Reading List
The most recent articles from a list of feeds I subscribe to.
A blog post is a very long and complex search query to find fascinating people and make them route interesting stuff to your inbox
A lovely essay by Henrik Karlsson on writing, blogging, and the power of the internet.
When writing in public, there is a common idea that you should make it accessible. This is a left over from mass media. Words addressed to a large and diverse set of people need to be simple and clear and free of jargon. [â¦]
That is against our purposes here. A blog post is a search query. You write to find your tribe; you write so they will know what kind of fascinating things they should route to your inbox. If you follow common wisdom, you will cut exactly the things that will help you find these people.
How I built customizable themes using CSS custom properties & HSL
I published an article on the Mailcoach blog explaining the setup around customizable themes for newsletter archives.
I relied on CSS custom properties and HSL colors to allow users to customize their newsletter archives without fiddling with too many options.
Colors are often defined in RGB, but RGB is difficult to transform without custom functions. We ask the user to define the primary color in HSL instead. The benefit of HSL is that it’s easy to control a color by tweaking the parameters.
PHP wishlist: Nested properties
Next on my PHP wishlist are nested properties. This idea is less realistic than others, it’s more me thinking out loud. I don’t have a good syntax proposal for this, and I’m not even sure it’s the best solution for my problem. But it’s the best I’ve come up with so far.
When I want a typed object, I need to create a class in a new file, and give it a name. (While technically not required, one class per file is highly recommended to work well with tools and IDEs we have to our disposal.)
It’s too expensive to add types in PHP.
As an example, let’s build a headless CRM. We’ll start with a ContactResource class. A Resource class is a JSON-serializable class that can be used in an API response. It can be created from an entity or model.
class ContactResource extends Resource
{
public function __construct(
public int $id,
public string $name,
public string $email,
) {
}
public static function fromContact(Contact $contact): self
{
return new self(
id: $contact->id,
name: $contact->name,
email: $contact->email,
);
}
}In addition to the contact’s attributes, I want to add a list of related endpoints to exposed through the API. While I could set an associative array, I prefer types because they’re strict, explicit, support IDE autocompletion, and allow tools to process them with reflection.
I’ll create a ContactResourceEndpoints class and file, and add it as a property to ContactResource
// ContactResourceEndpoints.php
class ContactResourceEndpoints
{
public function __construct(
public string $index,
public string $store,
public string $update,
public string $delete,
) {
}
}
// ContactResource.php
class ContactResource extends Resource
{
public function __construct(
public int $id,
public string $name,
public string $email,
public ContactResourceEndpoints $endpoints,
) {
}
public static function fromContact(Contact $contact): self
{
return new self(
id: $contact->id,
name: $contact->name,
email: $contact->email,
endpoints: new ContactResourceEndpoints(
index: action([ContactController::class, 'index']),
store: action([ContactController::class, 'store']),
update: action([ContactController::class, 'update'], $contact->id),
delete: action([ContactController::class, 'delete'], $delete->id),
),
);
}
}Having to maintain another file, in another place, with another name adds a lot of friction. This pushes developers to use less types (by using an assiative array) or worse: create the wrong abstraction (abstract class Endpoints is not a good use of inheritence).
More downsides:
ContactResourceEndpointsisn’t meant to be used anywhere else, so it doesn’t warrant its own name or class.- Looking at the constructor, it’s not clear which properties are in
ContactResource, I need to click through to a deeper class to get all the information. - We could inline the properties on
ContactResource, but besides looking messy it can cause clashes.
In TypeScript, these tradeoffs don’t exist as you can nest objects in your type declarations.
type ContactResource = {
id: string;
name: string;
email: string;
endpoints: {
index: string;
store: string;
update: string;
delete: string;
};
}I’d love to see something similar in PHP.
class ContactResource extends Resource
{
public function __construct(
public int $id,
public string $name,
public string $email,
public $endpoints: (
string $index,
string $store,
string $update,
string $delete,
),
) {
}
public static function fromContact(Contact $contact): self
{
return new self(
id: $contact->id,
name: $contact->name,
email: $contact->email,
endpoints: (
index: action([ContactController::class, 'index']),
store: action([ContactController::class, 'store']),
update: action([ContactController::class, 'update'], $contact->id),
delete: action([ContactController::class, 'delete'], $delete->id),
),
);
}
}Removing the need for another file makes it cheaper to add proper types to your objects. Nested properties are also “anonymous” as they don’t have a name, which restricts them to be reused.
This is not an RFC, and there’s a fair chance this syntax will clash with another PHP feature. But bear with me; this is just an idea I’m throwing on the table. I’d love to hear other viewpoints!
More on my PHP wishlist:
- The pipe operator
- Nested properties
Time is not a synchronization primitive
Programming is so complicated. I know this is an example of the nostalgia paradox in action, but it easily feels like everything has gotten so much more complicated over the course of my career. One of the biggest things that is really complicated is the fact that working with other people is always super complicated.
One of the axioms you end up working with is "assume best intent". This has sometimes been used as a dog-whistle to defend pathological behavior; but really there is a good idea at the core of this: everyone is really trying to do the best that they can given their limited time and energy and it's usually better to start from the position of "the system that allowed this failure to happen is the thing that must be fixed".
However, we work with other people and this can result in things that can troll you on accident. One of the biggest sources of friction is when people end up creating tests that can fail for no reason. To make this even more fun, this will end up breaking people's trust in CI systems. This lack of trust trains people that it's okay for CI to fail because sometimes it's not your fault. This leads to hacks like the flaky attribute on python where it will ignore test failures. Or even worse, it trains people to merge broken code to main because they're trained that sometimes CI just fails but everything is okay.
Today I want to talk about one of the most common ways that I see things fall apart. This has caused tests, production-load-bearing bash scripts, and normal application code to be unresponsive at best and randomly break at worst. It's when people use time as a synchronization mechanism.
Time as an effect

I think that the best way to explain this is to start with a flaky test that I wrote years ago and break it down to explain why things are flaky and what I mean by a "synchronization mechanism". Consider this Go test:
func TestListener(t *testing.T) {
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
go func() {
lis, err := net.Listen("tcp", ":1337")
if err != nil {
t.Error(err)
return
}
defer lis.Close()
for {
select {
case <- ctx.Done():
return
default:
}
conn, err := lis.Accept()
if err != nil {
t.Error(err)
return
}
// do something with conn
}()
time.Sleep(150*time.Millisecond)
conn, err := net.Dial("tcp", "127.0.0.1:1337")
if err != nil {
t.Error(err)
return
}
// do something with conn
}
This code starts a new goroutine that opens a network listener on port 1337 and then waits for it to be active before connecting to it. Most of the time, this will work out okay. However there's a huge problem lurking at the core of this: This test will take a minimum of 150 milliseconds to run no matter what. If the logic of starting a test server is lifted into a helper function then every time you create a test server from any downstream test function, you spend that additional 150 milliseconds.
Additionally, the TCP listener is probably ready near instantly, but also if you run multiple tests in parallel then they'll all fight for that one port and then everything will fail randomly.
This is what I mean by "synchronization primitive". The idea here is that by having the main test goroutine wait for the other one to be ready, we are using the effect of time passing (and the Go runtime scheduling/executing that other goroutine) as a way to make sure that the server is ready for the client to connect. When you are synchronizing the state of two goroutines (the client being ready to connect and the server being ready for connections), you generally want to use something that synchronizes that state, such as a channel or even by eliminating the need to synchronize things at all.
Consider this version of that test:
func TestListener(t *testing.T) {
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
lis, err := net.Listen("tcp", ":0")
if err != nil {
t.Error(err)
return
}
go func() {
defer lis.Close()
for {
select {
case <- ctx.Done():
return
default:
}
conn, err := lis.Accept()
if err != nil {
t.Error(err)
return
}
// do something with conn
}()
conn, err := net.Dial(lis.Addr().Network(), lis.Addr().String())
if err != nil {
t.Error(err)
return
}
// do something with conn
}
Not only have we gotten rid of that time.Sleep call, we also made it support having multiple instances of the server in parallel! This code is ultimately much more robust than the old test ever was and will easily scale for your needs. If your tests took a total of 600 ms to run each, cutting out that one 150 ms sleep removes 25% of the wait!


Putting it into practice
So let's put this into practice and make this kind of behavior more
difficult to cause. Let's add a roadblock for trying to use
time.Sleep in tests by using the nosleep linter. nosleep is a Go
linter that checks for the presence of time.Sleep in your test code
and fails your code if it finds it. That's it. That's the whole tool.
You can run it against your Go code by installing it with go install:
go install within.website/x/linters/cmd/nosleep@latest
And then you can run it with the nosleep command:
nosleep ./...
I do recognize that sometimes you actually do need to use time as a
synchronization method because god is dead and you have no other
option. If this does genuinely happen, you can use the magic command
//nosleep:bypass here's a very good reason. If you don't put a
reason there, the magic comment won't work.
Let me know how it works for you! Add it to your CI config if you dare.
New zine: How Integers and Floats Work
Hello! On Wednesday, we released a new zine: How Integers and Floats Work!
You can get it for $12 here: https://wizardzines.com/zines/integers-floats, or get an 13-pack of all my zines here.
Here’s the cover:

the table of contents
Here’s the table of contents!
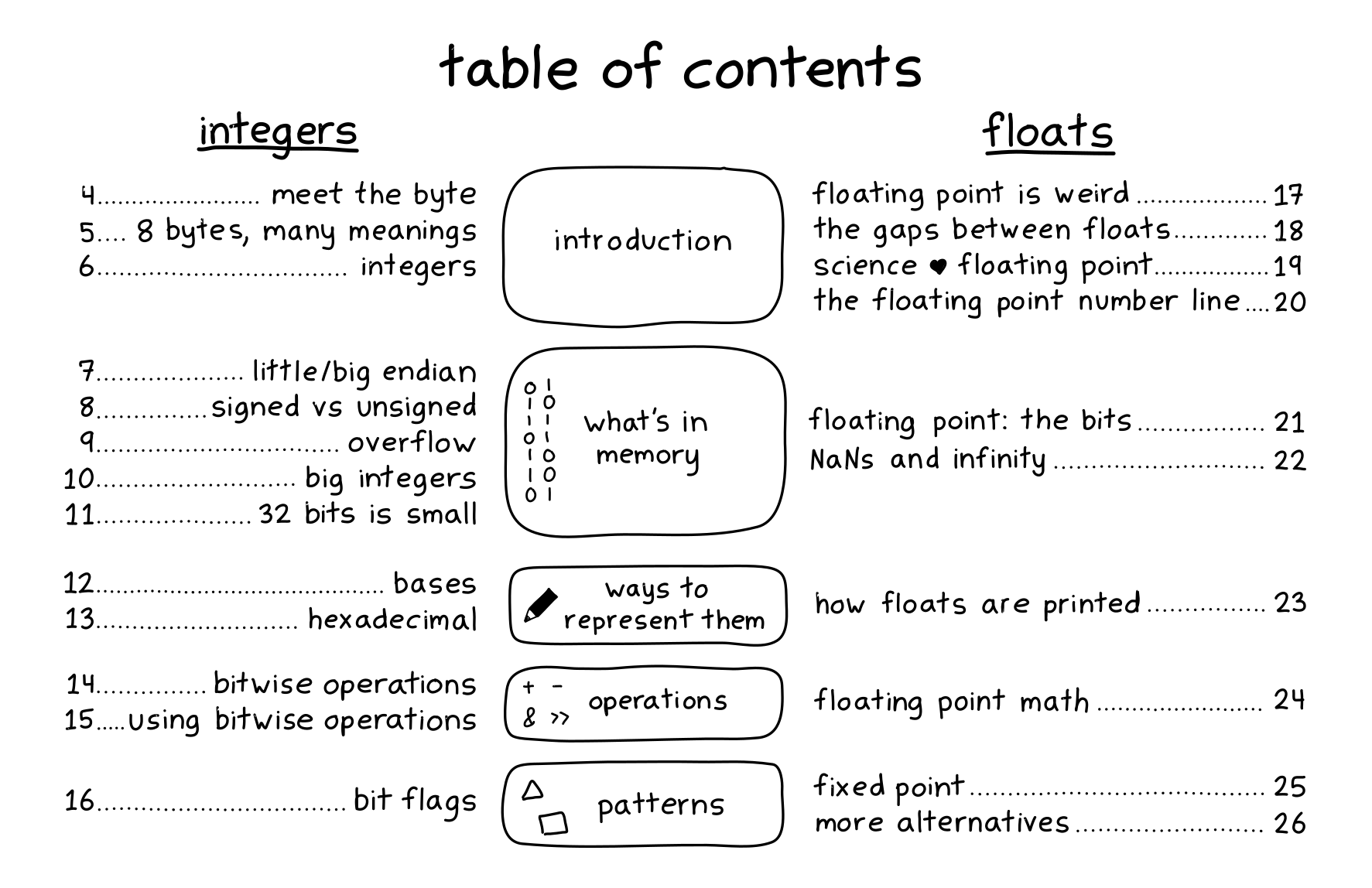
Now let’s talk about some of the motivations for writing this zine!
motivation 1: demystify binary
I wrote this zine because I used to find binary data really impenetrable. There are all these 0s and 1s! What does it mean?
But if you look at any binary file format, most of it is integers! For example, if you look at the DNS parsing in Implement DNS in a Weekend, it’s all about encoding and decoding a bunch of integers (plus some ASCII strings, which arguably are also arrays of integers).
So I think that learning how integers work in depth is a really nice way to get started with understanding binary file formats. The zine also talks about some other tricks for encoding binary data into integers with binary operations and bit flags.
motivation 2: explain floating point
The second motivation was to explain floating point. Floating point is pretty weird! (see [examples of floating point problems]() for a very long list)
And almost all explanations of floating point I’ve read have been really math and notation heavy in a way that I find pretty unpleasant and confusing, even though I love math more than most people (I did a pure math degree) and am pretty good at it.
We spent weeks working on a clearer explanation of floating point with minimal math jargon and lots of pictures and I think we got there. Here’s one example page, on the floating point number line:

it comes with a playground: memory spy!
One of my favourite ways to learn about how my computer represents things in memory has been to use a debugger to look at the memory of a real program.
But C debuggers like gdb are pretty hard to use at first! So Marie and I made a playground called Memory Spy. It runs a C debugger behind the scenes, but it provides a much simpler interface – there are a bunch of very simple example C programs, and you can just click on each line to view how the variable on that line is represented in memory.
Here’s a screenshot:

Memory Spy is inspired by Philip Guo’s great Python Tutor.
float.exposed is great
When doing demos and research for this zine, I found myself reaching for float.exposed a lot to show how numbers are encoded in floating point. It’s by Bartosz Ciechanowski, who has tons of other great visualizations on his site.
I loved it so much that I made a clone called integer.exposed for integers (with permission), so that people could look at integers in a similar way.
some blog posts I wrote along the way
Here are a few blog posts I wrote while thinking about how to write this zine:
- examples of floating point problems
- examples of problems with integers
- some possible reasons for 8-bit bytes
you can get a print copy shipped to you!
There’s always been the option to print the zines yourself on your home printer.
But this time there’s a new option too: you can get a print copy shipped to you! (just click on the “print version” link on this page)
The only caveat is print orders will ship in August – I need to wait for orders to come in to get an idea of how many I should print before sending it to the printer.
people who helped with this zine
I don’t make these zines by myself!
I worked with Marie LeBlanc Flanagan every morning for 5 months to clarify explanations and build memory spy.
The cover is by Vladimir Kašiković, Gersande La Flèche did copy editing, Dolly Lanuza did editing, another friend did technical review.
Stefan Karpinski gave a talk 10 years ago at the Recurse Center (I even blogged about it at the time) which was the first explanation of floating point that ever made any sense to me. He also explained how signed integers work to me in a Mastodon post a few months ago, when I was in the middle of writing the zine.
And finally, I want to thank all the beta readers – 60 of you read the zine and left comments about what was confusing, what was working, and ideas for how to make it better. It made the end product so much better.
thank you
As always: if you’ve bought zines in the past, thank you for all your support over the years. I couldn’t do this without you.