Reading List
The most recent articles from a list of feeds I subscribe to.
Open sourcing the nginx playground
Hello! In 2021 I released a small playground for testing nginx configurations called nginx playground. There’s a blog post about it here.
This is an extremely short post to say that at the time I didn’t make it open source, but I am making it open source now. It’s not a lot of code but maybe it’ll be interesting to someone, and maybe someone will even build on it to make more playgrounds! I’d love to see an HAProxy playground or something in a similar vein.
Here’s the github repo. The
frontend is in static/ and the backend is in api/. The README is mostly an
extended apology for the developer experience and note that the project is
unmaintained. But I did test that the build instructions work!
why didn’t I open source this before?
I’m not very good at open source. Some of the problems I have with open sourcing things are:
- I dislike (and am very bad at) maintaining open source projects – I usually ignore basically all feature requests and most bug reports and then feel bad about it. I handed off maintainership to both of the open source projects that I started (rbspy and rust-bcc) to other people who are doing a MUCH better job than I ever did.
- Sometimes the developer experience for the project is pretty bad
- Sometimes there’s configuration in the project (like the
fly.tomlor the analytics I have set up) which don’t really make sense for other people to copy
new approach: don’t pretend I’m going to improve it
In the past I’ve had some kind of belief that I’m going to improve the problems with my code later. But I haven’t touched this project in more than a year and I think it’s unlikely I’m going to go back to it unless it breaks in some dramatic way.
So instead of pretending I’m going to improve things, I decided to just:
- tell people in the README that the project is unmaintained
- write down all the security caveats I know about
- test the build instructions I wrote to make sure that they work (on a fresh machine, even!)
- explain (but do not fix!!) some of the messy parts of the project
that’s all!
Maybe I will open source more of my tiny projects in the future, we’ll see! Thanks to Sumana Harihareswara for helping me think through this.
New zine: How Integers and Floats Work
Hello! On Wednesday, we released a new zine: How Integers and Floats Work!
You can get it for $12 here: https://wizardzines.com/zines/integers-floats, or get an 13-pack of all my zines here.
Here’s the cover:

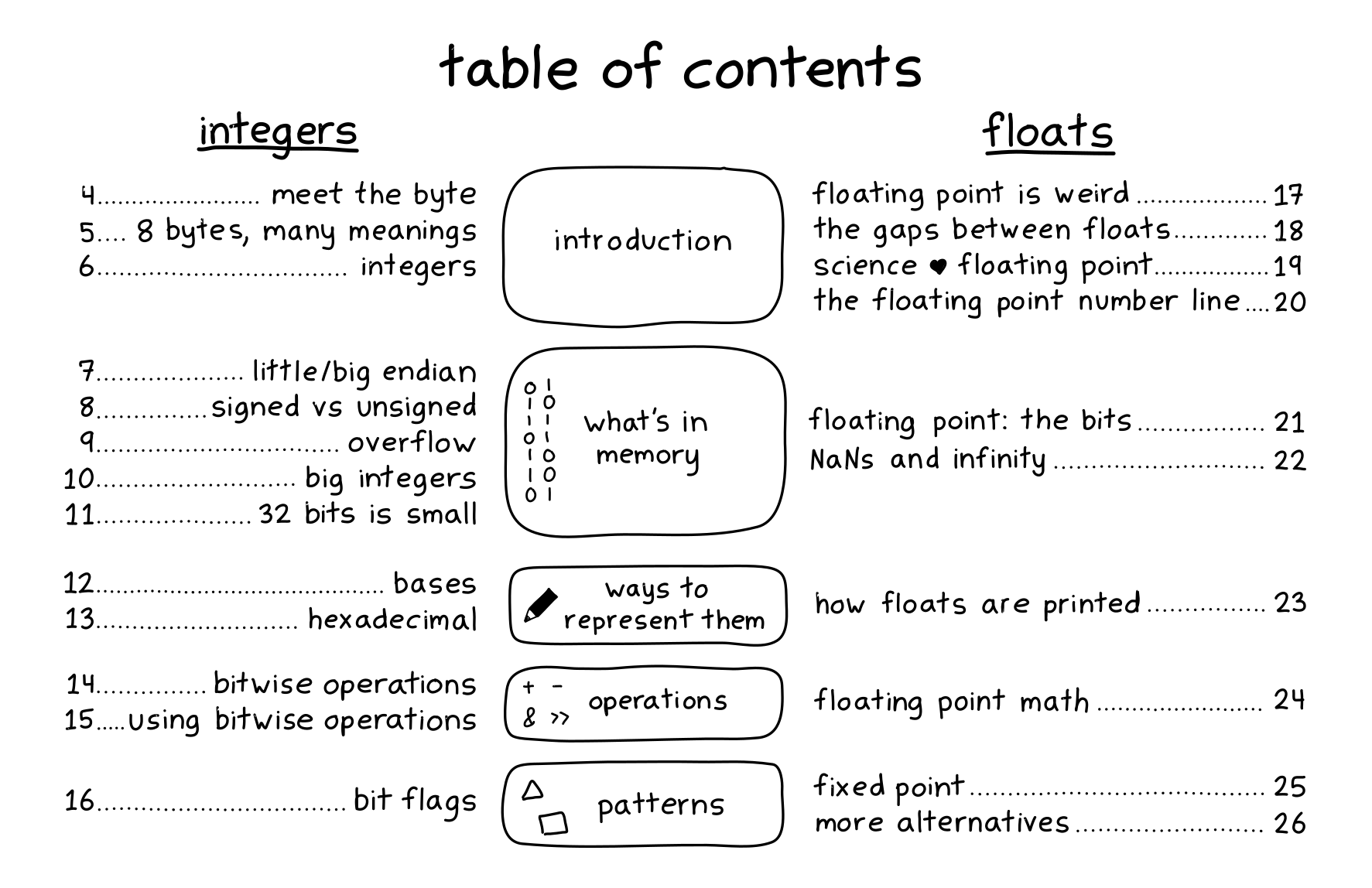
the table of contents
Here’s the table of contents!
Now let’s talk about some of the motivations for writing this zine!
motivation 1: demystify binary
I wrote this zine because I used to find binary data really impenetrable. There are all these 0s and 1s! What does it mean?
But if you look at any binary file format, most of it is integers! For example, if you look at the DNS parsing in Implement DNS in a Weekend, it’s all about encoding and decoding a bunch of integers (plus some ASCII strings, which arguably are also arrays of integers).
So I think that learning how integers work in depth is a really nice way to get started with understanding binary file formats. The zine also talks about some other tricks for encoding binary data into integers with binary operations and bit flags.
motivation 2: explain floating point
The second motivation was to explain floating point. Floating point is pretty weird! (see [examples of floating point problems]() for a very long list)
And almost all explanations of floating point I’ve read have been really math and notation heavy in a way that I find pretty unpleasant and confusing, even though I love math more than most people (I did a pure math degree) and am pretty good at it.
We spent weeks working on a clearer explanation of floating point with minimal math jargon and lots of pictures and I think we got there. Here’s one example page, on the floating point number line:

it comes with a playground: memory spy!
One of my favourite ways to learn about how my computer represents things in memory has been to use a debugger to look at the memory of a real program.
But C debuggers like gdb are pretty hard to use at first! So Marie and I made a playground called Memory Spy. It runs a C debugger behind the scenes, but it provides a much simpler interface – there are a bunch of very simple example C programs, and you can just click on each line to view how the variable on that line is represented in memory.
Here’s a screenshot:

Memory Spy is inspired by Philip Guo’s great Python Tutor.
float.exposed is great
When doing demos and research for this zine, I found myself reaching for float.exposed a lot to show how numbers are encoded in floating point. It’s by Bartosz Ciechanowski, who has tons of other great visualizations on his site.
I loved it so much that I made a clone called integer.exposed for integers (with permission), so that people could look at integers in a similar way.
some blog posts I wrote along the way
Here are a few blog posts I wrote while thinking about how to write this zine:
- examples of floating point problems
- examples of problems with integers
- some possible reasons for 8-bit bytes
you can get a print copy shipped to you!
There’s always been the option to print the zines yourself on your home printer.
But this time there’s a new option too: you can get a print copy shipped to you! (just click on the “print version” link on this page)
The only caveat is print orders will ship in August – I need to wait for orders to come in to get an idea of how many I should print before sending it to the printer.
people who helped with this zine
I don’t make these zines by myself!
I worked with Marie LeBlanc Flanagan every morning for 5 months to clarify explanations and build memory spy.
The cover is by Vladimir Kašiković, Gersande La Flèche did copy editing, Dolly Lanuza did editing, another friend did technical review.
Stefan Karpinski gave a talk 10 years ago at the Recurse Center (I even blogged about it at the time) which was the first explanation of floating point that ever made any sense to me. He also explained how signed integers work to me in a Mastodon post a few months ago, when I was in the middle of writing the zine.
And finally, I want to thank all the beta readers – 60 of you read the zine and left comments about what was confusing, what was working, and ideas for how to make it better. It made the end product so much better.
thank you
As always: if you’ve bought zines in the past, thank you for all your support over the years. I couldn’t do this without you.
Some blogging myths
A few years ago I gave a short talk (slides) about myths that discourage people from blogging. I was chatting with a friend about blogging the other day and it made me want to write up that talk as a blog post.
here are the myths:
- myth: you need to be original
- myth: you need to be an expert
- myth: posts need to be 100% correct
- myth: writing boring posts is bad
- myth: you need to explain every concept
- myth: page views matter
- myth: more material is always better
- myth: everyone should blog
myth: you need to be original
This is probably the one I hear the most often – “Someone has written about this before! Who’s going to care about what I have to say?“.
The main way I think about this personally is:
- identify something I personally have found confusing or interesting
- write about it
The idea is that if I found it confusing, lots of other people probably did too, even though the information might theoretically be out there on the internet somewhere. Just because there is information on the internet, it doesn’t get magically teleported into people’s brains!
I sometimes store up things that I find confusing for many months or years – for example right now I’m confused about some specific details of how Docker networking works on Mac, but I haven’t figured it out enough to be able to write about it. If I ever figure it out to my satisfaction I’ll probably write a blog post.
Sometimes when I write a blog post, someone will link me to a great existing explanation of the thing that I hadn’t seen. I try to think of this as a good thing – it means that I get a new resource that I couldn’t find, and maybe other people find out about it too. Often I’ll update the blog post to link to it.
A couple of other notes about this one:
- technology changes, and the details matter. Maybe the exact details about how to do something have changed in the last 5 years, and there isn’t much written about the situation in 2023!
- personal stories are really valuable. For example I love my friend Mikkel’s Git is my buddy post about how he uses Git. It’s not the same way that I use it, and I like seeing his approach.
a bit more about my love for personal stories
I think the reason I keep writing these blog posts encouraging people to blog is that I love reading people’s personal stories about how they do stuff with computers, and I want more of them. For example, I started using a Mac recently, and I’ve been very annoyed by the lack of tracing tools like strace.
So I would love to read a story about how someone is using tracing tools to debug on their Mac in 2023! I found one from 2016, but I think the situation with system integrity protection has changed since then and the instructions don’t work for me.
That’s just one example, but there are a million other things on computers that I do not know how to do, where I would love to read 1 person’s story of exactly how they did it in 2023.
myth: you need to be an expert
The second myth is that you need to be an expert in the thing you’re writing about. If you’ve been reading this blog, you probably know that I’ve written a lot of “hey, I just learned this!” posts over the years, where I:
- Learn an interesting thing (“hey, I didn’t know how gdb works, that’s cool!”)
- Write a short blog post about what I learned (how does gdb work?)
You actually just need to know 1-2 interesting things that the reader doesn’t. And if you just learned the thing yesterday, it’s certain that lots of other people don’t know it either.
myth: posts need to be 100% correct
I try to my make my posts mostly correct, and I’ve gotten a bit better at that over time.
My main strategy here is to just add qualifiers like “My understanding is..” or “I think..” before statements that I’m not totally sure of. This saves a lot of time fact checking statements that I’m honestly not sure how to fact check most of the time.
Some examples of “I think…s” from my past blog posts:
I think people are replacing “how many golf balls can fit in the Empire State Building” with more concrete [interview] questions about estimating program runtime and space requirements.
I think the most important thing with bridges is to set up the route tables correctly. So far my understanding is that there are 2 route table entries you need to set: …
Etsy uses PHP, which I think means they can’t have long-lived persistent TCP connections
I think the MTU on my local network is 1500 bytes.
I still don’t know if all of those statements are true (is it true that PHP programs can’t have long-lived persistent TCP connections? maybe not!), so the qualifiers are useful. I don’t really know anything about PHP so I don’t have much interest in fact checking that PHP statement – I’m happy to leave it as an “I think” and potentially correct later it if someone tells me it’s wrong.
I do tend to overdo the “I think that…” statements a bit (bad habit!) and sometimes I need to edit them out when actually it’s something I’m 100% sure of.
myth: writing boring posts is bad
The reality of publishing things on the internet is that interesting things get boosted, and boring things get ignored. So people are basically guaranteed to think your posts are much more interesting that they actually are, because they’re more likely to see your interesting posts.
Also it’s hard to guess in advance what people will think is interesting, so I try to not worry too much about predicting that in advance. I really Darius Kazemi’s How I Won The Lottery talk on this topic about how putting things on the internet is like buying lots of lottery tickets, and the best way to “win” is to make a lot of stuff.
myth: you need to explain every concept
It’s common for people writing advanced posts (like “how malloc works”) to try to include very basic definitions for beginners.
The problem is that you end up writing something that feels like it wasn’t written for anyone: beginners will get confused (it’s very hard to bring someone from “I have no idea what memory allocation is” to “in depth notes about the internals of malloc” in a single blog post), and more advanced readers will be bored and put off by the overly basic explanations.
I found that the easiest way to start was to pick one person and write for them.
You can pick a friend, a coworker, or just a past version of yourself. Writing for just 1 person might feel insufficiently general (“what about all the other people??“) but writing that’s easy to understand for 1 person (other than you!) has a good chance of being easy to understand for many other people as well.
writing has gotten harder as I get more experienced
Someone who read this mentioned that they feel like writing has gotten harder as they get more experienced, and I feel the same way.
I think this is because the gap between me and who I’m writing for has gotten a bigger over time, and so it gets a little harder for me to relate to people who know less about the topic. I think on the balance having more experience makes my writing better (I have more perspective!), but it feels harder.
I don’t have any advice to give about this right now. I just want to acknowledge that it’s hard because someone who read a draft of this mentioned it.
myth: page views matter
I’ve looked at page view analytics a lot in my life, and I’ve never really gotten anything out of it. Comments like this one mean a lot more to me:
Hey, @b0rk. Just wanted to let you know that this post really helped me to improve my skill of understanding a complex concept. Thanks! :)
If it helps one person, I figure I’ve won. And probably it helped 10 other people who didn’t say anything too!
myth: more material is always better
I appreciate the work that goes into extremely deep dive blog posts, but honestly they’re not really my thing. I’d rather read something short, learn a couple of new things, and move on.
So that’s how I approach writing as well. I’ll share a couple of interesting things and then leave anything extra for another post. For me this works well because short posts take less time to write.
This one is obviously a personal preference: short posts aren’t “better” either, I just like them more.
But I often see people get tripped up by wanting to include EVERYTHING in their blog post and then never publishing anything and I think it’s worth considering just making the post shorter and publishing it.
some notes on pedantic/annoying comments
Someone who read a draft of this mentioned struggling with comments that are pedantic or annoying or mean or argumentative. That one’s definitely not a myth, I’ve read a lot of comments like that about my work. (as well as a lot more comments where people are being constructive, but those ones aren’t the problem)
A few notes on how I deal with it:
- The “don’t read the comments” advice has never worked for me, for better or for worse. I read all of them.
- I don’t reply to them. Even if they’re wrong. I dislike arguing on the internet and I’m extremely bad at it, so it’s not a good use of my time.
- Sometimes I can learn something new from the comment, and I try to take that as a win, even if the thing is kind of minor or the comment is phrased in a way that I find annoying.
- Sometimes I’ll update the post to fix mistakes.
- I’ve sometimes found it helpful to reinterpret people being mad as people being confused or curious. I wrote a toy DNS resolver once and some of the commenters were upset that I didn’t handle parsing the DNS packet. At the time I thought this was silly (I thought DNS parsing was really straightforward and that it was obvious how to do it) but I realized that maybe the commenters didn’t think it was easy or obvious, and wanted to know how do it. Which makes sense! It’s not obvious! Those comments partly inspired implement DNS in a weekend, which focuses much more heavily on the parsing aspects.
As with everything I don’t think this is the “best” way to deal with pedantic/annoying comments, it’s just what I do.
myth: everyone should blog
I sometimes see advice to the effect of “blogging is great! public speaking is great! everyone should do it! build your Personal Brand!“.
Blogging isn’t for everyone. Tons of amazing developers don’t have blogs or personal websites at all. I write because it’s fun for me and it helps me organize my thoughts.
that’s all for now!
Probably I’ll write another meta post about blogging in a couple of years since apparently that’s what I do :)
Thanks to Ed, Jeff, Brian, Hazem, Zachary, and Miccah for reading a draft of this
New playground: memory spy
Hello! Today we’re releasing a new playground called “memory spy”. It lets you run C programs and see how their variables are represented in memory. It’s designed to be accessible to folks who don’t know C – it comes with bunch of extremely simple example C programs that you can poke at. Here’s the link:
This is a companion to the “how integers and floats work” zine we’ve been working on, so the goal is mostly to look at how number types (integers and floats) are represented.
why spy on memory?
How computers actually represent variables can seem kind of abstract, so I wanted to make it easy for folks to see how a real computer actually represents variables in memory.
why is it useful to look at C?
You might be wondering – I don’t write C! Why should I care how C programs represent variables in memory?
In this playground I’m mostly interested in showing people how integers and floats are represented. And low-level languages generally all represent integers and floats in the same way – a 32-bit unsigned int is going to be the same in C, C++, Rust, Go, Swift, etc. The exact name of the type is different, but the representation is the same.
In higher-level languages like Python it’s a little different, but under the
hood a float in Python contains a C double, so the C representation is
still pretty relevant.
you don’t have to know C
It uses C because C is the language where it’s the most straightforward to map between “the code in your program” and “what’s in your computer’s memory”.
But if you’re not comfortable with C, this playground is still for you! We put together a bunch of example programs where you can run them and look at each variable’s value.
None of the example programs use any fancy features of C – a lot of the code
is extremely simple, like char byte = 'a';. So you should be mostly
able to understand what’s going on even if you don’t know C at all.
how does it work?
Behind the scenes, there’s a server that:
- compiles the program with
clang - runs the program with the C debugger
lldb(using a Python lldb script) - returns a JSON file with the values of the variable on every line, as an array of bytes
Then the frontend formats the array of bytes so you can look at it. The display logic isn’t very fancy – ultimately it’s a pretty thin wrapper around lldb.
some limitations
The two main limitations I can think of right now are:
- there’s no support for loops (it’ll run them, but it’ll only tell you the value of the variable the first time through the loop)
- it only supports defining one variable per line
There are probably more, it’s a very simple project.
the inspiration
Python Tutor by Philip Guo was a huge inspiration. It has a different focus – it also lets you step through programs in a debugger, but it’s more focused on helping the user build a mental model for how variables and control flow work.
what about security?
In general my approach to running arbitrary untrusted code is 20% sandboxing and 80% making sure that it’s an extremely low value attack target so it’s not worth trying to break in.
Programs are terminated after 1 second of runtime, they run in a container with no network access, and the machine they’re running on has no sensitive data on it and a very small CPU.
some notes on the tech stack
The backend is in Go, plus a Python script to script the interactions with lldb. (here’s the source for the lldb script and the source for the Go server right now). I’m using bubblewrap to sandbox lldb.
As always the frontend is using Vue. You can see the frontend source with “view source” if you want.
The main fancy thing that happens on the frontend is that I use tree sitter to figure out which lines of the code have variables defined on them.
some design notes
As usual these days, I built this project with Marie Claire LeBlanc Flanagan. I think the design decision I’m the happiest with is how we handled navigating the program you’re running. Instead of using next/previous arrows to step through the code one line at a time, you can just click on a line to view its variables.
This “click on a line” design wouldn’t make sense in a normal debugger context because usually you have loops and a line might be run more than once. But our focus here isn’t on control flow, and none of the example programs have loops.
The other thing I’m happy with is the decision to use regular links like (<a href="#example=hexadecimal">) for all the navigation. There’s an
onhashchange Javascript event that takes care of making sure we update the
page to match the new URL.
I think there were more design struggles but I forget what they were right now.
that’s all!
Here’s the link again:
Let me know on Twitter or Mastodon if you notice any problems.
Introducing "Implement DNS in a Weekend"
Hello! I’m excited to announce a project I’ve been working on for a long time: a free guide to implementing your own DNS resolver in a weekend.
The whole thing is about 200 lines of Python, including implementing all of the binary DNS parsing from scratch. Here’s the link:
This project is a fun way to learn:
- How to parse a binary network protocol like DNS
- How DNS works behind the scenes (what’s actually happening when you make a DNS query?)
The testers have reported that it takes around 2-4 hours to do in Python.
what’s a DNS resolver?
A DNS resolver is a program that knows how to figure out what the IP address for a domain is. Here’s what the command line interface of the resolver you’ll write looks like:
$ python3 resolve.py example.com
93.184.216.34
implementing DNS gives me an amazing sense of confidence
In Learning DNS in 10 years, I talked about how having implemented a toy version of DNS myself from scratch gives me an unparalleled sense of confidence in my understanding of DNS.
So this guide is my attempt to share that sense of confidence with you all.
Also, if you’ve bought How DNS Works, I think this guide is a nice companion – you can implement your own DNS resolver to solidify your understanding of the concepts in the zine.
it’s a Jupyter notebook
In this guide, I wanted to mix code that you could run with explanations. I struggled to figure out the right format for months, and then I finally thought of using a Jupyter notebook! This meant that I could easily check that all of the code actually ran.
I used Jupyter Book to convert the Jupyter notebooks into a website. It reruns the notebook before converting it to HTML, so I could easily guarantee that all of the code actually runs and outputs what it says that it outputs. I ended up hacking the theme a lot to make it more minimal, as well as doing some terrible things with Beautiful Soup to get a table of contents that shows you the global TOC as well as the page’s local section headings all in one place.
You can also download the Jupyter notebooks and run them on your own computer if you’d like, using the “download the code” button on the homepage.
why Python?
I used Python for this guide instead of a lower-level language like Go or Rust to make it more approachable – when I started learning networking 10 years ago, I didn’t really know any systems languages well, and I found them kind of intimidating. Implementing traceroute using scapy in Python felt much less scary.
You can very easily pack/unpack binary data in Python with struct.pack and
struct.unpack, so Python being a higher-level language doesn’t really cause
any problems.
The idea is that you can either follow the guide in Python (which is the easiest mode), or if you want a bigger challenge, you can translate the code to any language you’d like. (Go? Javascript? Rust? Bash? Lua? Ruby?)
only the standard library
It was important to me to really show how to implement DNS “from scratch”, so
the guide only uses a few very basic standard library modules: struct,
socket, io, random, and dataclasses.
Here’s what we use each module for:
randomis used for generating DNS query IDssocketis used to make a UDP connectionstructis used for converting to/from binary (struct.packandstruct.unpack)dataclassesare used to make serializing / deserializing records a little more ergonomiciois used forBytesIO, which gives us a reader interface which stores a pointer to how much of the packet we’ve read so far. If I were implementing DNS in a language that didn’t have this kind of reader interface, I might implement my own.
it includes some bonus exercises
The toy DNS resolver is obviously missing a bunch of important features, so I’ve added some exercises at the end with examples of features you could add (and bugs you could fix) to make it a little more like a “real” DNS resolver.
This list isn’t particularly exhaustive though, and I’d love to hear other ideas for relatively-easy-to-implement DNS resolver features I’ve missed.
next goal: TLS
I’ve actually written toy implementations of a bunch of other network protocols in Python (ICMP, UDP, TCP, HTTP, and TLS), and I’m hoping to release “Implement TLS in a weekend” at some point.
No promises though – I have another zine to finish writing first (on all the surprising things about how integers and floats work on computers), and a toy TLS implementation is quite a bit more involved than a toy DNS implementation.
thanks to the beta testers
Thanks to everyone (Atticus, Miccah, Enric, Ben, Ben, Maryanne, Adam, Jordan, and anyone else I missed) who tested this guide and reported confusing or missing explanations, mistakes, and typos.
Also a huge thanks to my friend Allison Kaptur who designed the first “Domain Name Saturday” workshop with me at the Recurse Center in 2020.
The name was inspired by Ray Tracing in One Weekend.
here’s the link again
Here’s the link to the guide again if you’d like to try it out: