Reading List
The most recent articles from a list of feeds I subscribe to.
Developer priorities throughout their career
I made this chart in the amazing Excalidraw about two weeks ago:
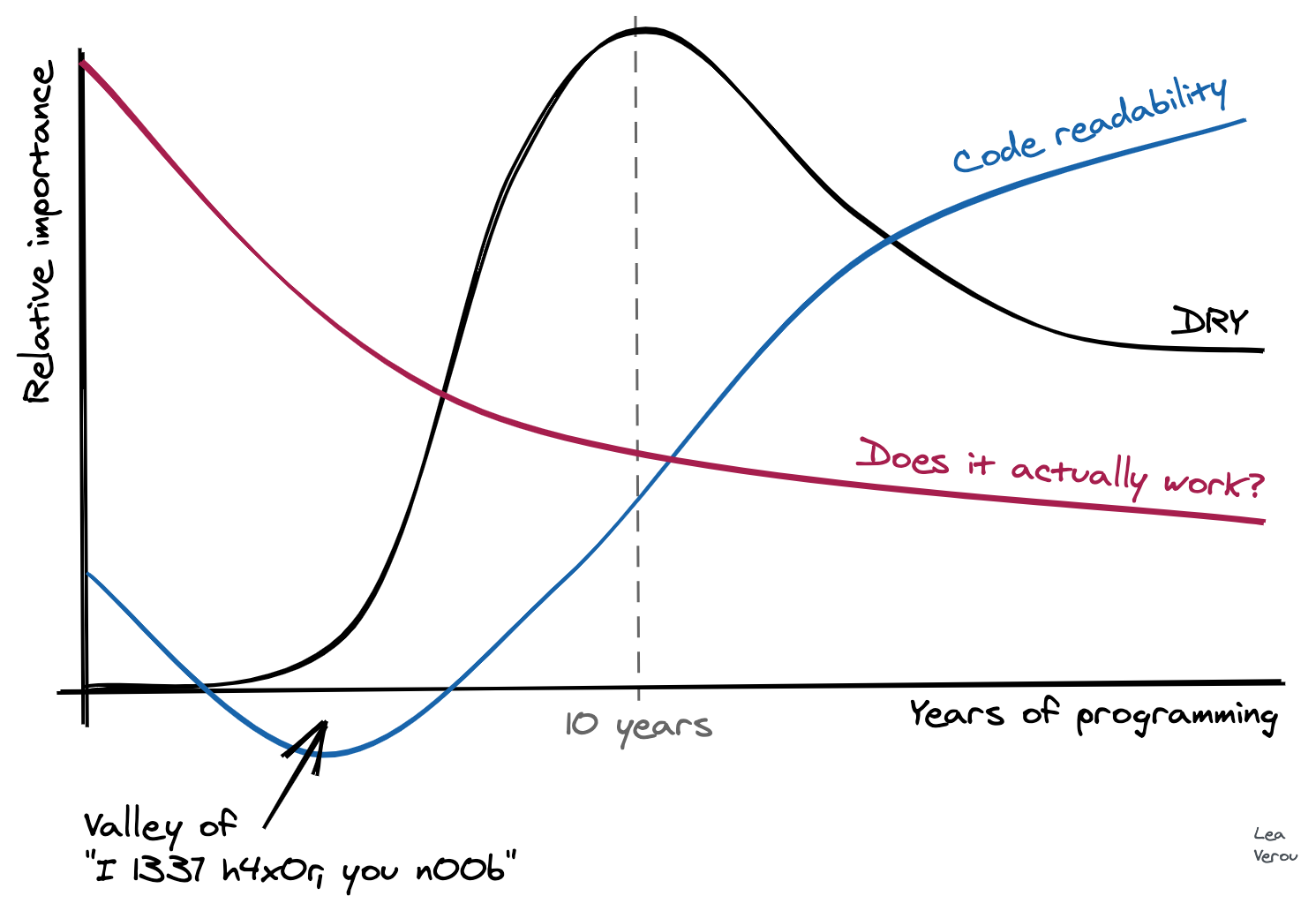
It only took me 10 minutes! Shortly after, my laptop broke down into repeated kernel panics, and it spent about 10 days in service (I was in a remote place when it broke, so it took some time to get it to service). Yesterday, I was finally reunited with it, turned it on, launched Chrome, and saw it again. It gave me a smile, and I realized I never got to post it, so I tweeted this:
https://twitter.com/LeaVerou/status/1306001020636540934
The tweet kinda blew up! It seems many, many developers identify with it. A few also disagreed with it, especially with the “Does it actually work?” line. So I figured I should write a bit about the rationale behind it. I originally wrote it in a tweet, but then I realized I should probably post it in a less transient medium, that is more well suited to longer text.
When somebody starts coding, getting the code to work is already difficult enough, so there is no space for other priorities. Learning to formalize one’s thought to the degree a computer demands, and then serialize this thinking with an unforgiving syntax, is hard. Writing code that works is THE priority, and whether it’s good code is not even a consideration.
For more experienced programmers, whether it works is ephemeral: today it works, tomorrow a commit causes a regression, the day after another commit fixes it (yes, even with TDD. No testsuite gets close to 100% coverage). Whereas readability & maintainability do not fluctuate much. If they are not prioritized from the beginning, they are much harder to accomplish when you already have a large codebase full of technical debt.
Code written by experienced programmers that doesn’t work, can often be fixed with hours or days of debugging. A nontrivial codebase that is not readable can take months or years to rewrite. So one tends to gravitate towards prioritizing what is easier to fix.
The “peak of drought” and other over-abstractions
Many developers identified with the “peak of drought”. Indeed, like other aspects of maintainability, DRY is not even a concern at first. At some point, a programmer learns about the importance of DRY and gradually begins abstracting away duplication. However, you can have too much of a good thing: soon the need to abstract away any duplication becomes all consuming and leads to absurd, awkward abstractions which actually get in the way and produce needless couplings, often to avoid duplicating very little code, once. In my own “peak of drought” (which lasted far longer than the graph above suggests), I’ve written many useless functions, with parameters that make no sense, just to avoid duplicating a few lines of code once.
Many articles have been written about this phenomenon, so I’m not going to repeat their arguments here. As a programmer accumulates even more experience, they start seeing the downsides of over-abstraction and over-normalization and start favoring a more moderate approach which prioritizes readability over DRY when they are at odds.
A similar thing happens with design patterns too. At some point, a few years in, a developer reads a book or takes a course about design patterns. Soon thereafter, their code becomes so littered with design patterns that it is practically incomprehensible. “When all you have is a hammer, everything looks like a nail”. I have a feeling that Java and Java-like languages are particularly accommodating to this ailment, so this phenomenon tends to proliferate in their codebases. At some point, the developer has to go back to their past code, and they realize themselves that it is unreadable. Eventually, they learn to use design patterns when they are actually useful, and favor readability over design patterns when the two are at odds.
What aspects of your coding practice have changed over the years? How has your perspective shifted? What mistakes of the past did you eventually realize?
Developer priorities throughout their career
I made this chart in the amazing Excalidraw about two weeks ago:
It only took me 10 minutes! Shortly after, my laptop broke down into repeated kernel panics, and it spent about 10 days in service (I was in a remote place when it broke, so it took some time to get it to service). Yesterday, I was finally reunited with it, turned it on, launched Chrome, and saw it again. It gave me a smile, and I realized I never got to post it, so I tweeted this:
https://twitter.com/LeaVerou/status/1306001020636540934
The tweet kinda blew up! It seems many, many developers identify with it. A few also disagreed with it, especially with the “Does it actually work?” line. So I figured I should write a bit about the rationale behind it. I originally wrote it in a tweet, but then I realized I should probably post it in a less transient medium, that is more well suited to longer text.
When somebody starts coding, getting the code to work is already difficult enough, so there is no space for other priorities. Learning to formalize one’s thought to the degree a computer demands, and then serialize this thinking with an unforgiving syntax, is hard. Writing code that works is THE priority, and whether it’s good code is not even a consideration.
For more experienced programmers, whether it works is ephemeral: today it works, tomorrow a commit causes a regression, the day after another commit fixes it (yes, even with TDD. No testsuite gets close to 100% coverage). Whereas readability & maintainability do not fluctuate much. If they are not prioritized from the beginning, they are much harder to accomplish when you already have a large codebase full of technical debt.
Code written by experienced programmers that doesn’t work, can often be fixed with hours or days of debugging. A nontrivial codebase that is not readable can take months or years to rewrite. So one tends to gravitate towards prioritizing what is easier to fix.
The “peak of drought” and other over-abstractions
Many developers identified with the “peak of drought”. Indeed, like other aspects of maintainability, DRY is not even a concern at first. At some point, a programmer learns about the importance of DRY and gradually begins abstracting away duplication. However, you can have too much of a good thing: soon the need to abstract away any duplication becomes all consuming and leads to absurd, awkward abstractions which actually get in the way and produce needless couplings, often to avoid duplicating very little code, once. In my own “peak of drought” (which lasted far longer than the graph above suggests), I’ve written many useless functions, with parameters that make no sense, just to avoid duplicating a few lines of code once.
Many articles have been written about this phenomenon, so I’m not going to repeat their arguments here. As a programmer accumulates even more experience, they start seeing the downsides of over-abstraction and over-normalization and start favoring a more moderate approach which prioritizes readability over DRY when they are at odds.
A similar thing happens with design patterns too. At some point, a few years in, a developer reads a book or takes a course about design patterns. Soon thereafter, their code becomes so littered with design patterns that it is practically incomprehensible. “When all you have is a hammer, everything looks like a nail”. I have a feeling that Java and Java-like languages are particularly accommodating to this ailment, so this phenomenon tends to proliferate in their codebases. At some point, the developer has to go back to their past code, and they realize themselves that it is unreadable. Eventually, they learn to use design patterns when they are actually useful, and favor readability over design patterns when the two are at odds.
What aspects of your coding practice have changed over the years? How has your perspective shifted? What mistakes of the past did you eventually realize?
Parsel: A tiny, permissive CSS selector parser
Parsel: A tiny, permissive CSS selector parser
Parsel: A tiny, permissive CSS selector parser
I’ve posted before about my work for the Web Almanac this year. To make it easier to calculate the stats about CSS selectors, we looked to use an existing selector parser, but most were too big and/or had dependencies or didn’t account for all selectors we wanted to parse, and we’d need to write our own walk and specificity methods anyway. So I did what I usually do in these cases: I wrote my own!
You can find it here: https://projects.verou.me/parsel/
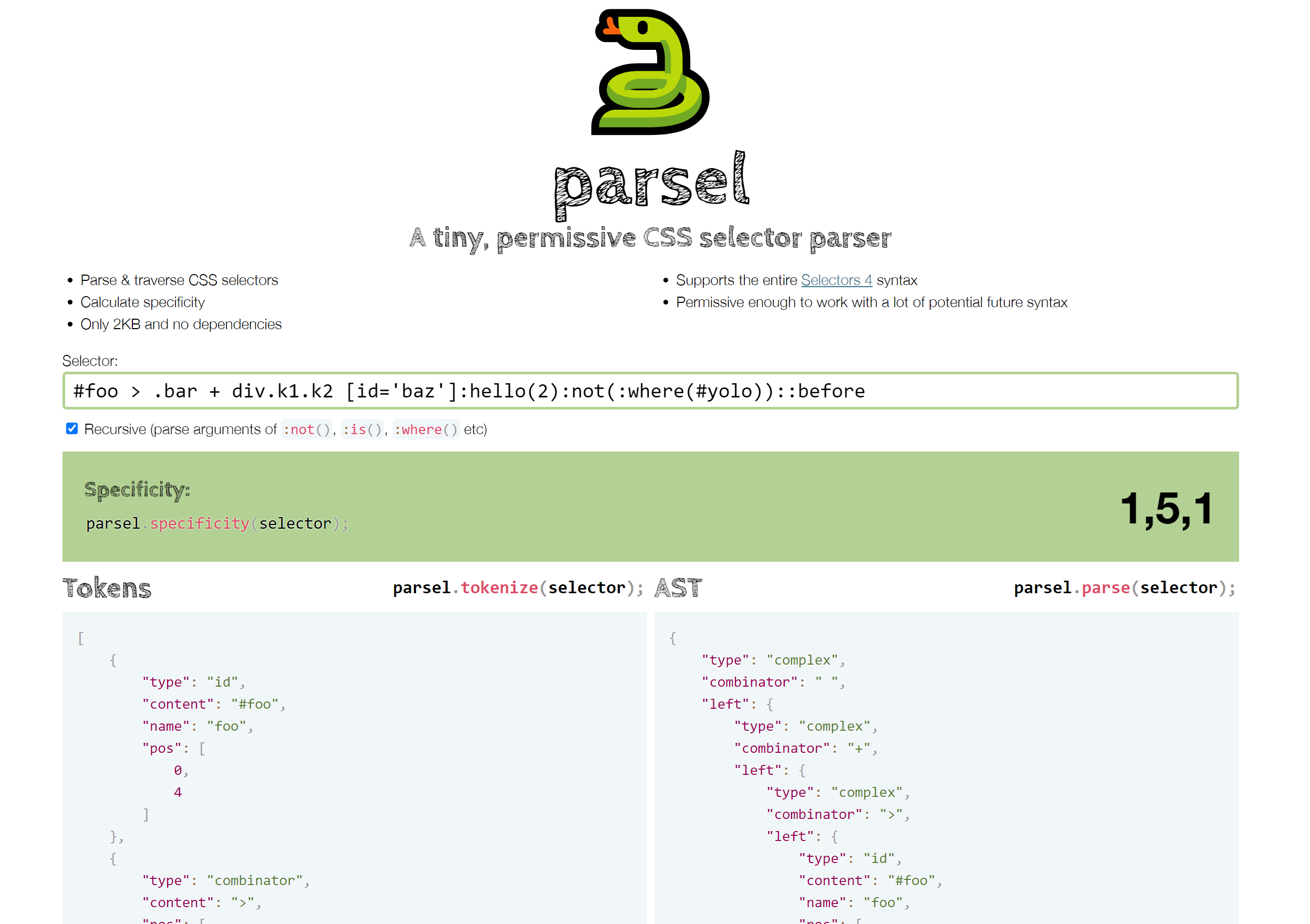
It not only parses CSS selectors, but also includes methods to walk the AST produced, as well as calculate specificity as an array and convert it to a number for easy comparison.
It is one of my first libraries released as an ES module, and there are instructions about both using it as a module, and as a global, for those who would rather not deal with ES modules yet, because convenient as ESM are, I wouldn’t want to exclude those less familiar with modern JS.
Please try it out and report any bugs! We plan to use it for Almanac stats in the next few days, so if you can spot bugs sooner rather than later, you can help that volunteer effort. I’m primarily interested in (realistic) valid selectors that are parsed incorrectly. I’m aware there are many invalid selectors that are parsed weirdly, but that’s not a focus (hence the “permissive” aspect, there are many invalid selectors it won’t throw on, and that’s by design to keep the code small, the logic simple, and the functionality future-proof).
How it works
If you’re just interested in using this selector parser, read no further. This section is about how the parser works, for those interested in this kind of thing. :)
I first started by writing a typical parser, with character-by-character gobbling and different modes, with code somewhat inspired by my familiarity with jsep. I quickly realized that was a more fragile approach for what I wanted to do, and would result in a much larger module. I also missed the ease and flexibility of doing things with regexes.
However, since CSS selectors include strings and parens that can be nested, parsing them with regexes is a fool’s errand. Nested structures are not regular languages as my CS friends know. You cannot use a regex to find the closing parenthesis that corresponds to an opening parenthesis, since you can have other nested parens inside it. And it gets even more complex when there are other tokens that can nest, such as strings or comments. What if you have an opening paren that contains a string with a closing paren, like e.g. ("foo)")? A regex would match the closing paren inside the string. In fact, parsing the language of nested parens (strings like (()(()))) with regexes is one of the typical (futile) exercises in a compilers course. Students struggle to do it because it’s an impossible task, and learn the hard way that not everything can be parsed with regexes.
Unlike a typical programming language with lots of nested structures however, the language of CSS selectors is more limited. There are only two nested structures: strings and parens, and they only appear in specific types of selectors (namely attribute selectors, pseudo-classes and pseudo-elements). Once we get those out of the way, everything else can be easily parsed by regexes. So I decided to go with a hybrid approach: The selector is first looked at character-by-character, to extract strings and parens. We only extract top-level parens, since anything inside them can be parsed separately (when it’s a selector), or not at all. The strings are replaced by a single character, as many times as the length of the string, so that any character offsets do not change, and the strings themselves are stored in a stack. Same with parens.
After that point, this modified selector language is a regular language that can be parsed with regexes. To do so, I follow an approach inspired by the early days of Prism: An object literal of tokens in the order they should be matched in, and a function that tokenizes a string by iteratively matching tokens from an object literal. In fact, this function was taken from an early version of Prism and modified.
After we have the list of tokens as a flat array, we can restore strings and parens, and then nest them appropriately to create an AST.
Also note that the token regexes use the new-ish named capture groups feature in ES2018, since it’s now supported pretty widely in terms of market share. For wider support, you can transpile :)