were warned directly by browser engineers that it was a terrible idea) finally declared it a terrible idea.
Almost none of today's regretted projects carry disclaimers. None of the frameworks that have led to consistent disasters have posted warnings about their appropriate use. Few boosters for these technologies even outline what they had to do to stop the bleeding (and there is always bleeding) after adopting these complex, expensive, and slow architectures.
Instead, teams are supposed to have followed every twist and turn of inscrutable faddism, spending effort to upgrade huge codebases whenever the new hotness changes.
Of course, when you point out that this is what the apologists are saying, no-true-Scotsmanship unfurls like clockwork.
It's irresponsibility theatre.
Consulting with more than a hundred teams over the past eight years has given me ring-side season tickets to the touring production of this play. The first few performances contained frission, some mystery...but now it's all played out. There's no paradox — the lies by omission are fully revealed, and the workmanlike retelling by each new understudy is as charmless as the last.
All that's left is to pen scathing reviews in the hopes that the tour closes for good. ⇐
Reckoning: Part 2 — Object Lesson
Other posts in the series:
The Golden Wait
BenefitsCal is the state of California's recently developed portal for families that need to access SNAP benefits (née "food stamps"):1
Code for America's getcalfresh.org performs substantially the same function, providing a cleaner, faster, and easier-to-use alternative to California county and state benefits applications systems:
The like-for-like, same-state comparison getcalfresh.org provides is unique. Few public sector services in the US have competing interfaces, and only Code for America was motivated to build one for SNAP applications.
WebPageTest.org timelines document a painful progression. Users can begin to interact with getcalfresh.org before the first (of three) BenefitsCal loading screens finish (scroll right to advance):
Google's Core Web Vitals data backs up test bench assessments. Real-world users are having a challenging time accessing the site:

But wait! There's more. It's even worse than it looks.
The multi-loading-screen structure of BenefitsCal fakes out Chrome's heuristic for when to record Largest Contentful Paint.

The real-world experience is significantly worse than public CWV metrics suggest.
Getcalfresh.org uses a simpler, progressively enhanced, HTML-first architecture to deliver the same account and benefits signup process, driving nearly half of all signups for California benefits (per CalSAWS).
The results are night-and-day:2

And this is after the state spent a million dollars on work to achieve "GCF parity".
The Truth Is In The Trace
No failure this complete has a single father. It's easy to enumerate contributing factors from the WebPageTest.org trace, and a summary of the site's composition and caching make for a bracing read:
| Type | First View | Repeat View | |||||
|---|---|---|---|---|---|---|---|
| Wire (KB) | Disk | D:W | Wire | Disk | D:W | Cache | |
| JS | 17,435 | 25,865 | 1.5 | 15,950 | 16,754 | 1.1 | 9% |
| Other | 1,341 | 1,341 | 1.0 | 1,337 | 1,337 | 1.0 | 1% |
| CSS | 908 | 908 | 1.0 | 844 | 844 | 1.0 | 7% |
| Font | 883 | 883 | N/A | 832 | 832 | N/A | 0% |
| Image | 176 | 176 | N/A | 161 | 161 | N/A | 9% |
| HTML | 6 | 7 | 1.1 | 4 | 4 | 1.0 | N/A |
| Total | 20,263 | 29,438 | 1.45 | 18,680 | 19,099 | 1.02 | 7% |
The first problem is that this site relies on 25 megabytes of JavaScript (uncompressed, 17.4 MB on over the wire) and loads all of it before presenting any content to users. This would be unusably slow for many, even if served well. Users on connections worse than the P75 baseline emulated here experience excruciating wait times. This much script also increases the likelihood of tab crashes on low-end devices.3
Very little of this code is actually used on the home page, and loading the home page is presumably the most common thing users of the site do:4
As bad as that is, the wait to interact at all is made substantially worse by inept server configuration. Industry-standard gzip compression generally results in 4:1-8:1 data savings for text resources (HTML, CSS, JavaScript, and "other") depending on file size and contents. That would reduce ~28 megabytes of text, currently served in 19MB of partially compressed resources, to between 3.5MB and 7MB.
But compression is not enabled for most assets, subjecting users to wait for 19MB of content. If CalSAWS built BenefitsCal using progressive enhancement, early HTML and CSS would become interactive while JavaScript filigrees loaded in the background. No such luck for BenefitsCal users on slow connections.

Thanks to the site's React-centric, JavaScript-dependent, client-side rendered, single-page-app (SPA) architecture, nothing is usable until nearly the entire payload is downloaded and run, defeating built-in browser mitigations for slow pages. Had progressive enhancement been employed, even egregious server misconfigurations would have had a muted effect by comparison.5
Zip It
Gzip compression has been industry standard on the web for more than 15 years, and more aggressive algorithms are now available. All popular web servers support compression, and some enable it by default. It's so common that nearly every web performance testing tool checks for it, including Google's PageSpeed Insights.6
Gzip would have reduced the largest script from 2.1MB to a comparatively svelte 340K; a 6.3x compression ratio:
$ gzip -k main.2fcf663c.js
$ ls -l
> total 2.5M
> ... 2.1M Aug 1 17:47 main.2fcf663c.js
> ... 340K Aug 1 17:47 main.2fcf663c.js.gz
Not only does the site require a gobsmacking amount of data on first visit, it taxes users nearly the same amount every time they return.
Because most of the site's payload is static, the fraction cached between first and repeat views should be near 100%. BenefitsCal achieves just 7%.
This isn't just perverse; it's so far out of the norm that I struggled to understand how CalSAWS managed to so thoroughly misconfigure a web server modern enough to support HTTP/2.
The answer? Overlooked turnkey caching options in CloudFront's dashboard.7
This oversight might have been understandable at launch. The mystery remains how it persisted for nearly three years (pdf). The slower the device and network, the more sluggish the site feels. Unlike backend slowness, the effects of ambush-by-JavaScript can remain obscured by the fast phones and computers used by managers and developers.
But even if CalSAWS staff never leave the privilege bubble, there has been plenty of feedback:

'And it's so f'n slow.'
Having placed a bet on client-side rendering, CalSAWS, Gainwell, and Deloitte staff needed to add additional testing and monitoring to assess the site as customers experience it. This obviously did not happen.
The most generous assumption is they were not prepared to manage the downsides of the complex and expensive JavaScript-based architecture they chose over progressive enhancement.89
Near Peers
Analogous sites from other states point the way. For instance, Wisconsin's ACCESS system:
There's a lot that could be improved about WI ACCESS's performance. Fonts are loaded too late, and some of the images are too large. They could benefit from modern formats like WebP or AVIF. JavaScript could be delay-loaded and served from the same origin to reduce connection setup costs. HTTP/2 would left-shift many of the early resources fetched in this trace.

But the experience isn't on fire, listing, and taking on water.

Because the site is built in a progressively enhanced way, simple fixes can cheaply and quickly improve on an acceptable baseline.
Even today's "slow" networks and phones are so fast that sites can commit almost every kind of classic error and still deliver usable experiences. Sites like WI ACCESS would have felt sluggish just 5 years ago but work fine today. It takes extra effort to screw up as badly as BenefitsCal has.
Blimey
To get a sense of what's truly possible, we can compare a similar service from the world leader in accessible, humane digital public services: gov.uk, a.k.a., the UK Government Digital Service (GDS).
California enjoys a larger GDP and a reputation for technology excellence, and yet the UK consistently outperforms the Golden State's public services.
There are layered reasons for the UK's success:
- GDS's Service Manual is an enforceable guide for how government services should be built and delivered continuously. This liberates each department from reinventing processes or rediscovering how best to deliver through trial and error.
- The GDS Service Manual requires progressive-enhancement.
- Progressive Enhancement is baked into infrastructure and practice by patterns long documented in the official GDS design system and reference implementation.
- The parallel Service Standard clearly articulates the egalitarian, open values that every delivery team is held to.
- The Service Manual and Service Standard nearly shout "do not write an omnibus contract!" if you can read between the lines. The interlocking processes, spend controls, and agile activism serve to grind down too-big-to-fail procurement into a fine powder, one contract at a time.10
The BenefitsCal omnishambles should trigger a fundamental rethink. Instead, the prime contractors have just been awarded another $1.3BN over a long time horizon. CalSAWS is now locked in an exclusive arrangement with the very folks that broke the site with JavaScript. Any attempt at fixing it now looks set to reward easily-avoided failure.
Too-big-to-fail procurement isn't just flourishing in California; it's thriving across public benefits application projects nationwide. No matter how badly service delivery is bungled, the money keeps flowing.
JavaScript Masshattery
CalSAWS is by no means alone.
For years, I have been documenting the inequality exacerbating effects of JS-based frontend development based on the parade of private-sector failures that cross my desk.11
Over the past decade, those failures have not elicited a change in tone or behaviour from advocates for frameworks, but that might be starting to change, at least for high-traffic commercial sites.
Core Web Vitals is creating pressure on slow sites that value search engine traffic. It's less clear what effect it will have on public-sector monopsonies. The spread of unsafe-at-any-scale JavaScript frameworks into government is worrying as it's hard to imagine what will dislodge them. There's no comparison shopping for food stamps.12
The Massachusetts Executive Office of Health and Human Services (EOHHS) seems to have fallen for JavaScript marketing hook, line, and sinker.
DTA Connect is the result, a site so slow that it frequently takes me multiple attempts to load it from a Core i7 laptop attached to a gigabit network.
From the sort of device a smartphone-dependent mom might use to access the site? It's lookin' slow.
I took this trace multiple times, as WebPageTest.org kept timing out. It's highly unusual for a site to take this long to load. Even tools explicitly designed to emulate low-end devices and networks needed coaxing to cope.
The underlying problem is by now familiar:

Vexingly, whatever hosting infrastructure Massachusetts uses for this project throttles serving to 750KB/s. This bandwidth restriction combines with server misconfigurations to ensure the site takes forever to load, even on fast machines.13
It's a small mercy that DTA Connect sets caching headers, allowing repeat visits to load in "only" several seconds. Because of the SPA architecture, nothing renders until all the JavaScript gathers its thoughts at the speed of the local CPU.
The slower the device, the longer it takes.14

A page this simple, served entirely from cache, should render in much less than a second on a device like this.15
Maryland Enters The Chat
The correlation between states procuring extremely complex, newfangled JavaScript web apps and fumbling basic web serving is surprisingly high.
Case in point, the residents of Maryland wait seconds on a slow connection for megabytes of uncompressed JavaScript, thanks to the Angular 9-based SPA architecture of myMDTHINK.16
Shockingly, Maryland's myMDTHINK loads its 5.2MB of critical-path JS without gzip.
American legislators like to means test public services. In that spirit, perhaps browsers should decline to load multiple megabytes of JavaScript from developers that feel so well-to-do they can afford to skip zipping content for the benefit of others.
Chattanooga Chug Chug
Tennessee, a state with higher-than-average child poverty, is at least using JavaScript to degrade the accessibility of its public services in unique ways.
Instead of misconfiguring web servers, The Volunteer State uses Angular to synchronously fetch JSON files that define the eventual UI in an onload event handler.


Needless to say, this does not read to the trained eye as competent work.
SNAP? In Jersey? Fuhgeddaboudit
New Jersey's MyNJHelps.gov (yes, that's the actual name) mixes the old-timey slowness of multiple 4.5MB background stock photos with a nu-skool render-blocking Angular SPA payload that's 2.2MB on the wire (15.7MB unzipped), leading to first load times north of 20 seconds.
Despite serving the oversized JavaScript payload relatively well, the script itself is so slow that repeat visits take nearly 13 seconds to display fully:
What Qualcomm giveth, Angular taketh away.

Debugging the pathologies of this specific page are beyond the scope of this post, but it is a mystery how New Jersey managed to deploy an application that triggers a debugger; statement on every page load with DevTools open whilst also serving a 1.8MB (13.8MB unzipped) vendor.js file with no minification of any sort.
One wonders if anyone involved in the deployment of this site are developers, and if not, how it exists.
Hoosier Hospitality
Nearly half of the 15 seconds required to load Indiana's FSSA Benefits Portal is consumed by a mountain of main-thread time burned in its 4.2MB (16MB unzipped) Angular 8 SPA bundle.
Combined with a failure to set appropriate caching headers, both timelines look identically terrible:
Can you spot the difference?


Neither can I.
Entirely defeating browser caching in 2024 takes serious effort, but Indiana has pulled it off.
Deep Breaths
The good news is that not every digital US public benefits portal has been so thoroughly degraded by JavaScript frameworks. Code for America's 2023 Benefits Enrolment Field Guide study helpfully ran numbers on many benefits portals, and a spot check shows that those that looked fine last year are generally in decent shape today.
Still, considering just the states examined in this post, one in five US residents will hit underperforming services, should they need them.
None of these sites need to be user hostile. All of them would be significantly faster if states abandoned client-side rendering, along with the legacy JavaScript frameworks (React, Angular, etc.) built to enable the SPA model.
GetCalFresh, Wisconsin, and the UK demonstrate a better future is possible today. To deliver that better future and make it stick, organisations need to learn the limits of their carrying capacity for complexity. They also need to study how different architectures fail in order to select solutions that degrade more gracefully.
Next: Caprock: Development without constraints isn't engineering.
Thanks to Marco Rogers, and Frances Berriman for their encouragement in making this piece a series and for their thoughtful feedback on drafts.
If you work on a site discussed in this post, I offer (free) consulting to public sector services. Please get in touch.
FOOTNOTES
The JavaScript required to render anything on BenefitsCal embodies nearly every anti-pattern popularised (sometimes inadvertently, but no less predictably) by JavaScript influencers over the past decade, along with the most common pathologies of NPM-based, React-flavoured frontend development.
A perusal of the code reveals:
- Multiple reactive systems, namely React, Vue, and RxJS.
- "Client-side routing" metadata for the entire site bundled into the main script.
- React components for all UI surfaces across the site, including:
- Components for every form, frontloaded. No forms are displayed on the home page.
- An entire rich-text editing library. No rich-text editing occurs on the home page.
- A complete charting library. No charts appear on the home page.
- Sizable custom scrolling and drag-and-drop libraries. No custom scrolling or drag-and-drop interactions occur on the home page.
- A so-called "CSS-in-JS" library that does not support compilation to an external stylesheet. This is categorically the slowest and least efficient way to style web-based UIs. On its own, it would justify remediation work.
- Unnecessary polyfills and transpilation overhead, including:
classsyntax transpilation.- Generator function transpilation and polyfills independently added to dozens of files.
- Iterator transpilation and polyfills.
- Standard library polyfills, including obsolete userland implementations of
ArrayBuffer,Object.assign()and repeated inlining of polyfills for many others, including a litany of outdated TypeScript-generated polyfills, bloating every file. - Obselete DOM polyfills, including a copy of Sizzle to provide emulation for
document.querySelectorAll()and a sizable colourspace conversion system, along with userland easing functions for all animations supported natively by modern CSS.
- No fewer than
2...wait...5...no, 6 large — seemingly different! —User-Agentparsing libraries that support browsers as weird and wonderful as WebOS, Obigo, and iCab. What a delightful and unexpected blast from the past! (pdf) - What appears to be an HTML parser and userland DOM implementation!?!
- A full copy of Underscore.
- A full copy of Lodash.
- A full copy of
core-js. - A userland elliptic-curve cryptography implementation. Part of an on-page chatbot, naturally.
- A full copy of Moment.js. in addition to the custom date and time parsing functions already added via bundling of the (overlarge)
react-date-pickerlibrary. - An unnecessary OAuth library.
- An emulated version of the Node.js
bufferclass, entirely redundant on modern browsers. - The entire Amazon Chime SDK, which includes all the code needed to do videoconferencing. This is loaded in the critical path and alone adds multiple megabytes of JS spread across dozens of webpack-chunked files. No features of the home page appear to trigger videoconferencing.
- A full copy of the AWS JavaScript SDK, weighing 2.6MB, served separately.
- Obviously, nothing this broken would be complete without a Service Worker that only caches image files.
This is, to use the technical term, whack.
The users of BenefitsCal are folks on the margins — often working families — trying to feed, clothe, and find healthcare for kids they want to give a better life. I can think of few groups that would be more poorly served by such baffling product and engineering mismanagement. ⇐ ⇐
getcalfresh.org isn't perfect from a performance standpoint.
The site would feel considerably snappier if the heavy chat widget it embeds were loaded on demand with the facade pattern and if the Google Tag Manager bundle were audited to cut cruft. ⇐
Browser engineers sweat the low end because that's where users are17, and when we do a good job for them, it generally translates into better experiences for everyone else too. One of the most durable lessons of that focus has been that users having a bad time in one dimension are much more likely to be experiencing slowness in others.
Slow networks correlate heavily with older devices that have less RAM, slower disks, and higher taxes from "potentially unwanted software" (PUS). These machines may experience malware fighting with invasive antivirus, slowing disk operations to a crawl. Others may suffer from background tasks for app and OS updates that feel fast on newer machines but which drag on for hours, stealing resources from the user's real work the whole time.
Correlated badness also means that users in these situations benefit from any part of the system using fewer resources. Because browsers are dynamic systems, reduced RAM consumption can make the system faster, both through reduced CPU load from zram, as well as rebalancing in auto-tuning algorithms to optimise for speed rather than space.
The pursuit of excellent experiences at the margins is deep teacher about the systems we program, and a frequently humbling experience. If you want to become a better programmer or product manager, I recommend focusing on those cases. You'll always learn something. ⇐
It's not surprising to see low code coverage percentages on the first load of an SPA. What's shocking is that the developers of BenefitsCal confused it with a site that could benefit from this architecture.
To recap: the bet that SPA-oriented JavaScript frameworks make is that it's possible to deliver better experiences for users when the latency of going to the server can be shortcut by client-side JavaScript.
I cannot stress this enough: the premise of this entire wing of web development practice is that expensive, complex, hard-to-operate, and wicked-to-maintain JavaScript-based UIs lead to better user experiences.
It is more than fair to ask: do they?
In the case of BenefitsCal and DTA Connect, the answer is "no".
The contingent claim of potentially improved UI requires dividing any additional up-front latency by the number of interactions, then subtracting the average improvement-per-interaction from that total. It's almost impossible to imagine any app with sessions long enough to make 30-second up-front waits worthwhile, never mind a benefits application form.
These projects should never have allowed "frontend frameworks" within a mile of their git repos. That they both picked React (a system with a lurid history of congenital failure) is not surprising, but it is dispiriting.
Previous posts here have noted that site structure and critical user journeys largely constrain which architectures make sense:
Sites with short average sessions cannot afford much JS up-front. These portals serve many functions: education, account management, benefits signup, and status checks. None of these functions exhibit the sorts of 50+ interaction sessions of a lived-in document editor (Word, Figma) or email client (Gmail, Outlook). They are not "toothbrush" services that folks go to every day, or which they use over long sessions.
Even the sections that might benefit from additional client-side assistance (rich form validation, e.g.) cannot justify loading all of that code up-front for all users.
The failure to recognise how inappropriate JavaScript-based SPA architectures are for most sites is an industry-wide scandal. In the case of these services, that scandal takes on whole new dimension of reckless irresponsibility. ⇐
JavaScript-based SPAs yank the reins away from the browser while simultaneously frontloading code at the most expensive time.
SPA architectures and the frameworks built to support them put total responsibility for all aspects of site performance squarely on the shoulders of the developer. Site owners who are even occasionally less than omniscient can quickly end up in trouble. It's no wonder many teams I work with are astonished at how quickly these tools lead to disastrous results.
SPAs are "YOLO" for web development.
Their advocates' assumption of developer perfection is reminiscent of C/C++'s approach to memory safety. The predictable consequences should be enough to disqualify them from use in most new work. The sooner these tools and architectures are banned from the public sector, the better. ⇐
Confoundingly, while CalSAWS has not figured out how to enable basic caching and compression, it has rolled out firewall rules that prevent many systems like PageSpeed Insights from evaluating the page through IP blocks.
The same rules also prevent access from IPs geolocated to be outside the US. Perhaps it's also a misconfiguration? Surely CalSAWS isn't trying to cut off access to services for users who are temporarialy visiting family in an emergency, right? ⇐
There's a lot to say about BenefitsCal's CloudFront configuration debacle.
First, and most obviously: WTF, Amazon?
It's great that these options are single-configuration and easy to find when customers go looking for them, but they should not have to go looking for them. The default for egress-oriented projects should be to enable this and then alert on easily detected double-compression attempts.
Second: WTF, Deloitte?
What sort of C-team are you stringing CalSAWS along with? Y'all should be ashamed. And the taxpayers of California should be looking to claw back funds for obscenely poor service.
Lastly: this is on you, CalSAWS.
As the procurer and approver of delivered work items, the failure to maintain a minimum level of in-house technical skill necessary to call BS on vendors is inexcusable.
New and more appropriate metrics for user success should be integrated into public reporting. That conversation could consume an entire blog post; the current reports are little more than vanity metrics. The state should also redirect money it is spending with vendors to enhance in-house skills in building and maintaining these systems directly.
It's an embarrassment that this site is as broken as it was when I began tracing it three years ago. It's a scandal that good money is being tossed after bad. Do better. ⇐
It's more likely that CalSAWS are inept procurers and that Gainwell + Deloitte are hopeless developers.
The alternative requires accepting that one or all of these parties knew better and did not act, undermining the struggling kids and families of California in the process. I can't square that with the idea of going to work every day for years to build and deliver these services. ⇐
In fairness, building great websites doesn't seem to be Deloitte's passion.
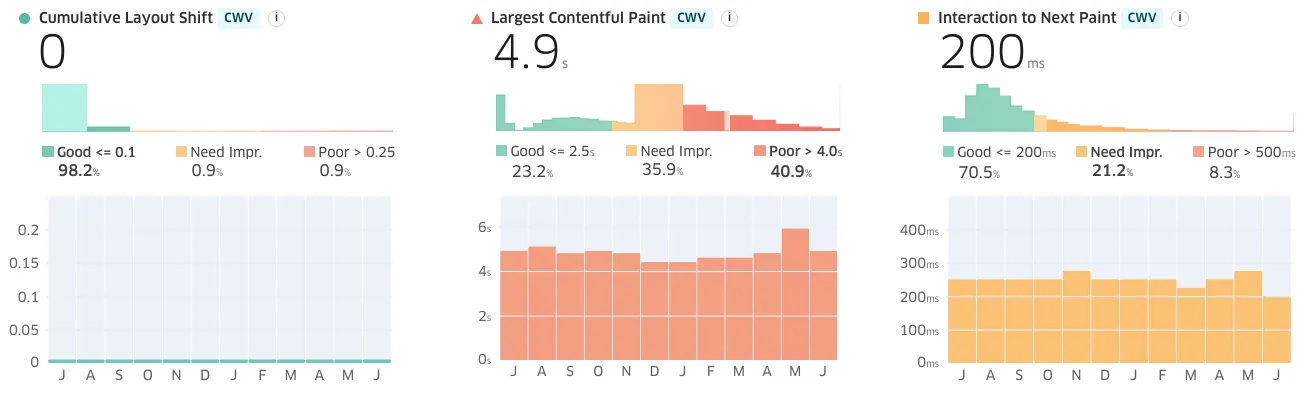
Deloitte.com performs poorly for real-world users, a population that presumably includes a higher percentage of high-end devices than other sites traced in this post. But even Deloitte could have fixed the BenefitsCal mess had CalSAWS demanded better. ⇐
It rankles a bit that what the UK's GDS has put into action for the last decade is only now being recognised in the US.
If US-centric folks need to call these things "products" instead of "services" to make the approach legible, so be it! Better late than never. ⇐
I generally have not not posted traces of the private sector sites I have spent much of the last decade assisting, preferring instead to work quietly to improve their outcomes.
The exception to this rule is the public sector, where I feel deeply cross-pressured about the sort of blow-back that underpaid civil servants may face. However, sunlight is an effective disinfectant, particularly for services we all pay for. The tipping point in choosing to post these traces is that by doing so, we might spark change across the whole culture of frontend development. ⇐
getcalfresh.org is the only direct competitor I know of to a state's public benefits access portal, and today it drives nearly half of all SNAP signups in California. Per BenefitsCal meeting notes (pdf), it is scheduled to be decommissioned next year.
Unless BenefitsCal improves dramatically, the only usable system for SNAP signup in the most populous state will disappear when it goes. ⇐
Capping the effective bandwidth of a server is certainly one way to build solidarity between users on fast and slow devices.
It does not appear to have worked.
The glacial behaviour of the site for all implies managers in EOHHS must surely have experienced DTA Connect's slowness for themselves and declined to do anything about it. ⇐
The content and structure of DTA Connect's JavaScript are just as horrifying as BenefitsCal's1:1 and served just as poorly. Pretty-printed, the main bundle runs to 302,316 lines.
I won't attempt nearly as exhaustive inventory of the #fail it contains, but suffice to say, it's a Create React App special. CRAppy, indeed.
Many obsolete polyfills and libraries are bundled, including (but not limited to):
- A full copy of core-js
- Polyfills for features as widely supported as
fetch() - Transpilation down to ES5, with polyfills to match
- A full userland elliptic-curve cryptography library
- A userland implementation of BigInt
- A copy of zlib.js
- A full copy of the Public Suffix List
- A full list of mime types (thousands of lines).
- What appears to be a relatively large rainbow table.
Seasoned engineers reading this list may break out in hives, and that's an understandable response. None of this is necessary, and none of it is useful in a modern browser. Yet all of it is in the critical path.
Some truly unbelievable bloat is the result of all localized strings for the entire site occurring in the bundle. In every supported language.
Any text ever presented to the user is included in English, Spanish, Portuguese, Chinese, and Vietnamese, adding megabytes to the download.
A careless disregard for users, engineering, and society permeates this artefact. Massachusetts owes citizens better. ⇐
Some junior managers still believe in the myth of the "10x" engineer, but this isn't what folks mean when they talk about "productivity". Or at least I hope it isn't. ⇐
Angular is now on version 18, meaning Maryland faces a huge upgrade lift whenever it next decides to substantially improve myMDTHINK. ⇐
Browsers port to macOS for CEOs, hipster developers, and the tech press. Macs are extremely niche devices owned exclusively by the 1-2%. Its ~5% browsing share is inflated by the 30% not yet online, almost none of whom will be able to afford Macs.
Wealth-related factors also multiply the visibility of high-end devices (like Macs) in summary statistics. These include better networks and faster hardware, both of which correlate with heavier browsing. Relatively high penetration in geographies with strong web use also helps. For example, Macs have 30% share of desktop-class sales in the US, vs 15% worldwide..
The overwhelming predominance of smartphones vs. desktops seals the deal. In 2023, smartphones outsold desktops and laptops by more than 4:1. This means that smartphones outnumber laptops and desktops to an even greater degree worldwide than they do in the US.
Browser makers keep Linux ports ticking over because that's where developers live (including many of their own). It's also critical for the CI/CD systems that power much of the industry.
Those constituencies are vocal and wealthy, giving them outsized influence. But iOS and and macOS aren't real life; Android and Windows are, particularly their low-end, bloatware-filled expressions.
Them's the breaks. ⇐