Reading List
The most recent articles from a list of feeds I subscribe to.
On compliance vs readability: Generating text colors with CSS
Can we emulate the upcoming CSS contrast-color() function via CSS features that have already widely shipped?
And if so, what are the tradeoffs involved and how to best balance them?
Relative Colors
Out of all the CSS features I have designed, Relative Colors aka Relative Color Syntax (RCS) is definitely among the ones I’m most proud of. In a nutshell, they allow CSS authors to derive a new color from an existing color value by doing arbitrary math on color components in any supported color space:
--color-lighter: hsl(from var(--color) h s calc(l * 1.2));
--color-lighterer: oklch(from var(--color) calc(l + 0.2) c h);
--color-alpha-50: oklab(from var(--color) l a b / 50%);
The elevator pitch was that by allowing lower level operations they provide authors flexibility on how to derive color variations, giving us more time to figure out what the appropriate higher level primitives should be.
As of May 2024, RCS has shipped in every browser except Firefox. but given that it is an Interop 2024 focus area, that Firefox has expressed a positive standards position, and that the Bugzilla issue has had some recent activity and has been assigned, I am optimistic it would ship in Firefox soon (edit: it shipped 5 days after writing these lines, in Firefox 128 🎉). My guess it that it would become Baseline by the end of 2024.
Even if my prediction is off, it already is available to 83% of users worldwide,
and if you sort its caniuse page by usage,
you will see the vast majority of the remaining 17% doesn’t come from Firefox,
but from older Chrome and Safari versions.
I think its current market share warrants production use today,
as long as we use @supports to make sure things work in non-supporting browsers, even if less pretty.
Most Relative Colors tutorials revolve around its primary driving use cases: making tints and shades or other color variations by tweaking a specific color component up or down, and/or overriding a color component with a fixed value, like the example above. While this does address some very common pain points, it is merely scratching the surface of what RCS enables. This article explores a more advanced use case, with the hope that it will spark more creative uses of RCS in the wild.
The CSS contrast-color() function
One of the big longstanding CSS pain points is that it’s impossible to automatically specify a text color that is guaranteed to be readable on arbitrary backgrounds, e.g. white on darker colors and black on lighter ones.
Why would one need that? The primary use case is when colors are outside the CSS author’s control. This includes:
- User-defined colors. An example you’re likely familiar with: GitHub labels. Think of how you select an arbitrary color when creating a label and GitHub automatically picks the text color — often poorly (we’ll see why in a bit)
- Colors defined by another developer. E.g. you’re writing a web component that supports certain CSS variables for styling. You could require separate variables for the text and background, but that reduces the usability of your web component by making it more of a hassle to use. Wouldn’t it be great if it could just use a sensible default, that you can, but rarely need to override?
- Colors defined by an external design system, like Open Props, Material Design, or even (gasp) Tailwind.

Even in a codebase where every line of CSS code is controlled by a single author, reducing couplings can improve modularity and facilitate code reuse.
The good news is that this is not going to be a pain point for much longer.
The CSS function contrast-color() was designed to address exactly that.
This is not new, you may have heard of it as color-contrast() before, an earlier name.
I recently drove consensus to scope it down to an MVP that addresses the most prominent pain points and can actually ship soonish,
as it circumvents some very difficult design decisions that had caused the full-blown feature to stall.
I then added it to the spec per WG resolution, though some details still need to be ironed out.
Usage will look like this:
background: var(--color);
color: contrast-color(var(--color));
Glorious, isn’t it? Of course, soonish in spec years is still, well, years. As a data point, you can see in my past spec work that with a bit of luck (and browser interest), it can take as little as 2 years to get a feature shipped across all major browsers after it’s been specced. When the standards work is also well-funded, there have even been cases where a feature went from conception to baseline in 2 years, with Cascade Layers being the poster child for this: proposal by Miriam in Oct 2019, shipped in every major browser by Mar 2022. But 2 years is still a long time (and there are no guarantees it won’t be longer). What is our recourse until then?
As you may have guessed from the title, the answer is yes.
It may not be pretty, but there is a way to emulate contrast-color() (or something close to it) using Relative Colors.
Using RCS to automatically compute a contrasting text color
In the following we will use the OKLCh color space, which is the most perceptually uniform polar color space that CSS supports.
Let’s assume there is a Lightness value above which black text is guaranteed to be readable regardless of the chroma and hue, and below which white text is guaranteed to be readable. We will validate that assumption later, but for now let’s take it for granted. In the rest of this article, we’ll call that value the threshold and represent it as Lthreshold.
We will compute this value more rigously in the next section (and prove that it actually exists!),
but for now let’s use 0.7 (70%).
We can assign it to a variable to make it easier to tweak:
--l-threshold: 0.7;
Let’s work backwards from the desired result. We want to come up with an expression that is composed of widely supported CSS math functions, and will return 1 if L ≤ Lthreshold and 0 otherwise. If we could write such an expression, we could then use that value as the lightness of a new color:
--l: /* ??? */;
color: oklch(var(--l) 0 0);
How could we simplify the task?
One way is to relax what our expression needs to return.
We don’t actually need an exact 0 or 1
If we can manage to find an expression that will give us 0 when L > Lthreshold
and > 1 when L ≤ Lthreshold,
we can just use clamp(0, /* expression */, 1) to get the desired result.
One idea would be to use ratios, as they have this nice property where they are > 1 if the numerator is larger than the denominator and ≤ 1 otherwise.
The ratio of
Putting it all together, it looks like this:
--l-threshold: 0.7;
--l: clamp(0, (l / var(--l-threshold) - 1) * -infinity, 1);
color: oklch(from var(--color) var(--l) 0 h);
One worry might be that if L gets close enough to the threshold we could get a number between 0 - 1, but in my experiments this never happened, presumably since precision is finite.
Fallback for browsers that don’t support RCS
The last piece of the puzzle is to provide a fallback for browsers that don’t support RCS.
We can use @supports with any color property and any relative color value as the test, e.g.:
.contrast-color {
/* Fallback */
background: hsl(0 0 0 / 50%);
color: white;
@supports (color: oklch(from red l c h)) {
--l: clamp(0, (l / var(--l-threshold) - 1) * -infinity, 1);
color: oklch(from var(--color) var(--l) 0 h);
background: none;
}
}
In the spirit of making sure things work in non-supporting browsers, even if less pretty, some fallback ideas could be:
- A white or semi-transparent white background with black text or vice versa.
-webkit-text-strokewith a color opposite to the text color. This works better with bolder text, since half of the outline is inside the letterforms.- Many
text-shadowvalues with a color opposite to the text color. This works better with thinner text, as it’s drawn behind the text.
Does this mythical L threshold actually exist?
In the previous section we’ve made a pretty big assumption: That there is a Lightness value (Lthreshold) above which black text is guaranteed to be readable regardless of the chroma and hue, and below which white text is guaranteed to be readable regardless of the chroma and hue. But does such a value exist? It is time to put this claim to the test.
When people first hear about perceptually uniform color spaces like Lab, LCH or their improved versions, OkLab and OKLCH, they imagine that they can infer the contrast between two colors by simply comparing their L(ightness) values. This is unfortunately not true, as contrast depends on more factors than perceptual lightness. However, there is certainly significant correlation between Lightness values and contrast.
At this point, I should point out that while most web designers are aware of the WCAG 2.1 contrast algorithm, which is part of the Web Content Accessibility Guidelines and baked into law in many countries, it has been known for years that it produces extremely poor results. So bad in fact that in some tests it performs almost as bad as random chance for any color that is not very light or very dark. There is a newer contrast algorithm, APCA that produces far better results, but is not yet part of any standard or legislation, and there have previously been some bumps along the way with making it freely available to the public (which seem to be largely resolved).
So where does that leave web authors? In quite a predicament as it turns out. It seems that the best way to create accessible color pairings right now is a two step process:
- Use APCA to ensure actual readability
- Compliance failsafe: Ensure the result does not actively fail WCAG 2.1.
I ran some quick experiments using Color.js where I iterate over the OKLCh reference range (loosely based on the P3 gamut) in increments of increasing granularity and calculate the lightness ranges for colors where white was the “best” text color (= produced higher contrast than black) and vice versa. I also compute the brackets for each level (fail, AA, AAA, AAA+) for both APCA and WCAG.
I then turned my exploration into an interactive playground where you can run the same experiments yourself, potentially with narrower ranges that fit your use case, or with higher granularity.
This is the table produced with C ∈ [0, 0.4] (step = 0.025) and H ∈ [0, 360) (step = 1):
| Text color | Level | APCA | WCAG 2.1 | ||
|---|---|---|---|---|---|
| Min | Max | Min | Max | ||
| white | best | 0% | 75.2% | 0% | 61.8% |
| fail | 71.6% | 100% | 62.4% | 100% | |
| AA | 62.7% | 80.8% | 52.3% | 72.1% | |
| AAA | 52.6% | 71.7% | 42% | 62.3% | |
| AAA+ | 0% | 60.8% | 0% | 52.7% | |
| black | best | 66.1% | 100% | 52% | 100% |
| fail | 0% | 68.7% | 0% | 52.7% | |
| AA | 60% | 78.7% | 42% | 61.5% | |
| AAA | 69.4% | 87.7% | 51.4% | 72.1% | |
| AAA+ | 78.2% | 100% | 62.4% | 100% | |
Note that these are the min and max L values for each level. E.g. the fact that white text can fail WCAG when L ∈ [62.4%, 100%] doesn’t mean that every color with L > 62.4% will fail WCAG, just that some do. So, we can only draw meaningful conclusions by inverting the logic: Since all white text failures are have an L ∈ [62.4%, 100%], it logically follows that if L < 62.4%, white text will pass WCAG regardless of what the color is.
By applying this logic to all ranges, we can draw similar guarantees for many of these brackets:
| 0% to 52.7% | 52.7% to 62.4% | 62.4% to 66.1% | 66.1% to 68.7% | 68.7% to 71.6% | 71.6% to 75.2% | 75.2% to 100% | ||
|---|---|---|---|---|---|---|---|---|
| Compliance WCAG 2.1 | white | ✅ AA | ✅ AA | |||||
| black | ✅ AA | ✅ AAA | ✅ AAA | ✅ AAA | ✅ AAA | ✅ AAA+ | ||
| Readability APCA | white | 😍 Best | 😍 Best | 😍 Best | 🙂 OK | 🙂 OK | ||
| black | 🙂 OK | 🙂 OK | 😍 Best | |||||
You may have noticed that in general, WCAG has a lot of false negatives around white text, and tends to place the Lightness threshold much lower than APCA. This is a known issue with the WCAG algorithm.
Therefore, to best balance readability and compliance, we should use the highest threshold we can get away with. This means:
- If passing WCAG is a requirement, the highest threshold we can use is 62.3%.
- If actual readability is our only concern, we can safely ignore WCAG and pick a threshold somewhere between 68.7% and 71.6%, e.g. 70%.
Here’s a demo so you can see how they both play out. Edit the color below to see how the two thresholds work in practice, and compare with the actual contrast brackets, shown on the table next to (or below) the color picker.
Your browser does not support Relative Color Syntax, so the demo below will not work.
This is what it looks like in a supporting browser:
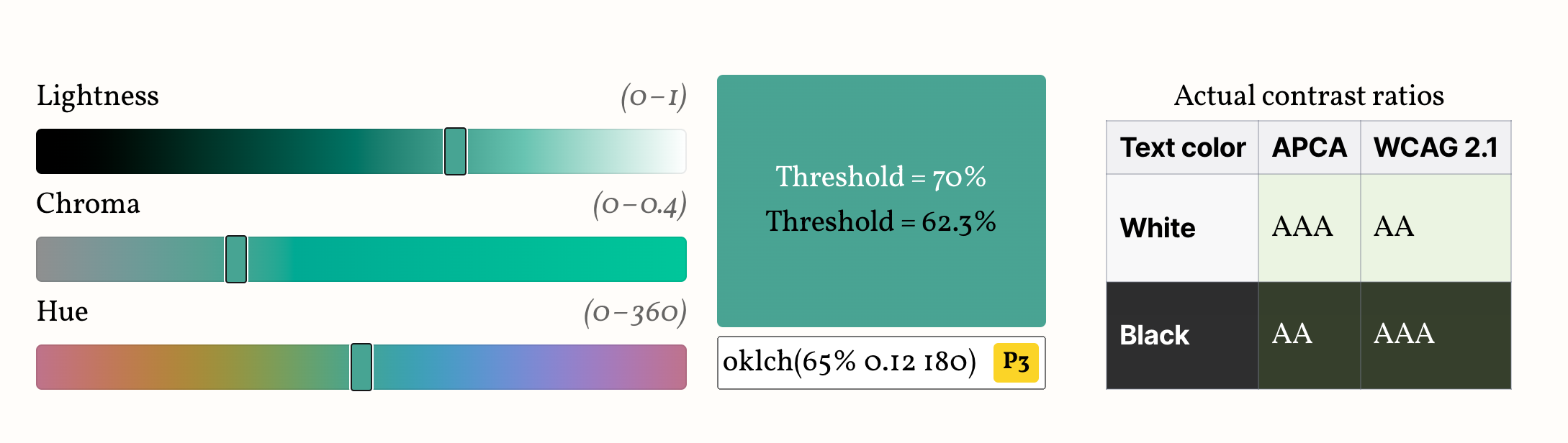
| Text color | APCA | WCAG 2.1 |
|---|---|---|
| White | ||
| Black |
Avoid colors marked “P3+”, “PP” or “PP+”, as these are almost certainly outside your screen gamut, and browsers currently do not gamut map properly, so the visual result will be off.
Note that if your actual color is more constrained (e.g. a subset of hues or chromas or a specific gamut), you might be able to balance these tradeoffs better by using a different threshold. Run the experiment yourself with your actual range of colors and find out!
Here are some examples of narrower ranges I have tried and the highest threshold that still passes WCAG 2.1:
| Description | Color range | Threshold |
|---|---|---|
| Modern low-end screens | Colors within the sRGB gamut | 65% |
| Modern high-end screens | Colors within the P3 gamut | 64.5% |
| Future high-end screens | Colors within the Rec.2020 gamut | 63.4% |
| Neutrals | C ∈ [0, 0.03] | 67% |
| Muted colors | C ∈ [0, 0.1] | 65.6% |
| Warm colors (reds/oranges/yellows) | H ∈ [0, 100] | 66.8% |
| Pinks/Purples | H ∈ [300, 370] | 67% |
It is particularly interesting that the threshold is improved to 64.5% by just ignoring colors that are not actually displayable on modern screens. So, assuming (though sadly this is not an assumption that currently holds true) that browsers prioritize preserving lightness when gamut mapping, we could use 64.5% and still guarantee WCAG compliance.
You can even turn this into a utility class that you can combine with different thesholds:
.contrast-color {
--l: clamp(0, (l / var(--l-threshold, 0.623) - 1) * -infinity, 1);
color: oklch(from var(--color) var(--l) 0 h);
}
.pink {
--l-threshold: 0.67;
}
Conclusion & Future work
Putting it all together, including a fallback, as well as a “fall forward” that uses contrast-color(),
the utility class could look like this:
.contrast-color {
/* Fallback for browsers that don't support RCS */
color: white;
text-shadow: 0 0 .05em black, 0 0 .05em black, 0 0 .05em black, 0 0 .05em black;
@supports (color: oklch(from red l c h)) {
--l: clamp(0, (l / var(--l-threshold, 0.623) - 1) * -infinity, 1);
color: oklch(from var(--color) var(--l) 0 h);
text-shadow: none;
}
@supports (color: contrast-color(red)) {
color: contrast-color(var(--color));
text-shadow: none;
}
}
This is only a start. I can imagine many directions for improvement such as:
- Since RCS allows us to do math with any of the color components in any color space, I wonder if there is a better formula that still be implemented in CSS and balances readability and compliance even better. E.g. I’ve had some chats with Andrew Somers (creator of APCA) right before publishing this, which suggest that doing math on luminance (the Y component of XYZ) instead could be a promising direction.
- We currently only calculate thresholds for white and black text.
However, in real designs, we rarely want pure black text,
which is why
contrast-color()only guarantees a “very light or very dark color” unless themaxkeyword is used. How would this extend to darker tints of the background color?
Addendum
As often happens, after publishing this blog post, a ton of folks reached out to share all sorts of related work in the space. I thought I’d share some of the most interesting findings here.
Using luminance instead of Lightness
When colors have sufficiently different lightness values (as happens with white or black text), humans disregard chromatic contrast (the contrast that hue/colorfulness provide) and basically only use lightness contrast to determine readability. This is why L can be such a good predictor of whether white or black text works best.
Another measure, luminance, is basically the color’s Y component in the XYZ color space, and a good threshold for flipping to black text is when Y > 0.36. This gives us another method for computing a text color:
--y-threshold: 0.36;
--y: clamp(0, (y / var(--y-threshold) - 1) * -infinity, 1);
color: color(from var(--color) xyz-d65 var(--y) var(--y) var(--y));
As you can see in this demo by Lloyd Kupchanko, using Ythreshold > 36% very closely predicts the best text color as determined by APCA.
In my tests (codepen) it appeared to work as well as the Lthreshold method, i.e. it was a struggle to find colors where they disagree. However, after this blog post, Lloyd added various Lthreshold boundaries to his demo, and it appears that indeed, Lthreshold has a wider range where it disagrees with APCA than Ythreshold does.
Given this, my recommendation would be to use the Ythreshold method if you need to flip between black and white text, and the Lthreshold method if you need to customize the text color further (e.g. have a very dark color instead of black).
Browser bug & workarounds
About a week after publishing this post, I discovered a browser bug with color-mix() and RCS,
where colors defined via color-mix() used in from render RCS invalid.
You can use this testcase to see if a given browser is affected.
This has been fixed in Chrome 125 and Safari TP release 194, but it certainly throws a spanner in the works since the whole point of using this technique is that we don’t have to care how the color was defined.
There are two ways to work around this:
- Adjust the
@supportscondition to usecolor-mix(), like so:
@supports (color: oklch(from color-mix(in oklch, red, tan) l c h)) {
/* ... */
}
The downside is that right now, this would restrict the set of browsers this works in to a teeny tiny set. 2. Register the custom property that contains the color:
@property --color {
syntax: "<color>";
inherits: true;
initial-value: transparent;
}
This completely fixes it, since if the property is registered, by the time the color hits RCS, it’s just a resolved color value.
@property is currently supported by a much wider set of browsers than RCS, so this workaround doesn’t hurt compatiblity at all.
Useful resources
Many people have shared useful resources on the topic, such as:
- Black or White?: Compare different contrast algorithms for picking between black or white
- Dynamic text color contrast based on background lightness with CSS/SVG filters: A different approach to the same problem (requires extra HTML element for the text)
Thanks to Chris Lilley, Andrew Somers, Cory LaViska, Elika Etemad, and Tab Atkins-Bittner for their feedback on earlier drafts of this article.
Eigensolutions: composability as the antidote to overfit
tl;dr: Overfitting happens when solutions don’t generalize sufficiently and is a hallmark of poor design. Eigensolutions are the opposite: solutions that generalize so much they expose links between seemingly unrelated use cases. Designing eigensolutions takes a mindset shift from linear design to composability.
Creator tools are not Uber or Facebook
In product literature, the design process looks a bit like this:
This works great with the kinds of transactional processes (marketplaces, social media, search engines, etc) most product literature centers around, but can fall apart when designing creative tools (developer tools, no-code tools, design tools, languages, APIs etc.), as there are fundamental differences[1] between the two:
- In transactional processes, users have clearly defined goals, and the task is highly specialized (e.g. “Go to work”, “Order takeout”, “Find accommodation for my upcoming trip”) and can often be modeled as a linear process.
- In creator tools, use cases vary wildly, goals are neither linear, nor clearly defined, and may even change throughout the session.
Creator tools typically ship knowingly addressing only a percentage of their key use cases — otherwise they would never ship at all. It’s all about balancing UX, use case coverage, and design/implementation effort.
Evaluating user experience: Floor and ceiling
In end-user programming we talk about the floor and the ceiling of a tool:
- The floor is the minimum level of knowledge users need to create something useful.
- The ceiling refers to the extent of what can be created.
I think that vocabulary generalizes more broadly to creator tools, and can be a useful UX metric.
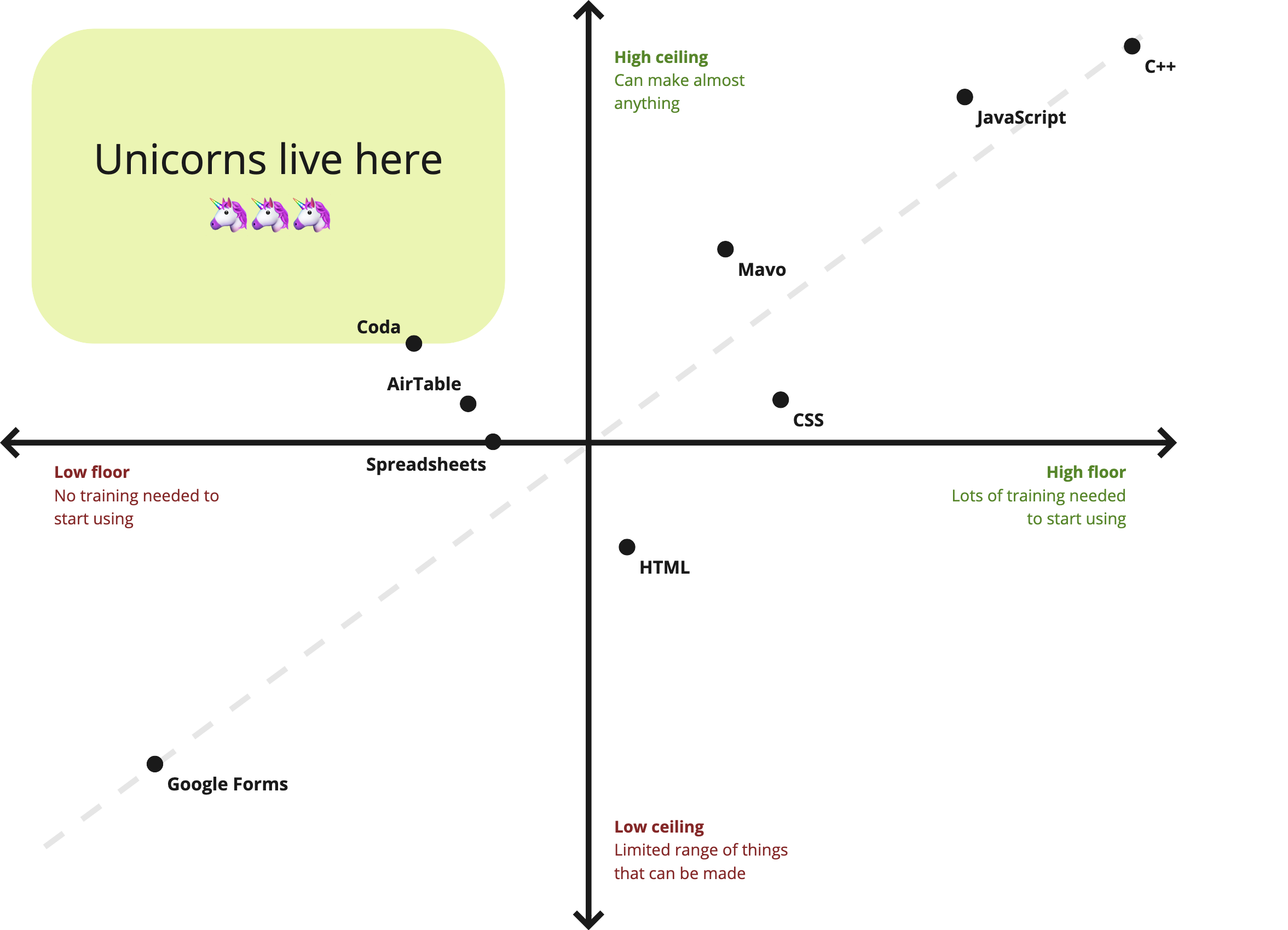
Programming languages tend to have high ceiling, but also a high floor: You make anything, but it requires months or years of training, whereas domain specific GUI builders like Google Forms have a low floor, but also a low ceiling: Anyone can start using them with no training, but you can also only make very specific kinds of things with them.
A product that combines a low floor with a high ceiling is the unicorn of creator tools. Therefore, most product work in creator tools centers around either reducing the floor (making things easier), or increasing the ceiling (making things possible). Which one of the two takes priority depends on various factors (user research, product philosophy, strategy etc.), and could differ by product area or even by feature.
Evaluating use case coverage: The Use Case Backlog
In creator tools, use cases tend to accumulate at a much faster rate than they can be addressed, especially in the beginning. Therefore we end up with what I call a “use case backlog”: a list of use cases that are within scope, but we cannot yet address due to lack of resources, good solutions, or both. The more general purpose and the more ambitious the tool is, the higher the rate of accumulation, since the pool of use cases is naturally larger.
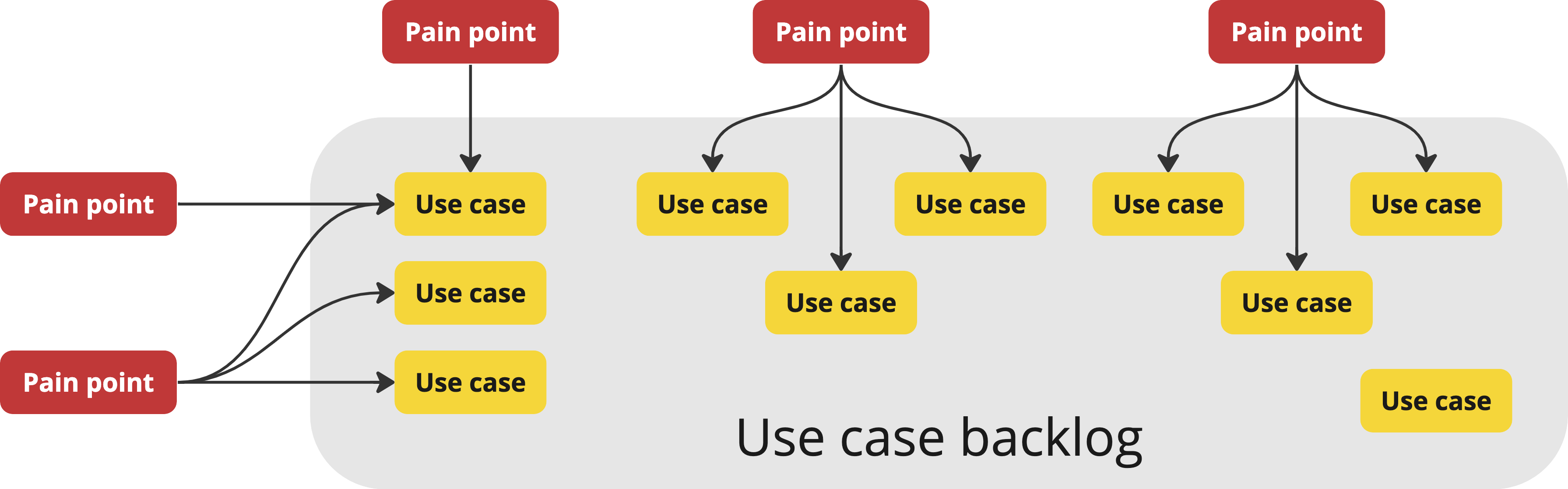
Pain points get processed into use cases, which accumulate in the use case backlog
Unlike the linear design process of transactional processes, the design process for creator tools often consists of matching use cases to solutions, which can happen before, during, or after idea conception.
A product may include both transactional processes and creator tools, e.g. Instagram is a social media platform (transactional) with a photo editor (creator tool). Although these tend to be more domain-specific creator tools, which are less good examples for the concepts discussed here.
From overfitting to eigensolutions
Shishir Mehrotra (of Coda) wrote about the importance of “Eigenquestions” when framing problems, a term he coined, inspired from his math background:
the eigenquestion is the question where, if answered, it likely answers the subsequent questions as well.
This inspired me to name a symmetrical concept I’ve been pondering for a while: Eigensolutions. The eigensolution is a solution that addresses several key use cases, that previously appeared unrelated.
An eigensolution is the polar opposite of overfitting. Overfitting happens when the driving use cases behind a solution are insufficiently diverse, so the solution ends up being so specific it cannot even generalize to use cases that are clearly related.
Overfitting is one of the worst things that can happen during the design process. It is a hallmark of poor design that leads to feature creep and poor user experiences. It forces product teams to keep adding more features to address the use cases that were not initially addressed. The result is UI clutter and user confusion, as from the user’s perspective, there are now multiple distinct features that solve subtly different problems.
A mindset shift to composability
This is all nice and dandy, but how do we design and ship eigensolutions? Do we just sit around waiting for inspiration to strike? Well, we could, but it would be a pretty poor use of resources. :)
Instead, it takes a mindset shift, from the linear Use case → Idea → Solution process to composability. Rather than designing a solution to address only our driving use cases, step back and ask yourself: can we design a solution as a composition of smaller, more general features, that could be used together to address a broader set of use cases? In many cases the features required for that composition are already implemented and are just missing one piece: our eigensolution. In other cases composability may require more than one new feature, but the result can still be a net win since these features are useful on their own and can ship independently.
A composability mindset requires being aware of pain points and use cases across many different product areas. This becomes harder in larger organizations, where product teams are highly specialized. It’s not impossible, but requires conscious effort to cross-polinate all the way down, rather than completely depending on higher levels of the hierarchy to maintain a bird’s eye view of the product.
It’s also important to note that it’s a spectrum, not a binary: overfitting and eigensolutions are just its two opposite ends. Eigensolutions do not come along every day, and do not even exist for all problems. While it’s important to actively guard against overfitting by making sure solutions are validated by many diverse use cases, going too far the other side and chasing a general solution for every problem is also a poor use of resources.
Instead, I think a happy medium is to try and be on the right side of the spectrum:

Shipping eigensolutions
Good design is only part of the work; but without shipping, even the most well designed feature is a pointless document. Contrary to what you may expect, eigensolutions can actually be quite hard to push to stakeholders:
- Due to their generality, they often require significantly higher engineering effort to implement. Quick-wins are easier to sell: they ship faster and add value sooner. In my 11 years designing web technologies, I have seen many beautiful, elegant eigensolutions be vetoed due to implementation difficulties in favor of far more specific solutions — and often this was the right decision, it’s all about the cost-benefit.
- Eigensolutions tend to be lower level primitives, which are more flexible, but can also involve higher friction to use than a solution that is tailored to a specific use case.
In many cases, layering can resolve or mitigate both of these issues.
Layering with higher level abstractions
My north star product design principle is “Common things should be easy, complex things should be possible” (paraphrasing Alan Kay — because common things are not always simple, but it’s common things you want to optimize for), which in essence is another way of aiming for low floors and high ceilings.
Eigensolutions tend to be lower level primitives. They enable a broad set of use cases, but may not be the most learnable or efficient way to implement all of them, compared to a tailored solution. In other words, they make complex things possible, but do not necessarily make common things easy. Some do both, in which case congratulations, you’ve got an even bigger unicorn! You can skip this section. :)
However, this is one of the rare times in life where we can have our cake and eat it too. Instead of implementing tailored solutions ad-hoc (risking overfitting), they can be implemented as shortcuts: higher level abstractions using the lower level primitive. Done well, shortcuts provide dual benefit: not only do they reduce friction for common cases, they also serve as teaching aids for the underlying lower level feature. This offers a very smooth ease-of-use to power curve: if users need to go further than what the shortcut provides, they can always fall back on the lower level primitive to do so. We know that tweaking is easier than creating from scratch, so even when users use that escape hatch, they can tweak what they had created with the higher level UI, rather than starting from scratch. This combined approach both reduces the floor and increases the ceiling!
Example: Table filtering in Coda
Coda is a product I’ve been using a lot in the last few months. It has replaced Google Docs, Google Sheets, and a few more niche or custom apps I was using. Its UI is full of examples of this pattern, but for the sake of brevity, I will focus on one: table filtering.
At first, the filtering UI is pretty high level, designed around common use cases:
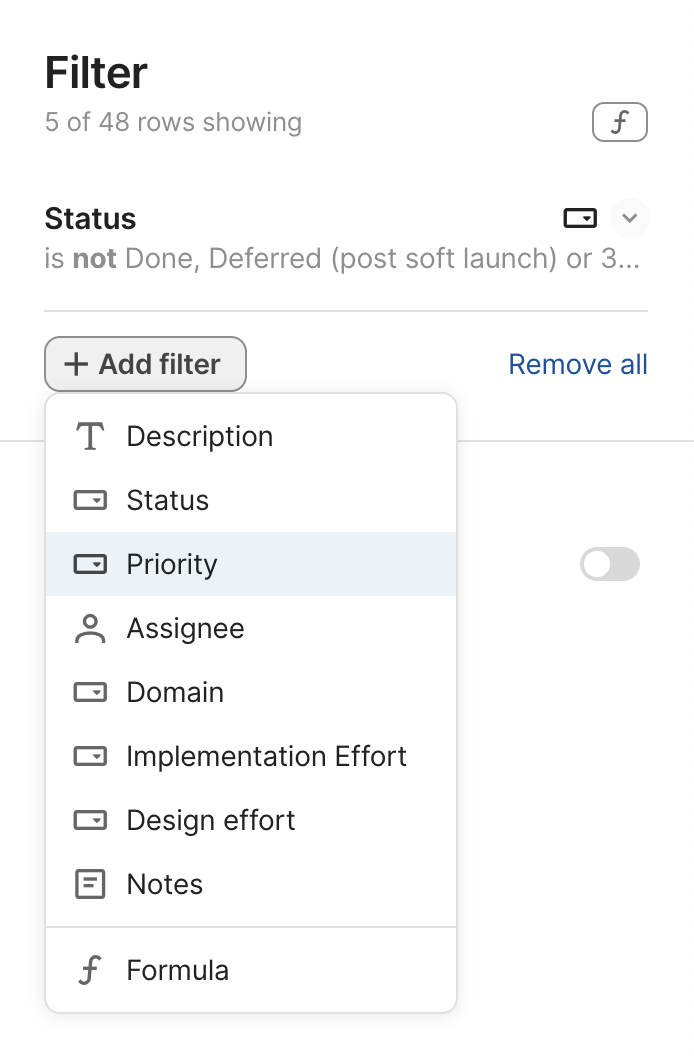
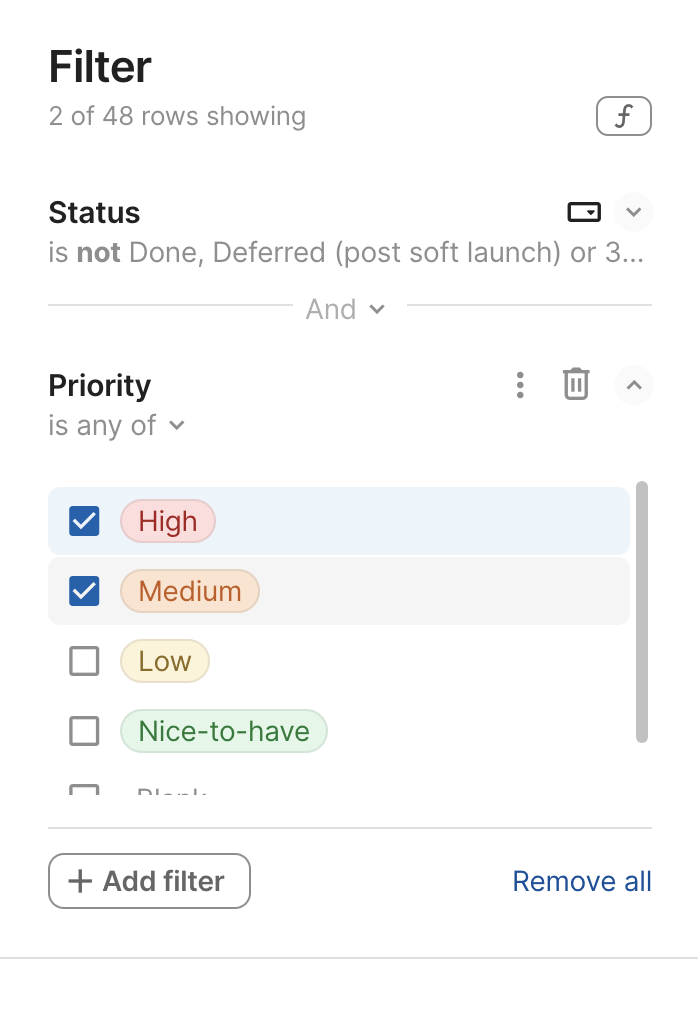
Also note the nice touch of “And” not just being informative, but also a control that allows the user to edit the logic used to combine multiple filters.
For the vast majority of use cases (I would guess >95%), the UI is perfectly sufficient. If you don’t need additional flexibility, you may not even notice the little f button on the top right. But for those that need additional power it can be a lifesaver. That little f indicates that behind the scenes, the UI is actually generating a formula for filtering. Clicking it opens a formula editor, where you can edit the formula directly:
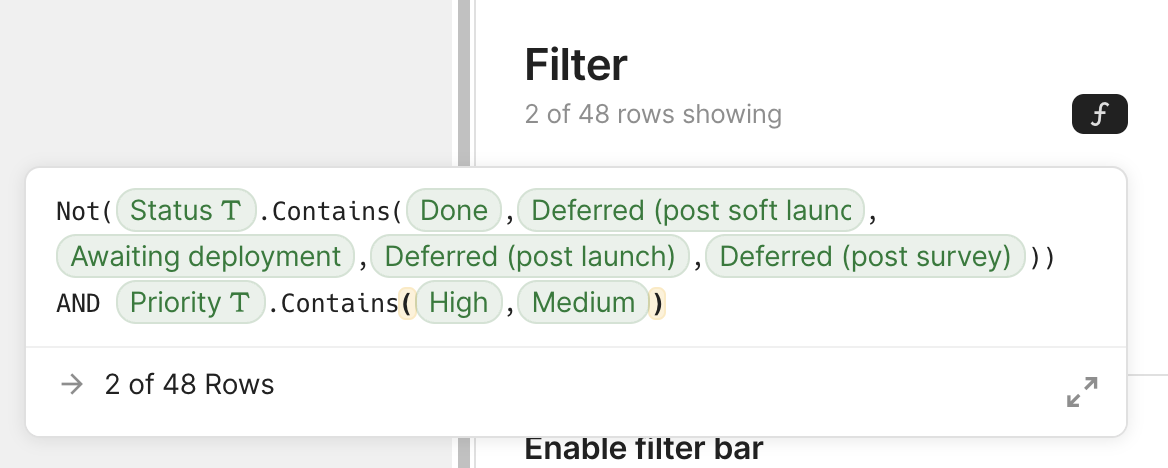
I suspect that even for the use cases that require that escape hatch, a small tweak to the generated formula is all that is necessary. The user may have not been able to write the formula from scratch, but tweaking is easier. As one data point, the one time I used this, it was just about using parentheses to combine AND and OR differently than the UI allowed. And as a bonus, the app can collect metrics about what users do with the lower level feature and use that to improve the higher level UI. It’s a win-win all around.
What to ship first?
In an ideal world, lower level primitives and higher level abstractions would be designed and shipped together. However, engineering resources are typically limited, and it often makes sense to ship one before the other, so we can provide value sooner.
This can happen in either direction:
- Lower level primitive first. Shortcuts to make common cases easy can ship at a later stage, and demos and documentation to showcase common “recipes” can be used as a stopgap meanwhile. This prioritizes use case coverage over optimal UX, but it also allows collecting more data, which can inform the design of the shortcuts implemented.
- Higher level abstraction first, as an independent, ostensibly ad hoc feature. Then later, once the lower level primitive ships, it is used to “explain” the shortcut, and make it more powerful. This prioritizes optimal UX over use case coverage: we’re not covering all use cases, but for the ones we are covering, we’re offering a frictionless user experience.
But which one? As with most things in life, the answer is “it depends”.
A few considerations are:
- How many shortcuts do we need? What percentage of use cases do they cover?
- How much harder is it to use the lower level primitive directly? Are we certain we will need to provide shortcuts, or is it possible it may be sufficient on its own?
- Which one are we more confident about?
- How much engineering effort does the lower level primitive require and how does it compare to implementing the shortcuts as ad hoc features?
- Do we have extensibility mechanisms in place for users to create and share their own higher level abstractions over the lower level feature?
Outside of specific cases, it’s also good to have a design principle in place about which way is generally favored, which is part of the product philosophy (the answer to the eigenquestion: “Are we optimizing for flexibility or learnability?”) and can be used to fall back on if weighing tradeoffs ends up inconclusive.
Note that even when we don’t think the eigensolution is implementable, it can still be useful as a north star UI and designing the tailored solutions as special cases of it can still be a good idea.
In the web platform we’ve gone back and forth on this a lot. In the beginning, the Web skewed towards shipping higher level abstractions. It had a low floor, but also a relatively low ceiling: many capabilities required browser plugins, or desktop applications. The Extensible Web Manifesto was created as a reaction, urging standards groups to design low level primitives first. For a while, this became the gold standard and many new features were very low level. This filled some necessary gaps in the platform, but since resources are limited, the layering was often missed, resulting in only low level primitives which were a pain to use. More recently, we’ve been recommending a more balanced approach, where tradeoffs are evaluated on a case by case basis.
A fictional example: TableSoda
Suppose we were working on a fictional product that is an improvement over spreadsheets, let’s call it TableSoda. It has several features that make it more powerful and user-friendly than spreadsheets:
- It allows users to have multiple tables and define formulas or datatypes for a whole column
- It also supports references from a cell of one table to a row of another table.
- Its formula language supports operations on entire columns, and can return entire rows from other tables.
- Each table can be shared with different people, but a given user can either see/edit all the rows and columns of a table, or none.
Some of the use cases in TableSoda’s use case backlog are:
- Pivot tables: tables that display stats about the usage of a value in another table (usually counts but also sum, min, max, average, etc.)[2]
- Unions of multiple tables. For example, combining a table of debits and a table of credits into a table of transactions.
- Vertical splitting: Multiple tables augmenting the same data with different metadata. For example, a table of product features, another table that scores these features on various factors, and lastly, a table of 👍🏼 reactions by different team members about each feature.
- Granular access control, by row(s) or column(s). For example, a table of tasks where each row is assigned to a different team member, and each team member can only see their own tasks and only edit the status column.
With the traditional PM mindset, we would prioritize which one(s) of these is most important to solve, design a few possible solutions, evaluate tradeoffs between them. Over time, we may end up with a pivot table feature, a table union feature, a table vertical split feature, a row-level access control feature, and a column-level access control feature. These features would not necessarily be overfitting, they may solve their respective use cases quite well. But they also add a lot of complexity to the product.
Instead, we would still prioritize which one to address first, but with the mindset of decomposing it to its essential components and addressing those (note that there may be many different possible decompositions). Suppose we decide that we want to prioritize pivot tables. A pivot table is essentially[2:1]:
- A table of all unique values in the source column
- For each unique value, columns with its count, sum, etc. in the source column
Users can already count the number of values in a column using formulas, and they can also use a unique() formula to get a list of unique values in a column.
So what prevents them from creating their own pivot tables?
There is no way to create dynamic tables in TableSoda, rows can only be added by users.
What if we could populate a table’s rows via a formula? The formula values could be used either for one column or multiple (if it returns a list of objects).
Formula-populated tables not only solve our driving use case, but all of the above:
- Unions can be implemented by using a formula to concatenate the rows of multiple tables into a single list.
- Vertical splitting can be implemented by using a formula to keep the rows of multiple tables in sync with a master table
- Granular access control can be implemented by having a table with different permissions that is populated using a formula that filters the rows and/or columns of the source table.
It’s an eigensolution!
Note that our eigensolution is not the end for any of our use cases. It makes many things possible, but none of them are easy. Some of them are common enough to warrant a shortcut: UI that generates the formula needed. For others, our solution is more of a workaround than a primary solution, and the search for a primary solution continues, potentially with reduced prioritization. And others don’t come up often enough to warrant anything further. But even if we still need to smoothen the ease-of-use to power curve, making things possible bought us a lot more time to make them easy.
Use cases as the testsuite of product design
The most discerning of readers may have noticed that despite the name eigensolution, it’s still all about the use cases: eigensolutions just expose links between use cases that may have been hard to detect, but seem obvious in retrospect. In the example above, one could have seen in advance that all of these use cases were fundamentally about dynamically populating tables. But wasn’t it so much easier to see in retrospect?
Requiring all use cases to precede any design work can be unnecessarily restrictive, as frequently solving a problem improves our understanding of the problem.
Joe McLean (of Miro) takes a more extreme position:
I believe it’s best to think of a use case as a test case to see if your basic tools are working. What’s missing from the toolbox? What are the limits of what’s available? What 4 use cases would open up with the addition of one more tool?
Use cases should be applied after design is done — to check if the tools available can accomplish the job. As a starting point, they put you in a mindset to overfit. This is especially dangerous because users will often tell you they love it in concept testing. “Ah yes, here is my process, represented in pictures!” But it’s only when you actually try to use the tool — hold the thing in your hands — that there’s a hundred things you need it to do that it doesn’t. It’s not flexible — it’s a series of menus and disappointed feature requirements.
Joe argues for using use cases only at the end, to validate a design, as he believes that starting from use cases leads puts you in a mindset to overfit. This is so much the polar opposite of current conventional wisdom, that many would consider it heresy.
I think that also imposes unnecessary constraints on the design process. I personally favor a more iterative process:
- Collect as many diverse use cases as possible upfront to drive the design
- Additional use cases are used to refine the design until it stabilizes
- Even more at the end to validate it further.
If you’re on the right path, additional use cases will smoothly take you from refinement to validation as the design stabilizes. If you’re not on the right path, they will expose fundamental flaws in your design and show you that you need to start over.
This has some similarities to test-driven development in engineering: engineers start with a few test cases before writing any code, then add more as they go to make sure everything works as expected.
But if someone else’s design thinking works best with using use cases only for validation, more power to them!
What matters is that the outcome is a solution that addresses a broad set of use cases in a way users can understand and use. We can probably all agree that no proposal should be considered without being rigorously supported by use cases. It is not enough for use cases to exist; they need to be sufficiently diverse and correspond to real user pain points that are common enough to justify the cost of adding a new feature. But whether use cases drove the design, were used to validate it, or a mix of both is irrelevant, and requiring one or the other imposes unnecessary constraints on the design process.
Thanks to Marily Nika and Elika Etemad for providing feedback on an earlier draft of this post.
Notable reactions
I hesitantly published this article right before the 2023 winter break. I say hesitantly, because it was a departure from my usual content, and I wasn’t sure how it would be received. I was elated to see that despite its length, somewhat intimidating title, and publication date, it did get some very validating reactions.
My favorite was Daniel Jackson’s insightful summary of the ideas presented:
I just came across an excellent post by Lea Verou which argues for building software on more general and composable abstractions.
In short, I see several different ideas at play in her piece:
- Use cases lead to overfitting and it’s better to design more coherent and general increments of function;
- More complex and domain-specific functionality can often be obtained as an instantiation or composition of more abstract and general functionality;
- Even if you don’t implement the more general and abstract functionality, it might be better to design it and think of your implementation as partial;
- You can use progressive disclosure in the UI as a bridge between more common domain-specific functionality and more general functionality.
These ideas seem to have a lot in common with concept design. Maybe her eigensolutions are concepts? What do y’all think? Also, I really liked the critique of use cases, which connects to our discussion last year of Bertrand Meyer’s piece.
It was very validating to see that the ideas resonated with someone who has been thinking about good conceptual design so deeply that it’s his primary area of research at MIT for years, and has published an excellent book on the matter (I only started reading it recently, but I’m loving it so far).
It was also validating to see that the ideas resonated with Shishir Mehrotra (CEO of Coda), who commented:
Very insightful article, loved it!
If you recall, it was him who coined the term eigenquestion that inspired the term eigensolution.
Daniel Fosco (Software designer at Miro) reposted and wrote:
This is by far the best design article I’ve read in a very long time. Lea dives right into what it takes to build complex tools that have to meet wide, unmapped user needs. I also love how it does not shy away from the complexity of the topic even for a moment: on the contrary, the title is already telling you what you’re signing up for. @leaverou is no stranger to great writing, but this one is truly a gem.
I recently started using Miro myself, for diagrams and wireframes (most illustrations in this article have been made with Miro), and there are some real gems in its design, so it was very validating to see that the ideas resonated with someone who works on designing it.
Fredrik Matheson (Creative Director at Bekk) reposted and wrote:
Are you new to UX? This post will be a bit like taking an elevator up above the clouds, where you can see further, beyond the constraints of the transactional systems you might be working on already. Recommended.
He even subsequently proceeded to quote concepts from it in a number of comments on other posts! 🤩
Nate Baldwin (Principal Product Designer at Intuit) reposted and wrote:
This is a wonderful article! What @LeaVerou defines is what I consider platform design, which I think sits one level below UI systems design. Ie:
Product design ⬇️ Systems design (UI) ⬇️ Platform design
Although her approach to design is relevant to each.
I’ve spent so long designing creator tools that I tended to assume my observations and learnings from my experience are universal. I first read about this distinction in Joe Mc Lean’s excellent post on overfitting, and it was a bit of an a-ha moment. ↩︎
Yes, pivot tables are more complex than that, but let’s keep it simple for the sake of the example. ↩︎ ↩︎
Minimalist Affordances: Making the right tradeoffs
Usability and aesthetics usually go hand in hand. In fact, there is even what we call the “Aesthetic Usability Effect”: users perceive beautiful interfaces as easier to use and cut them more slack when it comes to minor usability issues.
Unfortunately, sometimes usability and aesthetics can be at odds, also known as “form over function”.
Simplicity, and knowing when to stop
A common incarnation of form-over-function, is when designers start identifying signifiers and affordances as noise to be eliminated, sacrificing a great deal of learnability for an — often marginal — improvement in aesthetics.
Aesthetic and Minimalist Design is one of the Nielsen/Norman core usability heuristics (and all other heuristics taxonomies have something similar). More poetically, Antoine de Saint-Exupéry said “Perfection is achieved, not when there is nothing more to add, but when there is nothing left to take away”. However, this is one of those cases where everyone agrees with the theory, but the devil is in the details (though user testing can do wonders for consensus).
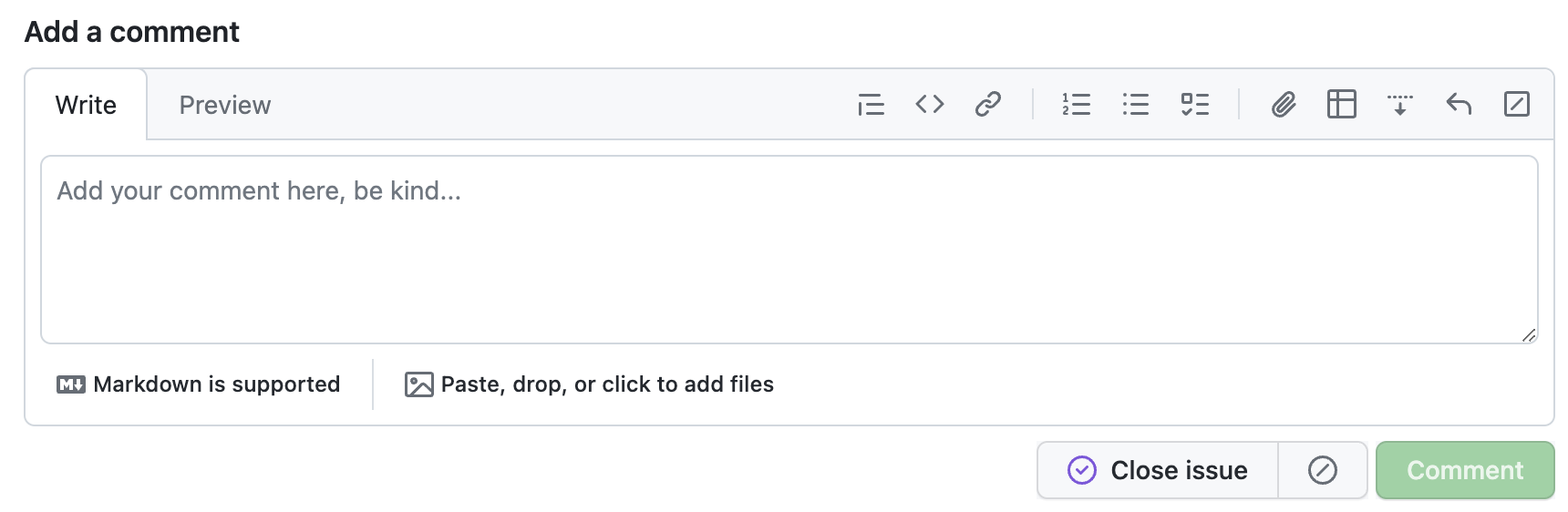
Case in point: The new Github comment UI is beautiful. Look at how the text area smoothly blends with the tab, creating an irregular and visually interesting shape!
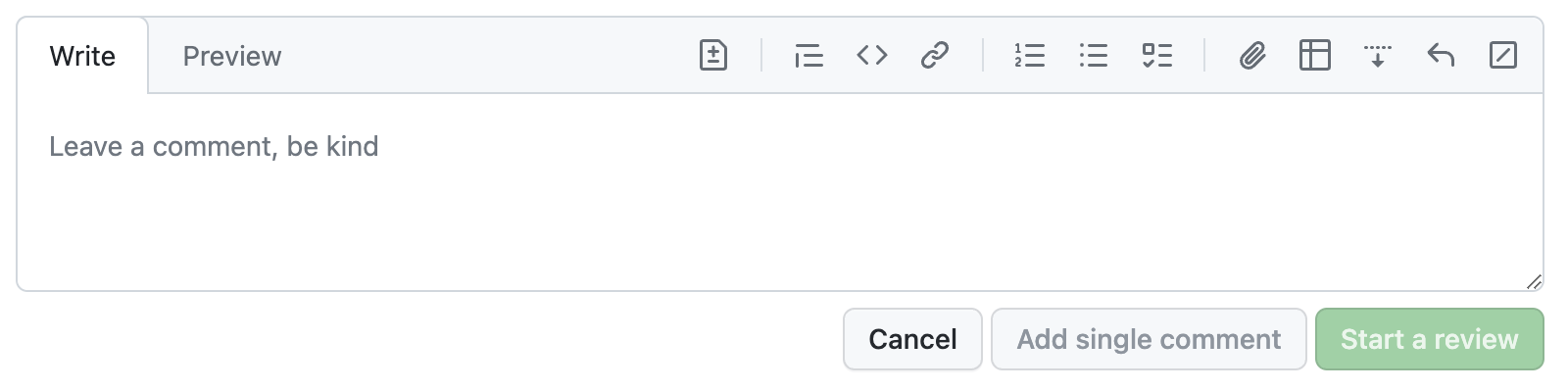
The new GitHub commenting UI, unfocused.
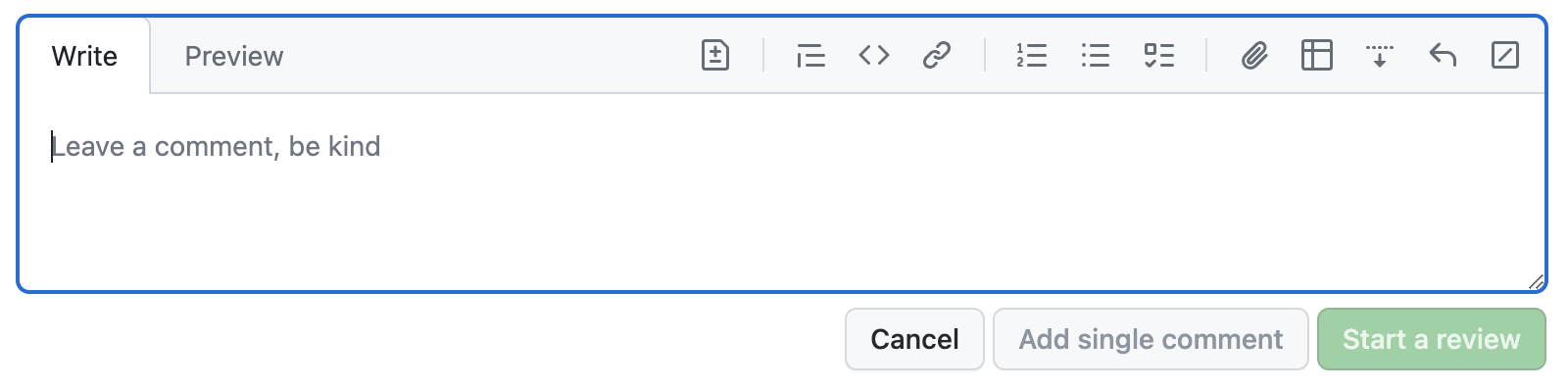
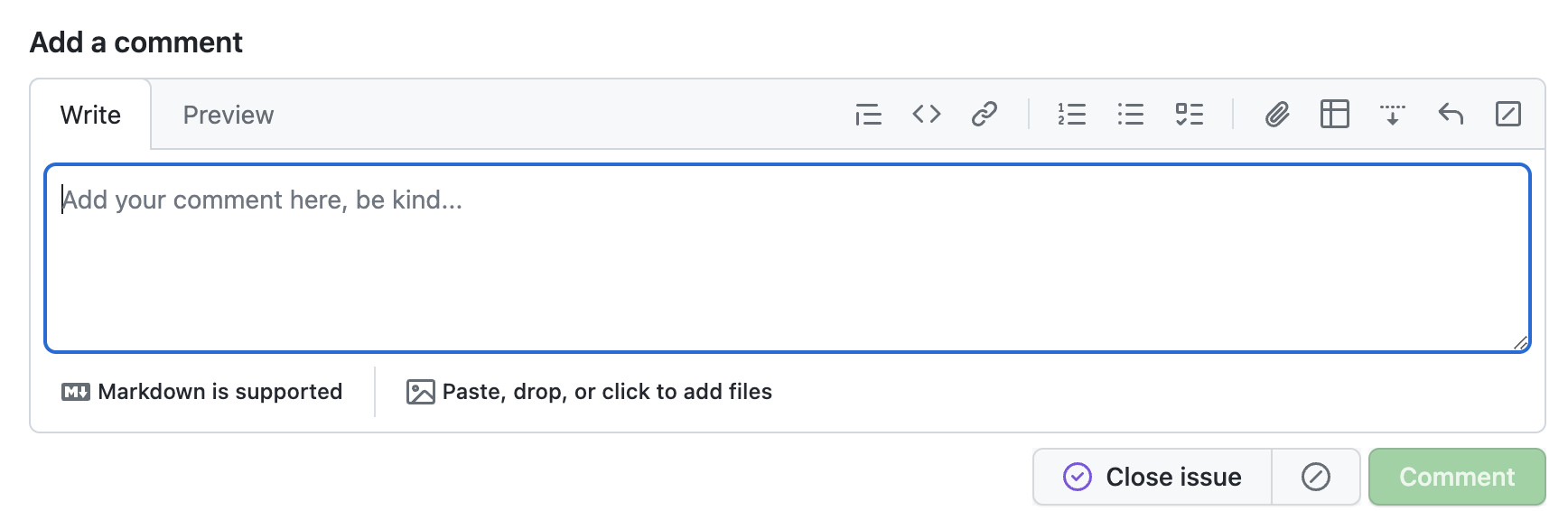
The new GitHub commenting UI, focused. Am I the only one that expected the focus outline to also follow the irregular shape?
However, I cannot for the life of me internalize that this is a text field that I can type in. Even after using it over a dozen times, I still have to do a double take every time (“Where is the comment field?!”, “Why is this read-only?”).
For comparison, this was the old UI:
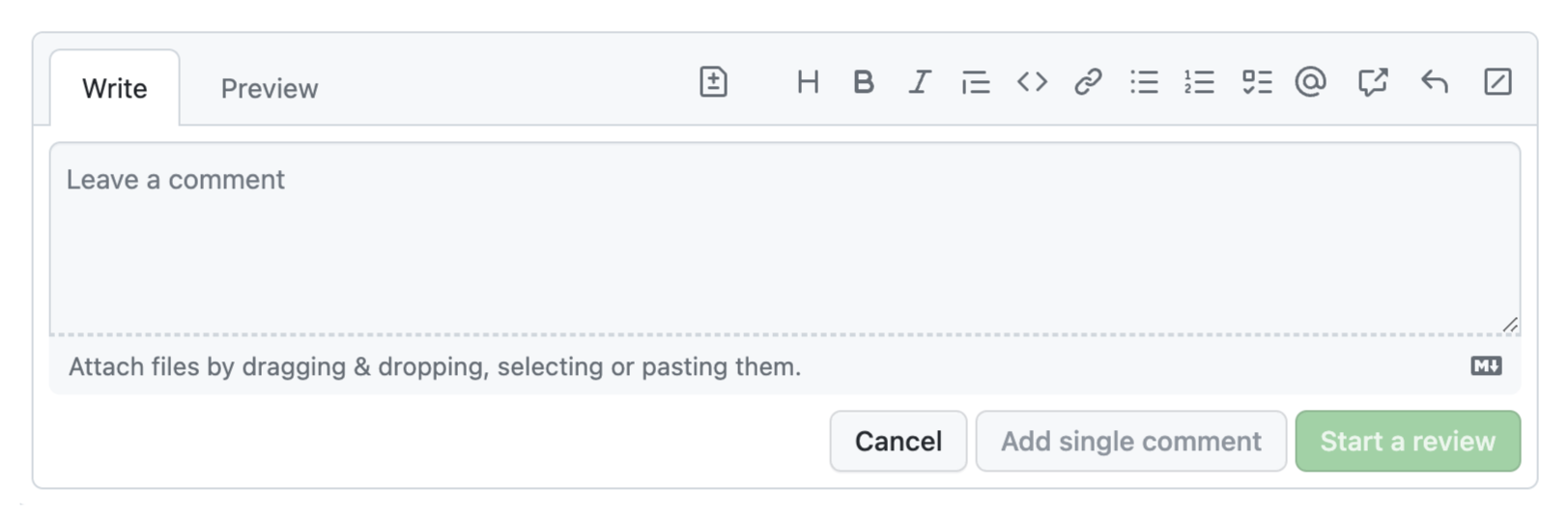
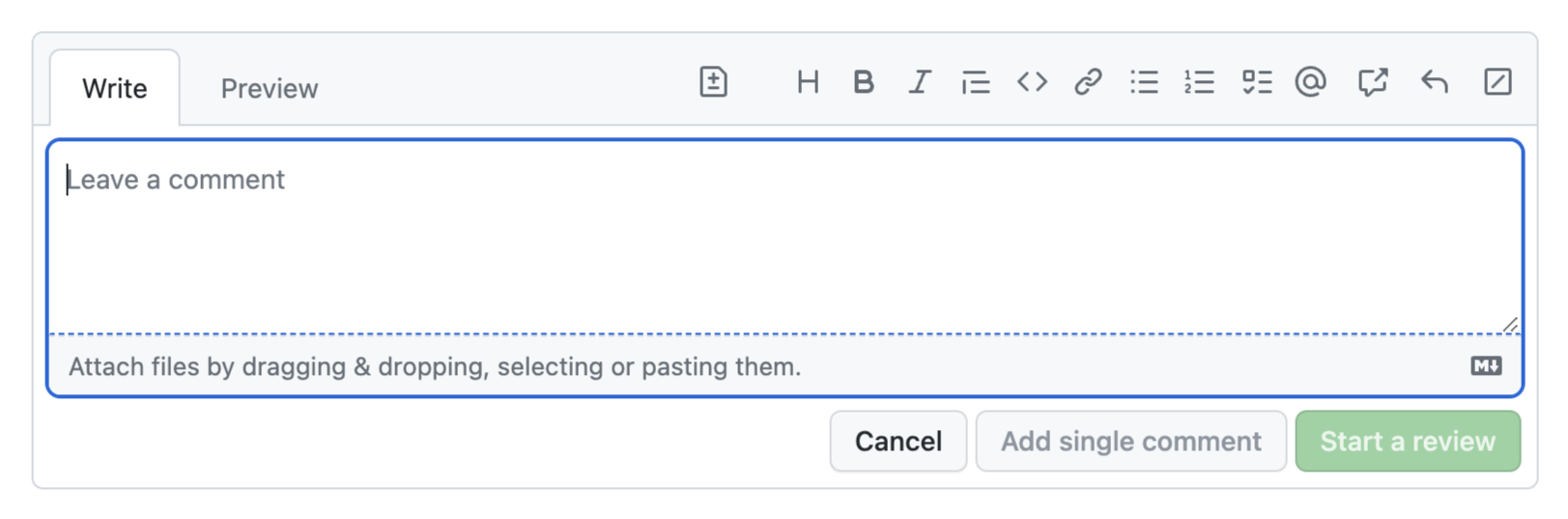
While definitely more cluttered, its main UI elements were much more recognizable: there is a text field, indicated by the rounded rectangle, and tabs, indicated by the light gray border around the active tab. By merging the two, both affordances are watered down to the point of being unrecognizable.
Yes, there was more visual clutter, not all of which serves a purpose. A skilled designer could probably eliminate the rounded rectangle around the entire area without impacting usability. But the current design goes too far, and throws the baby out with the bathwater.
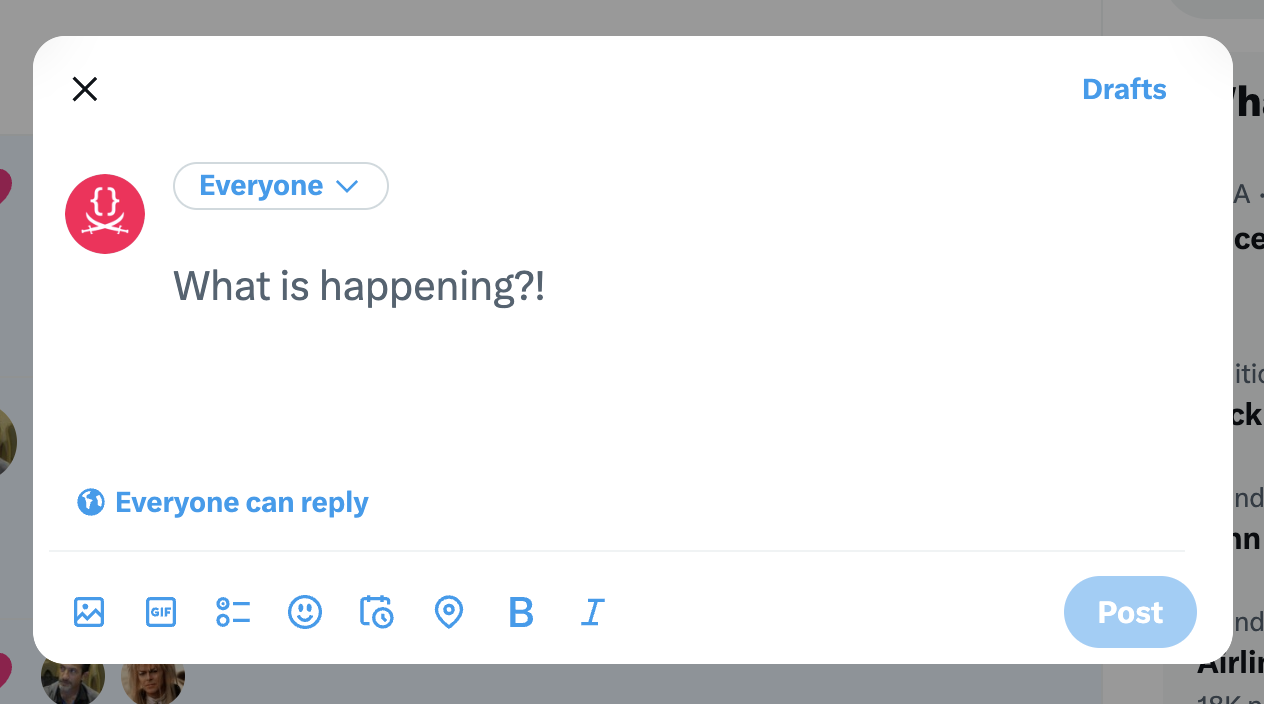
Twitter seems to be trying something similar, but since there is no irregular shape, the text field affordance is not entirely lost.
The ever-evolving vocabulary of user interaction
Communication is all about mutually understood conventions: a sufficiently widespread grammatical mistake eventually becomes part of the language. In the language of user interfaces, affordances and signifiers are the vocabulary, and the same principles apply. Learnability is not an intrinsic property of a UI; it is a function of the context (cultural and otherwise) in which it is used.
Many affordances and signifiers use metaphors from the physical world to communicate what a user can do. For example a button that looks raised reminds us of physical buttons. Tabs are a metaphor for the tabs in a binder. Others are entirely arbitrary and acquire meaning through learning, such as link underlines or the “hamburger” menu icon.
We see the same pattern in language: some words are onomatopoeic, such as “buzz” or “meow”, while others are entirely learned, such as “dog” or “cat”. Similarly, writing systems began as pictograms, but evolved to be more abstract and symbolic.

Insight and picture from https://ux.stackexchange.com/a/56896/11761
At first, the symbols are direct (if cartoony) representations. Then they slowly lose their extrinsic meaning and become defined more by our conventions of using them (our shared language) and the references to outside concepts disappear.
It’s worth reading the whole post if you have time.
UI evolution is rife with patterns that began as obscure and ended up as obvious. In other words, external consistency improved, not because the UIs changed, but because the environment did.
Some examples you are undoubtedly familiar with:
- Underlines have always been a strong affordance for links (to the point that using them for anything else is an antipattern). However, users evolved to perceive weaker signals as links, such as different colors, especially if used consistently.
- Clicking a website logo to go to the homepage was once an obscure hidden interaction, almost an easter egg. It is now so conventional that a logo that does nothing when clicked is considered a usability issue (though having separate Home links is still the recommendation, 28 years after the pattern was introduced!).
- Buttons used to need a 3D appearance to be perceived as such. We gradually evolved such that any rectangle around text is perceived as a button, even if it is entirely flat (though research shows that they are still less effective).
Could it be that the new GitHub comment UI is the beginning of a new convention? It’s possible, but the odds are slim. For new conventions to become established, they need to be widespread. Links, buttons, website logos are present on any website, so users get plenty of exposure to any evolution in their design. Similarly, multiline text fields and tabs are very commonplace UI elements. However, their combination is far less common. Even if every tabbed text field on the Web begun using the exact same design, the average user would still not get enough exposure to internalize it.
UX Stockholm Syndrome
It is entirely possible that I’m overestimating the impact of this on GitHub users. After all, I have not done user testing on it, so I’m basing my opinion on my own experience, and on what I’ve learned about usability spending the better part of the last decade at MIT teaching it and doing a PhD on it.
I wondered if it could be an A/B test, so I asked Chris to show me what UI he was seeing. He was also seeing the new UI, but interestingly he expressed frustration about being unable to tell where the text field actually is, and where he can type even before I told him about this article. Whether or not it’s not an A/B test, I’m really hoping that GitHub is collecting enough metrics so they can evaluate the impact of this design on user experience at scale.
As for me, I take comfort in knowing that when there is no alternative, users can eventually adapt to any UI, no matter how poor, so I will at some point get used to it. Airplane cockpits are the canonical example here, but this is commonly seen in UIs of a lot of enterprise software (though the wind of change is blowing straight into the face of enterprise UX).
Our life is rife with examples of poor usability, to the point where if something is easy to use, people are often surprised. There is even what some of us call “UX Stockholm Syndrome”: after very prolonged exposure to a poor interface, users start believing that it is easy to use, and even advocate against improvements. The curse of knowledge makes them forget how difficult it was to learn, and the prolonged exposure can even make them efficient at using it.
Take hex colors for example. Quick, what color is #7A6652?
Learning to mentally translate between hex color notation and actual visible colors takes years of practice.
Hex notation was never designed for humans; it was designed for machines, as a compact way to represent the 3 bytes of RGB channels of earlier screens.
Humans do not think of colors as combinations of lights.
It’s not logical that to make brown you combine some red, a bit less green, and even less blue.
That is neither how we think about color, nor does it relate to any of our real-world color mixing experiences.
There are several color models with a more human-centered design, such as HSL, LCH, OKLCH.
Their coordinates are designed around how humans describe colors,
such as hue for the main color (e.g. red, yellow, green, etc.), chroma/saturation to specify how intense the color is (e.g. 0 would be gray), and lightness to specify how light it is (e.g. white would be 100% and black would be 0%).
Yet, it’s common to see the kinds of people who have had very prolonged exposure to this notation (e.g. web designers) not only prefer it, but even try to sing its praises!
Another example, entirely outside of software, is music notation. You’ve likely learned it as a child, so it’s hard to remember what the learning experience was like, and if you regularly read music sheets, you may even believe it’s easy. But if we try to step back and examine it objectively, it’s highly unintuitive.
Expanding on this would take a whole other article, but I will just give one example. Take a look at the symbols for notes and pauses:
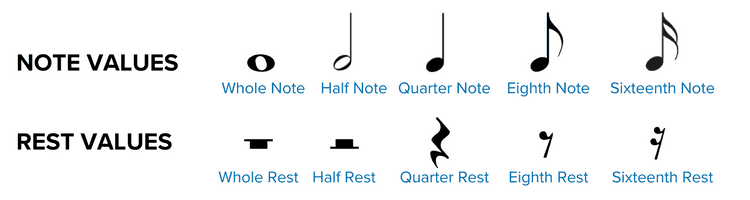
Image courtesy of Musicnotes
There is not only an ordering here, but successive symbols even have a fixed ratio of 2. Yet absolutely nothing in their representation signifies this. Nothing in the depiction of ♩ indicates that it is longer than ♪, let alone that it is double the length. You just have to learn it. Heck, there’s nothing even indicating whether a symbol produces sound or not! Demanding a lot of knowledge in the head is not a problem in itself; it’s a common tradeoff when efficiency is higher priority than learnability. E.g. the alphabet is also a set of arbitrary symbols we need to learn to be able to form words. But even the best tradeoff is worse than none, aka having your cake and eating it too beats both options. Was a tradeoff really necessary here? Was there really no possible depiction of these symbols that could communicate their purpose, order, and ratios? Or at least a notation that was memorable by association rather than straight memorization?
Update: GitHub’s response (Nov 20th, 2023)
This post resonated a lot with people on social media. Here are some selected responses:
Selected Social Media Replies
https://twitter.com/jitl/status/1720272221149581493
https://twitter.com/noeldevelops/status/1724509073964487056
https://twitter.com/zisiszikos/status/1720157900620939519
https://twitter.com/manuelmeister/status/1720147908731818249
@leaverou @github I really thought the page was broken or incompletely loaded until I saw it enough times to try typing in it. It’s emotionally uncomfortable to type in, fighting how it looks vs. what I know it is. — Benjamin @hazula@hachyderm.io, Nov 3rd, 2023
The Primer team at GitHub reached out to me to discuss the issue, and I was happy to see that they were very receptive to feedback. They then iterated, and came up with a new design that communicates purpose much better, even if less minimalistic:
https://twitter.com/natalyathree/status/1729161513636884499
@leaverou @github thank you for this post. We have shipped improvements to make it easier again to identify the textarea and distinguish between Write and Preview. — Daniel Adams (@dipree@mastodon.social), Nov 20th, 2023
Always great to see an org that is receptive to feedback!
State of HTML 2023 now open!
tl;dr the brand new State of HTML survey is finally open!
Take State of HTML 2023 Survey
Benefits to you:
- Survey results are used by browsers to prioritize roadmaps — the reason Google is funding this. Time spent thoughtfully filling them out is an investment that can come back to you tenfold in the form of seeing features you care about implemented, browser incompatibilities being prioritized, and gaps in the platform being addressed.
- In addition to browsers, several standards groups are also using the results for prioritization and decision-making.
- Learn about new and upcoming features you may have missed; add features to your reading list and get a list of resources at the end!
- Get a personalized score and see how you compare to other respondents
- Learn about the latest trends in the ecosystem and what other developers are focusing on
While the survey will be open for 3 weeks, responses entered within the first 9 days (until October 1st) will have a much higher impact on the Web, as preliminary data will be used to inform Interop 2024 proposals.
![]()
The State of HTML logo, designed by Chris Kirk-Nielsen, who I think surpassed himself with this one!
Background
This is likely the most ambitious Devographics survey to date. For the past couple of months, I’ve been hard at work leading a small product team spread across three continents (2am to 8am became my second work shift 😅). We embarked on this mission with some uncertainty about whether there were enough features for a State of HTML survey, but quickly found ourselves with the opposite problem: there were too many, all with good reasons for inclusion! To help weigh the tradeoffs and decide what makes the cut we consulted both the developer community, as well as stakeholders across browsers, standards groups, community groups, and more.
We even designed new UI controls to facilitate collecting the types of complex data that were needed without making the questions too taxing, and did original UX research to validate them. Once the dust settles, I plan to write separate blog posts about some of these.
FAQ
Can I edit my responses?
Absolutely! Do not worry about filling it out perfectly in one go. If you create an account, you can edit your responses for the whole period the survey is open, and even split filling it out across multiple devices (e.g. start on your phone, then fill out some on your desktop, etc.) Even if you’re filling it out anonymously, you can still edit responses on your device for a while. You could even start anonymously and create an account later, and your responses will be preserved (the only issue is filling it out anonymously, then logging in with an existing account).
So, perhaps the call to action above should be…
Start State of HTML 2023 Survey
Why are there JS questions in an HTML survey?
For the same reason there are JS APIs in the HTML standard: many JS APIs are intrinsically related to HTML. We mainly included JS APIs in the following areas:
- APIs used to manipulate HTML dynamically (DOM, form validation, etc.)
- Web Components APIs, used to create custom HTML elements
- APIs used to create web apps that feel like native apps (e.g. Service Workers, Web App Manifest, etc.)
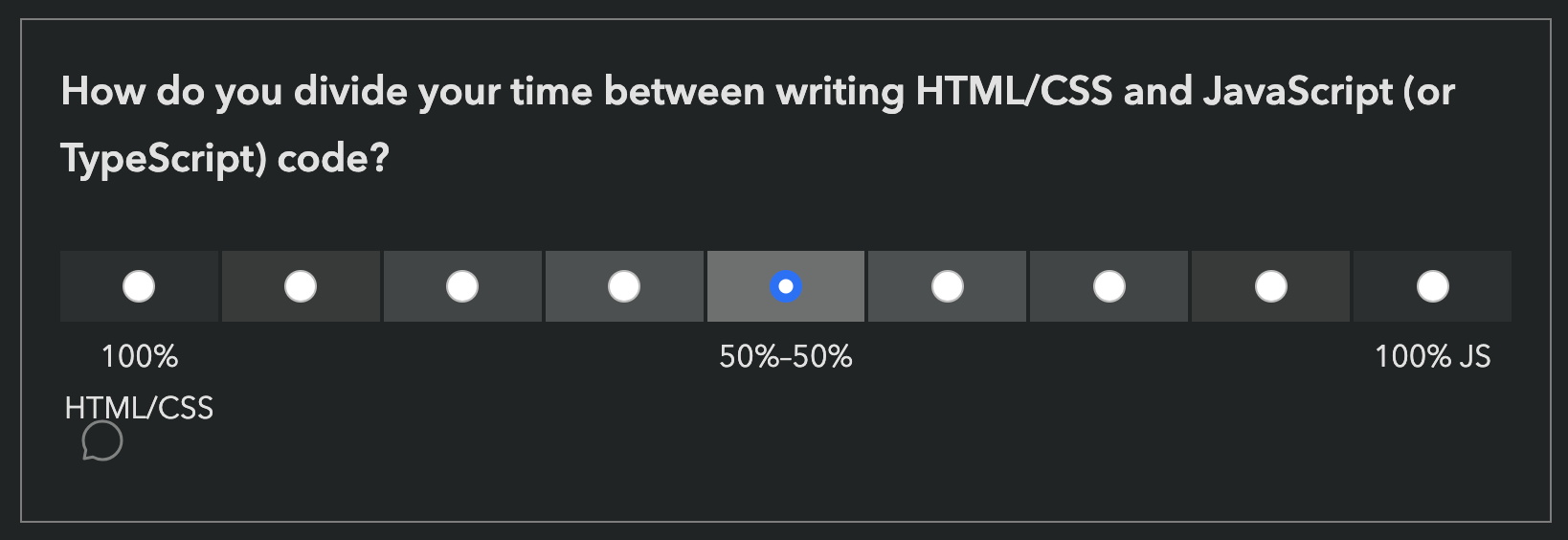
If you don’t write any JS, we absolutely still want to hear from you! In fact, I would encourage you even more strongly to fill out the survey: we need to hear from folks who don’t write JS, as they are often underrepresented. Please feel free to skip any JS-related questions (all questions are optional anyway) or select that you have never heard these features. There is a question at the end, where you can select that you only write HTML/CSS:
Is the survey only available in English?
Absolutely not! Localization has been an integral part of these surveys since the beginning. Fun fact: Nobody in the core State of HTML team is a native English speaker.

Each survey gets (at least partially) translated to over 30 languages.
However, since translations are a community effort, they are not necessarily complete, especially in the beginning. If you are a native speaker of a language that is not yet complete, please consider helping out!
What does my score mean?
Previous surveys reported score as a percentage: “You have heard or used X out of Y features mentioned in the survey”. This one did too at first:
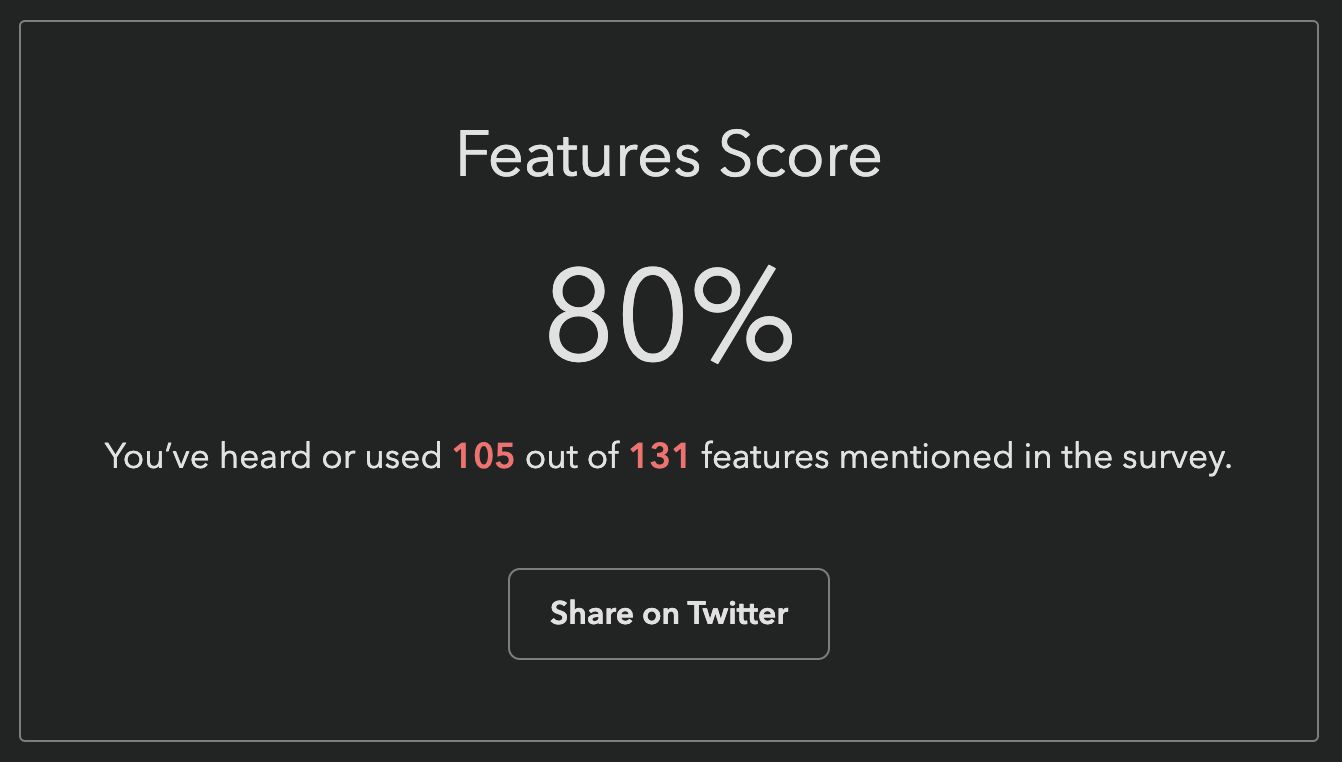
This was my own score when the survey first launched, and I created the darn survey 😅 Our engineer, Sacha who is also the founder of Devographics got 19%!
These were a lot lower for this survey, for two reasons:
- It asks about a lot of cutting edge features, more than the other surveys. As I mentioned above, we had a lot of difficult tradeoffs to make, and had to cut a ton of features that were otherwise a great fit. We err’ed on the side of more cutting edge features, as those are the areas the survey can help make the most difference in the ecosystem.
- To save on space, and be able to ask about more features, we used a new compact format for some of the more stable features, which only asks about usage, not awareness.
Here is an example from the first section of the survey (Forms):
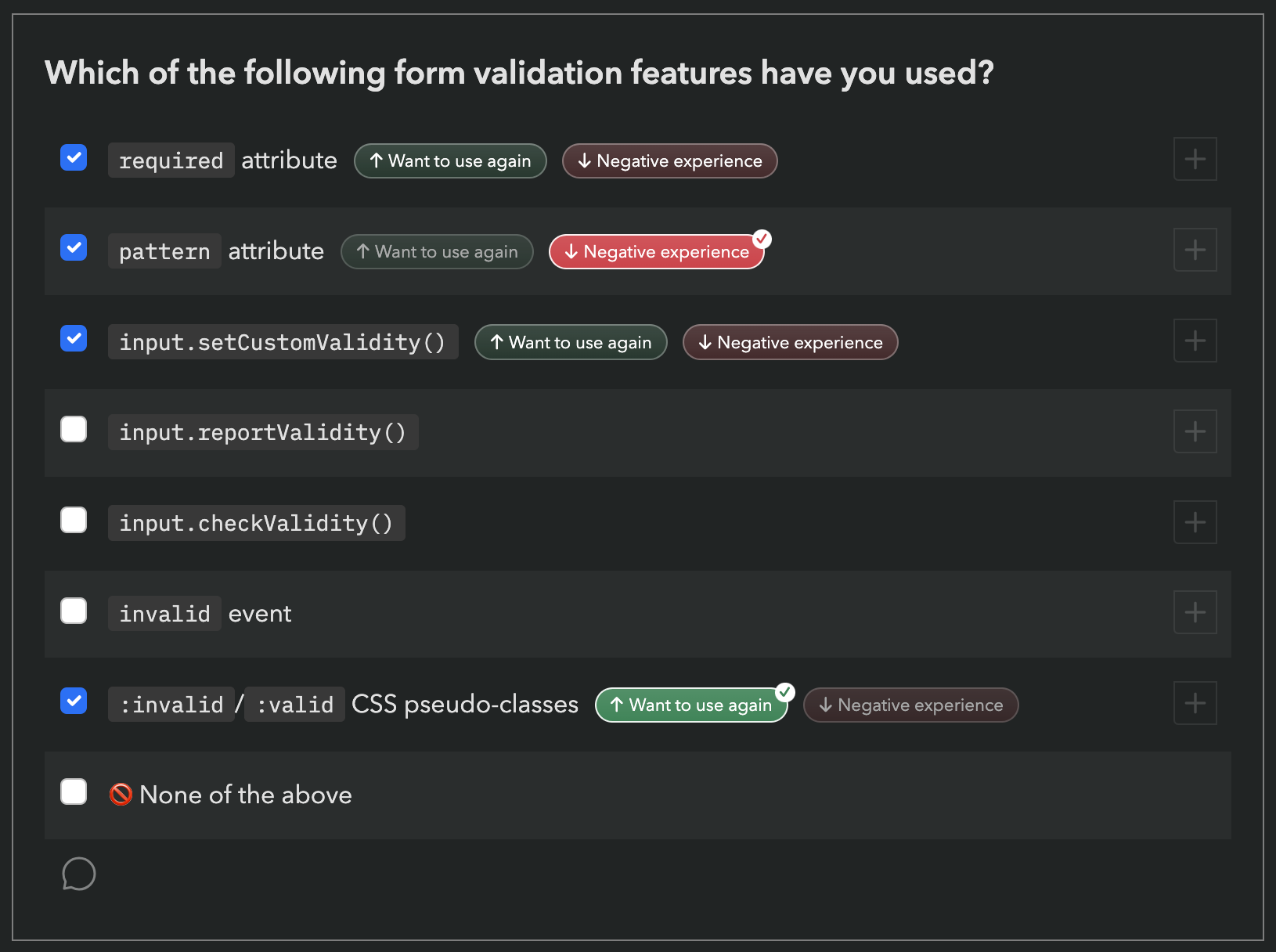 However, this means that if you have never used a feature, it does not count towards your score, even if you have been aware of it for years.
It therefore felt unfair to many to report that you’ve “heard or used” X% of features, when there was no way to express that you have heard 89 out of 131 of them!
However, this means that if you have never used a feature, it does not count towards your score, even if you have been aware of it for years.
It therefore felt unfair to many to report that you’ve “heard or used” X% of features, when there was no way to express that you have heard 89 out of 131 of them!
To address this, we changed the score to be a sum of points, a bit like a video game: each used feature is worth 10 points, each known feature is worth 5 points.
Since the new score is harder to interpret by itself and only makes sense in comparison to others, we also show your rank among other participants, to make this easier.
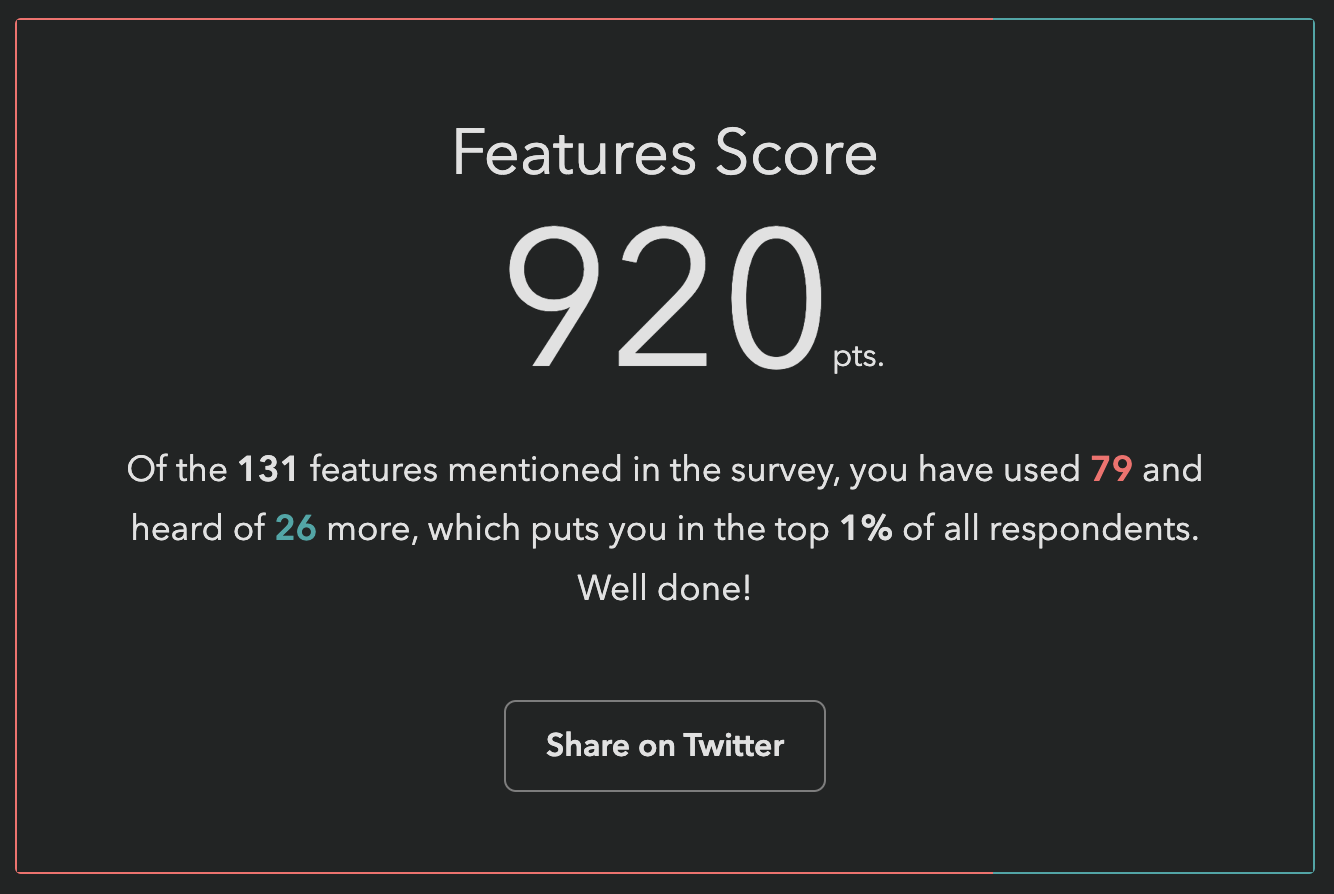
My score after the change. If you have already taken the survey, you can just revisit it (with the same device & browser if filled it in anonymously) and go straight to the finish page to see your new score and ranking!
I found a bug, what should I do?
Please file an issue so we can fix it!
Acknowledgements
This survey would not have been possible without the hard work of many people. Besides myself (Lea Verou), this includes the rest of the team:
- Engineering team: Sacha Greif, Eric Burel
- UX research & data science team: Shaine Rosewel Matala, Michael Quiapos, Gio Vernell Quiogue
- Our logo designer, Chris Kirk-Nielsen
And several volunteers:
- Léonie Watson for accessibility feedback
- Our usability testing participants
- …and all folks who provided early feedback throuhgout the process
Last but not least, Kadir Topal made the survey possible in the first place, by proposing it and securing funding from Google.
Thank you all! 🙏🏼
Press coverage (selected)
- Turns out I know less about HTML than I thought! 😅 - Kevin Powell (Video)
- Are you an HTML expert? Find out with the new State of HTML 2023 survey - dev.to
- Chris’ Corner: Things I Totally Didn’t Know About That I Learned From Taking the State of HTML 2023 Survey
- Frontend Focus
- CSS Weekly
- The HTML Blog
Numbers or Brackets for numeric questions?
As you may know, this summer I am leading the design of the inaugural State of HTML survey. Naturally, I am also exploring ways to improve both survey UX, as well as all questions.
Shaine Madala, a data scientist working on the survey design team proposed using numerical inputs instead of brackets for the income question. While I was initially against it, I decided to explore this a bit further, which changed my opinion.
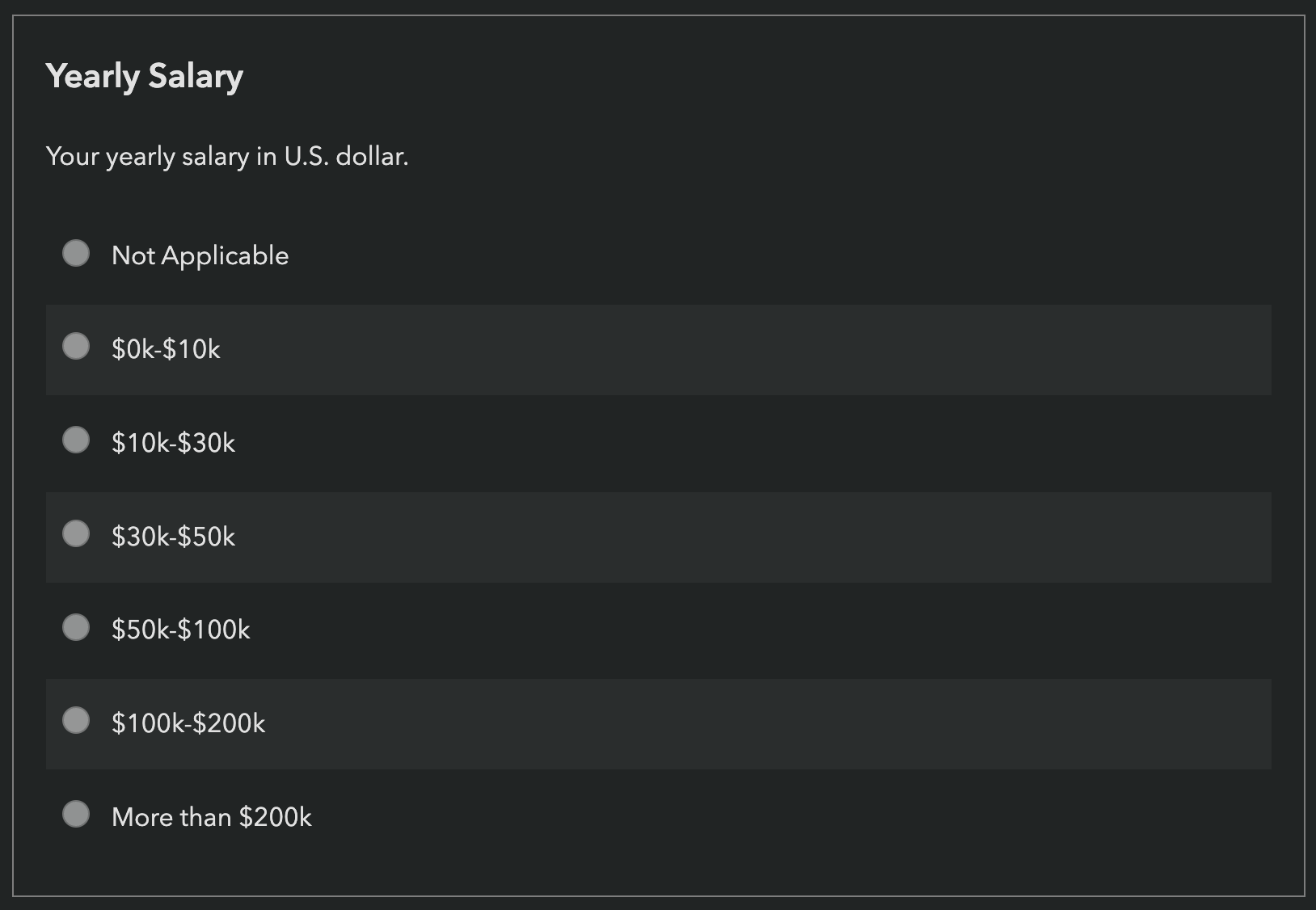
There are actually four demographics questions in State of X surveys where the answer is essentially a number, yet we ask respondents to select a bracket: age, years of experience, company size, and income.
The arguments for brackets are:
- They are more privacy preserving for sensitive questions (e.g. people may feel more comfortable sharing an income bracket than their actual income)
- They are more efficient to input (one click vs homing to keyboard and hitting several keystrokes).
- In some cases respondents may not know the precise number offhand (e.g. company size)
The arguments for numerical input are:
- Depending on the specifics, these can actually be faster to answer overall since they involve lower cognitive overhead (for known numbers).
- The brackets are applied at the analysis stage, so they can be designed to provide a better overview of the dataset
- More elaborate statistics can be computed (e.g. averages, medians, stdevs, the sky is the limit)
Which one is faster?
We can actually calculate this! Average reading speed for non-fiction is around 240 wpm (= 250ms/word) [1] Therefore, we can approximate reading time for each question by multiplying number of brackets × average words per bracket (wpb) × 250ms.
However, this assumes the respondent reads all brackets from top to bottom, but this is a rare worst case scenario. Usually they stop reading once they find the bracket that matches their answer, and they may even skip some brackets, performing a sort of manual binary search. We should probably halve these times to get a more realistic estimate.
Average typing speed is 200 cpm [2] (≈ 300ms/character). This means we can approximate typing time for each question by multiplying the number of digits on average × 300ms.
Let’s see how this works out for each question:
| Question | Brackets | WPB | Reading time | Avg Digits | Typing time |
|---|---|---|---|---|---|
| Age | 8 | 4 | 4s | 2 | 0.6s |
| Years of Experience | 6 | 4 | 3s | 2 | 0.6s |
| Company size | 9 | 4 | 4.5s | 3 | 0.9s |
| Income | 7 | 2 | 1.75s | 5 | 1.5s |
As you can see, despite our initial intuition that brackets are faster, the time it takes to read each bracketed question vastly outweighs typing time for all questions!
Of course, this is a simplification. There are models in HCI, such as KLM that can more accurately estimate the time it takes for certain UI flows. We even taught some of these to MIT students in 6.813, as well as its successor.
For example, here are some of the variables we left out in our analysis above:
- When answering with numerical input, most users need to home from mouse to keyboard, which takes time (estimated as 0.4s in KLM) and then focus the input so they can write in it, which takes an additional click (estimated as 0.2s in KLM)
- When answering with brackets, users need to move the mouse to the correct bracket, which takes time (KLM estimates all pointing tasks as a flat 1.1s, but this can be more accurately estimated using Fitts’ Law)
- We are assuming that the decision is instantaneous, but doing the mental math of comparing the number in your head to the bracket numbers also takes time.
However, given the vast difference in times, I don’t think a more accurate model would change the conclusion much.
Note that this analysis is based on a desktop interface, primarily because it’s easier (most of these models were developed before mobile was widespread, e.g. KLM was invented in 1978!) Mobile would require a separate calculation taking into account the specifics of mobile interaction (e.g. the time it takes for the keyboard to pop up), though the same logic applies. (thanks Tim for this exellent question!)
What about sliders?
Sliders are uncommon in surveys, and for good reason. They offer the most benefit in UIs where changes to the value provide feedback, and allow users to iteratively approach the desired value by reacting to this feedback. For example:
- In a color picker, the user can zero in to the desired coordinates iteratively, by seeing the color change in real time
- In a video player, the user can drag the slider to the right time by getting feedback about video frames.
- In searches (e.g. for flights), dragging the slider updates the results in real time, allowing the user to gradually refine their search with suitable tradeoffs
In surveys, there is usually no feedback, which eliminates this core benefit.
When the number is known in advance, sliders are usually a poor choice, except when we have very few numbers to choose among (e.g. a 1-5 rating) and the slider UI makes it very clear where to click to select each of them, or we don’t much care about the number we select (e.g. search flights by departure time).[3] None of our demographics questions falls in this category (unless bracketed, in which case why not use regular brackets?).
There are several reasons for this:
- It is hard to predict where exactly to click to select the desired number. The denser the range, the harder it is.
- Even if you know where to click, it’s hard to do so on mobile
- Dragging a slider on desktop is generally slower than typing the number outright.[4]
<input type=number> all the things?
Efficiency is not the only consideration here. Privacy is a big one. These surveys are anonoymous, but respondents are still often concerned about entering data they consider sensitive. Also, for the efficiency argument to hold true, the numerical answer needs to be top of mind, which is not always the case.
I summarize my recommendations below.
Age
This is a two digit number, that is always top of mind. Number input.
Years of experience
This is a 1-2 digit number, and it is either top of mind, or very close to it. Number input.
Company size
While most people know their rough company size, they very rarely would be able to provide an exact number without searching. This is a good candidate for brackets. However, the number of brackets should be reduced from the current 9 (does the difference between 2-5 and 6-10 employees really matter?), and their labels should be copyedited for scannability.
We should also take existing data into account. Looking at the State of CSS 2022 results for this question, it appears that about one third of respondents work at companies with 2-100 people, so we should probably not combine these 5 brackets into one, like I was planning to propose. 101 to 1000 employees is also the existing bracket with the most responses (15.1%), so we could narrow it a little, shifting some of its respondents to the previous bracket.
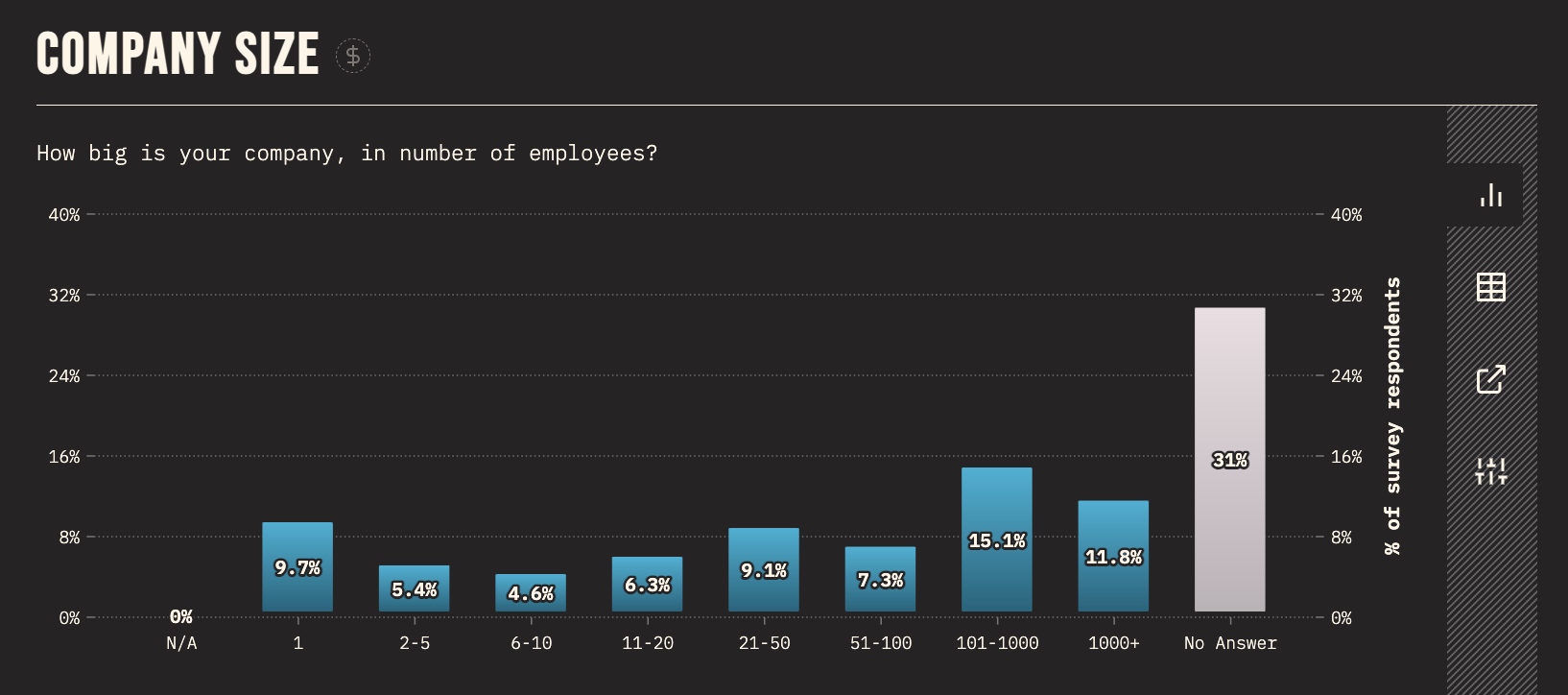
Taking all these factors into consideration, I proposed the following brackets:
- Just me!
- Small (2 - 50)
- Medium (51 - 200)
- Large (201 - 1000)
- Very Large (1000+)
Income
The question that started it all is unfortunately the hardest.
Income is a number that people know (or can approximate). It is faster to type, but only marginally (1.75s vs 1.5s). We can however reduce the keystrokes further (from 1.5s to 0.6s on average) by asking people to enter thousands.
The biggest concern here is privacy. Would people be comfortable sharing a more precise number? We could mitigate this somewhat by explicitly instructing respondents to round it further, e.g. to the nearest multiple of 10:
What is your approximate yearly income (before taxes)? Feel free to round to the nearest multiple of 10 if you are not comfortable sharing an exact number. If it varies by year, please enter an average.
However, this assumes that the privacy issues are about granularity, or about the number being too low (rounding to 10s could help with both). However, David Karger made an excellent point in the comments, that people at the higher income brackets may also be reluctant to share their income:
I don’t think that rounding off accomplishes anything. It’s not the least significant digit that people care about, but the most significant digit. This all depends on who they imagine will read the data of course. But consider some techy earnings, say 350k. That’s quite a generous salary and some people might be embarrassed to reveal their good fortune. Rounding it to 300k would still be embarrassing. On the other hand, a bracket like 150 to 500 would give them wiggle room to say that they’re earning a decent salary without revealing that they’re earning a fantastic one. I don’t have immediate insight into what brackets should be chosen to give people the cover they need to be truthful, but I think they will work better for this question.
Another idea was to offer UI that lets users indicate that the number they have entered is actually an upper or lower bound.
What is your approximate yearly income (before taxes)?
Of course, a dropdown PLUS a number input is much slower than using brackets, but if only a tiny fraction of respondents uses it, it does not affect the analysis of the average case.
However, after careful consideration and input, both qualitative and quantitative, it appears that privacy is a much bigger factor than I had previously realized. Even though I was aware that people see income level as sensitive data (more so in certain cultures than others), I had not fully realized the extent of this. In the end, I think the additional privacy afforded by brackets far outweighs any argument for efficiency or data analysis convenience.
Conclusion
I’m sure there is a lot of prior art on the general dilemma on numerical inputs vs brackets, but I wanted to do some analysis with the specifics of this case and outline an analytical framework for answering these kinds of dilemmas.
That said, if you know of any relevant prior art, please share it in the comments! Same if you can spot any flaws in my analysis or recommendations.
You could also check out the relevant discussion as there may be good points there.
https://www.sciencedirect.com/science/article/abs/pii/S0749596X19300786 ↩︎
KLM is a poor model for dragging tasks for two reasons: First, it regards dragging as simply a combination of three actions: button press, mouse move, button release. But we all know from experience that dragging is much harder than simply pointing, as managing two tasks simultaneously (holding down the mouse button and moving the pointer) is almost always harder than doing them sequentially. Second, it assumes that all pointing tasks have a fixed cost (1.1s), which may be acceptable for actual pointing tasks, but the inaccuracy is magnified for dragging tasks. A lot of HCI literature (and even NNGroup) refers to the Steering Law to estimate the time it takes to use a slider, however modern sliders (and scrollbars) do not require steering, as they are not constrained to a single axis: once dragging is initiated, moving the pointer in any direction adjusts the slider, until the mouse button is released. Fitts Law actually appears to be a better model here, and indeed there are many papers extending it to dragging. However, evaluating this research is out of scope for this post. ↩︎