Reading List
How accessibility trees inform assistive tech from hiddedevries.nl Blog RSS feed.
How accessibility trees inform assistive tech
The web is accessible by default. It was designed with features to make accessibility possible, and these have been part of the platform pretty much from the beginning. In recent times, inspectable accessibility trees have made it easier to see how things work in practice. In this post we’ll look at how “good” client-side code (HTML, CSS and JavaScript) improves the experience of users of assistive technologies, and how we can use accessibility trees to help verify our work on the user experience.
People browse differently
Assistive Technology (AT) is the umbrella term for tools that help people operate a computer in the way that suits them. Braille displays, for instance, let blind users understand what’s on their screen by conveying that information in braille format in real time. VoiceOver, a utility for Mac and iOS, converts text into speech, so that people can listen to an interface. Dragon NaturallySpeaking is a tool that lets people operate an interface by talking into a microphone.
 A refreshable Braille display (Photo: Sebastien.delorme)
A refreshable Braille display (Photo: Sebastien.delorme)
The idea that people can use the web in the way that works best for them is a fundamental design principle of the platform. When the web was invented to let scientists exchange documents, those scientists already had a wide variety of systems. Now, in 2019, systems vary even more. We use browsers on everything from watches to phones, tablets to TVs. There is a perennial need for web pages that are resilient and allow for user choice. These values of resilience and flexibility have always been core to our work.
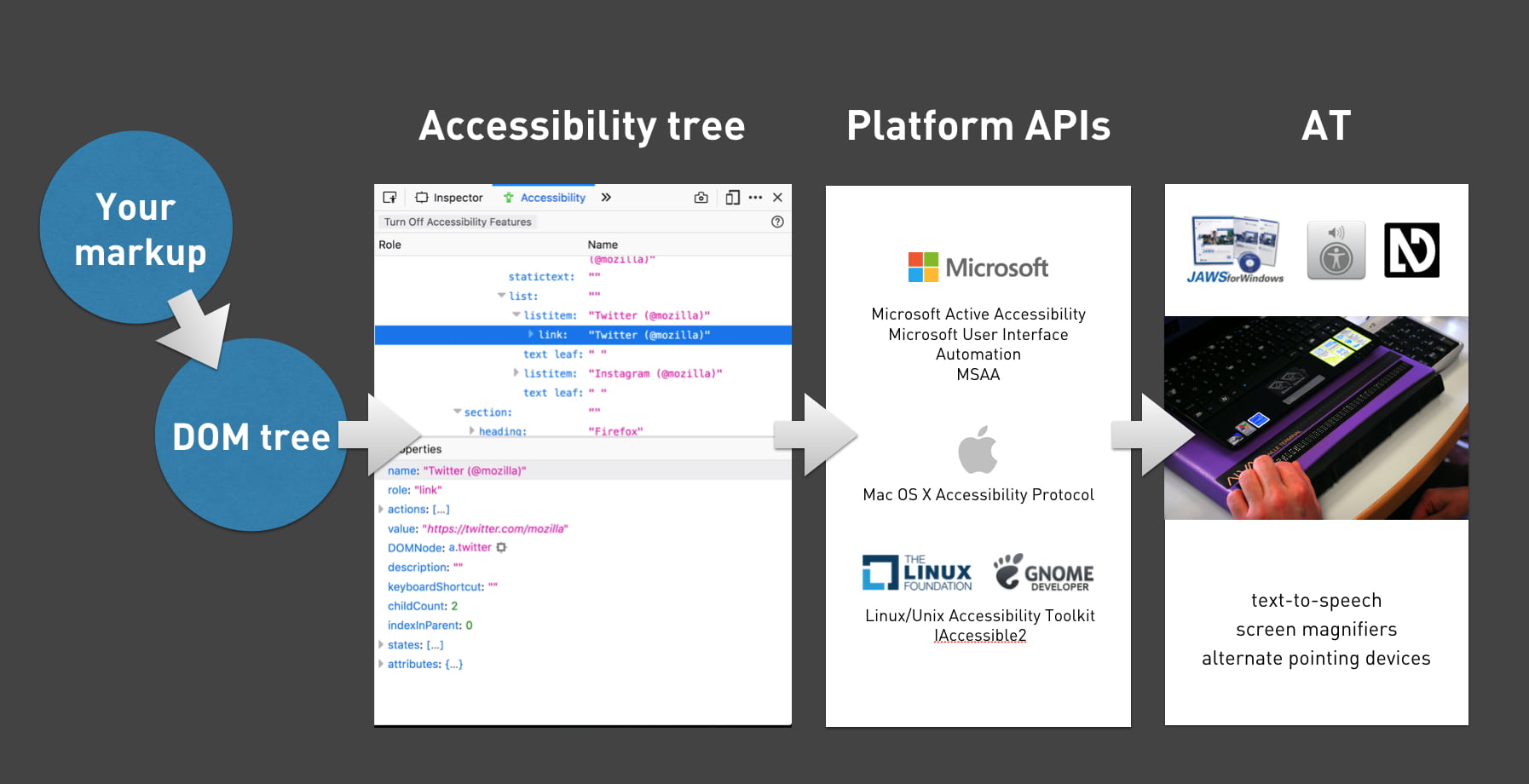
AT draws on these fundamentals. Most assistive technologies need to know what happens on a user’s screen. They all must understand the user interface, so that they can convey it to the user in a way that makes sense. Many years ago, assistive technologies relied on OCR (optical character recognition) techniques to figure what was on the screen. Later they consumed markup directly from the browser. On modern operating systems the software is more advanced: accessibility APIs that are built into the platform provide guidance.
How front-end code helps
Platform-specific Accessibility APIs are slightly different depending on the platform. Generally, they know about the things that are platform-specific: the Start Menu in Windows, the Dock on the Mac, the Favorites menu in Firefox… even the address bar in Firefox. But when we use the address bar to access a website, the screen displays information that it probably has never displayed before, let alone for AT users. How can Accessibility APIs tell AT about information on websites? Well, this is where the right client-side HTML, CSS and JavaScript can help.
Whether we write plain HTML, JSX or Jinja, when someone accesses our site, the browser ultimately receives markup as the start for any interface. It turns that markup into an internal representation, called the DOM tree. The DOM tree contains objects for everything we had in our markup. In some cases, browsers also create an accessibility tree, based on the DOM tree, as a tool to better understand the needs and experiences of assistive technology users. The accessibility tree informs platform-specific Accessibility APIs, which then inform Assistive Technologies. So ultimately, our client-side code impacts the experience of assistive technology users.
HTML
With HTML, we can be specific about what things are in the page. We can define what’s what, or, in technical terms, provide semantics. For example, we can define something as a:
- checkbox or a radio button
- table of structured data
- list, ordered or unordered, or a list of definitions
- navigation or a footer area
CSS
Stylesheets can also impact the accessibility tree: layout and visibility of elements are sometimes taken into account. Elements that are set to display: none or visibility: hidden are taken out of the accessibility tree completely. Setting display to table/table-cell can also impact semantics, as Adrian Roselli explains in Tables, CSS display properties and ARIA.
If your site dynamically changes generated content in CSS (::before and ::after), this can also appear or disappear in accessibility trees.
And then, there are properties that can make visual layout differ from DOM order, for example order in grid and flex items, and auto-flow: dense in Grid Layout. When visual order is different from DOM order, it is likely also going to be different from accessibility tree order. This may confuse AT users. The Flexbox spec is quite clear: the CSS order property is “for visual, not logical reordering”.
JavaScript
JavaScript lets us change the state of our components. This is often relevant for accessibility, for instance, we can determine:
- Is the menu expanded or collapsed?
- Was the checkbox checked or not?
- Is the email address field valid or invalid?
Note that accessibility tree implementations can vary, creating discrepancies between browsers. For instance, missing values are computed to null in some browsers, '' (empty string) in others. Differing implementations are one of many reasons plans to develop a standard are in the works.
What’s in an accessibility tree?
Accessibility trees contain accessibility-related meta information for most of our HTML elements. The elements involved determine what that means, so we’ll look at some examples.
Generally, there are four things in an accessibility tree object:
- name: how can we refer to this thing? For instance, a link with the text ‘Read more’ will have ‘Read more’ as its name (more on how names are computed in the Accessible Name and Description Computation spec)
- description: how do we describe this element, if we want to add anything to the name? The description of a table could explain what kind of info that table offers.
- role: what kind of thing is it? For example, is it a button, a nav bar or a list of items?
- state: if any, does it have state? Think checked/unchecked for checkboxes, or collapsed/expanded for the
<summary>element
Additionally, the accessibility tree often contains information on what can be done with an element: a link can be followed, a text input can be typed into, that kind of thing.
Inspecting the accessibility tree in Firefox
All major browsers provide ways to inspect the accessibility tree, so that we can figure out what an element’s name has computed to, or what role it has, according to the browser. For some context on how this works in Firefox, see Introducing the Accessibility Inspector in the Firefox Developer Tools by Marco Zehe.
Here’s how it works in Firefox:
- In Settings, under Default Developer Tools, ensure that the checkbox “Accessibility” is checked
- You should now see the Accessibility tab
- In the Accessibility tab, you’ll find the accessibility tree with all its objects
Other browsers
In Chrome, the Accessibility Tree information lives together with the DOM inspector and can be found under the ‘Accessibility’ tab. In Safari, it is in the Node tab in the panel next to the DOM tree, together with DOM properties.
An example
Let’s say we have a form where people can pick their favourite fruit:
<form action="">
<fieldset>
<legend>Pick a fruit </legend>
<label><input type="radio" name="fruit"> Apple</label>
<label><input type="radio" name="fruit"> Orange</label>
<label><input type="radio" name="fruit"> Banana</label>
</fieldset>
</form>In Firefox, this creates a number of objects, including:
- An object with a role of grouping, named Pick a fruit
- Three objects with roles of label, named Apple, Orange and Banana, with action Click, and these states: selectable text, opaque, enabled, sensitive
- An object with role of radiobutton, named Apple, with action of Select and these states: focusable, checkable, opaque, enabled, sensitive
And so on. When we select ‘Apple’, checked is added to its list of states.
Note that each thing expressed in the markup gets reflected in a useful way. Because we added a legend to the group of radio buttons, it is exposed with a name of ‘Pick a fruit’. Because we used inputs with a type of radio, they are exposed as such and have relevant states.
As mentioned earlier, we don’t just influence this through markup. CSS and JavaScript can also affect it.
With the following CSS, we would effectively take the name out of the accessibility tree, leaving the fieldset unnamed:
legend { display: none; /* removes item from accessibility tree */ }This is true in at least some browsers. When I tried it in Firefox, its heuristics still managed to compute the name to ‘Pick a fruit’, in Chrome and Safari it was left out completely. What this means, in terms of real humans: they would have no information as to what to do with Apple, Orange and Banana.
As mentioned earlier, we can also influence the accessibility tree with JavaScript. Here is one example:
const inputApple = document.querySelector('input[radio]');
inputApple.checked = true; // alters state of this input, also in accessibility treeAnything you do to manipulate DOM elements, directly through DOM scripting or with your framework of choice, will update the accessibility tree.
Conclusion
To provide a great experience to users, assistive technologies present our web pages differently from how we may have intended them. Yet, what they present is based directly on the content and semantic structure that we provide. As designers and developers, we can ensure that assistive technologies understand our pages well writing good HTML, CSS and JavaScript. Inspectable accessibility trees help us verify directly in the browser if our names, roles and state make sense.
Originally posted as How accessibility trees inform assistive tech on Hidde's blog.