Reading List
The most recent articles from a list of feeds I subscribe to.
Do we need an Interop for assistive technologies?
I'm so happy about what Interop 2022 is doing for web compatibility in general. It made me think: what if we had something similar, but accessibility-specific, focused on compatibility between our code, assistive technologies and browsers? Excitingly, ARIA-AT pretty much has that goal.
Interop 2022 is great
In the Interop 2022 effort, all major browser vendors, browser engineers and other stakeholders agreed “to solve the top browsers compatibility issues identified by web developers” in one year. I danced a little when I saw that. I mean, they align their priorities between them and web developers get a say in what the priorities are. Excellent.
Subgrid, <dialog> and scroll-snap are tremendous features, but consistently cross-browser supported subgrid, <dialog> and scroll snap (and more) are the real deal. Because browser compatibility issues can be quite the nuisance. They make web development harder and more expensive. Web developers end up with a choice between either supporting less browsers or adding hacks and more bloated code. Either option likely trickles down to the experience of end users.
Unrecommendable web platform features
As an accessibility specialist, I spend some of my time giving advice on how to code accessible UI components. From time to time, I want to recommend a thing, but I don't, because of bugs or inconsistencies somewhere between browsers and assistive technologies.
I asked on Twitter what people's top issues were:
If you could fix 3 bugs in assistive tech or browsers, to make building accessible UI components more straightforward, what would they be?
Some responses that came in, all browser focused:
- display properties (still) break default semantics (thanks Adrian Roselli for all his work documenting the issues in detail)
- the HTML video player has keyboard accessibility, focus management and screenreader issues in various browsers (see also: Scott Vinkle's post How accessible is the HTML video player? from 2019)
aria-controlsis not or weirdly supported by screenreaders- The expanded state of
details/summaryis not communicated to users of screenreaders in Firefox if the arrow is hidden (as documented by Scott O'Hara in The details and summary elements, again). That's a problem: conveying status to assistive technologies is a core feature of functionality that does visual expanding and collapsing aria-ownsis not supported in Safari (see also: Diego Haz' demo)- Default field validation cannot zoom
Having these issues open for so long hurts web accessibility:
- developers who aren't aware may think that by using the platform they get accessibility by default and unknowingly build something inaccessibly
- developers who are aware may end up adding all sorts of hacky code to fix the issue on their end, which could lead to maintainability issues in the long term and makes accessibility unnecessarily hard
- developers generally will have a greater chance of shipping inaccessible interfaces
On Twitter, people also replied with other interesting ways browsers could improve accessibility, like a browser implemention of “skip to <main>” (as Léonie suggested) or even to any landmark (as Curtis said).
And then there are issues around what browsers do, but (some) accessibility specialists disagree with, like that <dialog>'s focus trap can escape to the browser chrome. I've heard from developers whose accessibility consultants recommended them not to use <dialog in the first place and that's an issue.
I believe in personal responsibility when it comes to building a more accessible web. Teams need to test their work and ensure accessibility. But at the same time, change in the primitives (like browsers and CMSes) is needed and can improve a lot of accessibility at once. All of the above issues are most easily solved by browsers, not individual web developers (see also my earlier post, More accessible defaults, please).
ARIA-AT
If we look beyond just browsers and focus on assistive technologies, an interesting project comes to mind. The W3C's ARIA-AT Community Group has the goal to ensure “assistive technologies work with web code in predictable ways”. The group works on interoperability in four ways (taken from their homepage):
- write tests; they help ensure alignment between how assistive technologies behave, and with that, what users can expect
- run tests across different assistive technologies (currently focused on screenreaders, including JAWS, NVDA and VoiceOver)
- build consensus in the industry
- enable scalable automated testing (for which they are writing a standard, see the AT Driver explainer)
The ARIA-AT explainer video explains why this is so important: “there are hundreds of interpretation issues between screenreaders,” and “the way screenreaders and browsers interpret web code changes all the time”.
I am very excited for this project, it will be super cool to see the test results pop up in places like the ARIA Authoring Practices Guide.
Summing up
It would be great for the web to see browsers prioritise accessibility bugs and align between them on the accessibility aspects of current features like <dialog>, <video>, form validation and aria-controls. Either as part of the regular Interop program, or separately. At the same time, returning to the question I started with: yes, more interop between assistive technologies would be very welcome. Improving how assistive technologies interpret our code is a fantastic goal—I'm excited for the impact ARIA-AT will have.
Originally posted as Do we need an Interop for assistive technologies? on Hidde's blog.
A dialog, a modal and a popup walk into a bar. How are they different?
Concepts of the web platform can sometimes be quite different, yet seem very similar. Semantics, behaviours and characteristics are different things, even if they are sometimes combined into one thing. As a new popup attribute is in the works, this post will go into the differences between dialogs, modals, overlays, popups, disclosures and full screen content. All somewhat related concepts that can seem very similar. Let's dive in!
The thing with words and concepts is that they can mean different things to different people in different places and times. The concepts in this post are no different. I noticed that browsing some older resources, like the WHATWG wiki on dialogs. For clarity, throughout this post, I will refer to the concepts of dialogs, modals and popups as they exist in standards like HTML, CSS and ARIA. The definitions here are meant to align with the relevant specifications first and foremost, and with individual team's naming conventions second.
Below, we'll start with a bunch of characteristics: things components can have, like modality, light dismiss, top layer presence and backdrops. Then we'll talk about what we get when these characteristics are used together: dialogs, popups and disclosures.
The characteristics
Light vs explicit dismiss
One major difference between these components is in how users would dismiss them and whether that is affected by other elements.
‘Light dismiss’ is the main feature that popups bring to the table, you only get it when you make an element a popup.
Modality / inertness
The web platform has this concept of content being ‘inert’: it means that you cannot interact with the content. It is only really there visually, but you can’t do anything with it.
When an element is in a modal state, it is the only thing that can be interacted rest with and the rest of the page or application should be inert. You should not be able to tab to anything outside of the modal element, or scroll in content outside of the modal.
Elements that are not modal are called non-modal or modeless.
Top layer presence
By default, if multiple elements are positioned in the same location, they are painted by the browser in layers. This is done in DOM order: the element that is first in the DOM is painted first, each subsequent element on top of the previous and the last one in the DOM is painted last, at the top. With the `z-index’ property in CSS you can deviate from the default on a case by case basis, and decide your own layer order.
The top layer is a special layer that is, as the same suggests, always on top.
Popups are in the top layer when they are of the ‘manual’ type
Dialogs are not.
Backdrop
In some cases, it makes sense for elements to have a backdrop, usually this is done when they overlay the page.
With the ::backdrop pseudo element, you can optionally add a backdrop to your popup or modal dialog. This is done when they are modal, as in that case, none of the stuff behind the element can be interacted with. A backdrop gives a visual cue for that behavior.
A backdrop obscures content behind it and is used as a visual cue that this content is unavailable, in combination with a method to actually make it unavailable (inert).
I'll say overlay is another word for an element that has a backdrop.
Trapped focus
Sometimes focus should return to the “invoking element”. A popup will return
Sometimes focus is trapped:
- popup does not
‘Not for recreating dialog’ - Scott https://github.com/openui/open-ui/issues/415#issuecomment-1261565368
Keyboard closability
In general. things that can open would e
The main concepts
- Dialog
- Alertdialog
- Modal
- Popup
- Aria-haspopup
Dialog
The <dialog> element is something a ‘user interacts with to perform a task’ (see: dialog spec). It's often displayed when users need to choose. Do you want to continue, yes or no? If you want to open a new file, what shall we do with your current file, save or delete?
Dialogs are a lot like window.confirm() and friends, which the HTML specification lists under ‘simple dialogs’. They do offer more flexibility—you get to put whichever content and styling you want inside of them.
You can even put a form with `method="dialog"' in a dialog, which will close it when submitted.
Dialogs have a role of dialog, which the browser will assign automatically for you when you use the <dialog> element.
Dialogs can be modal (when shown with dialog.show() or non modal (when shown with dialog.showModal()).
Alert dialogs
WAI-ARIA defines a specific type of dialog, which is called “alert dialog”. It is meant for dialogs that contain brief, important message and They need to alert the user, which the browser should fire as a system alert event to accessibility APIs.
Examples
- After you didn't interact with your online banking environment for 10 minutes, and alert dialog shows and tells you you will log out in 5 minutes, unless you press “Continue my session”
Characteristics
Alert dialogs are always modal and have their focus trapped. They also require an accessible name. If there is a visible title, the title's id can be associated with the alert dialog's aria-labelledby attribute. If not, aria-label can be added to the alert dialog.
Popup
Popup is a set of behaviors that can be added to any element through the popup attribute (like tabindex or contenteditable). At the time of writing, it isn't in the HTML specification yet, but there is the Pop Up API Explainer and a PR to the HTML spec.
The popup attribute is meant for UI components that are:
- on top of other page content
- not always visible (eg just when they are relevant)
- usually displayed one at the time
An example of a popup is the listbox that shows when a select is opened (conceptually for <select> and literally for <selectmenu> as it is currently implemented in Chromium). Datepickers, teaching UI, tooltips and action menus are all examples of popup-like behaviors.
Example of a popup: Twitters alternative text feature (implementation has accessibility issues)
Popups have ‘light dismiss’ behaviour, meaning they close by themselves, except when they are of the “manual” type. Manual popups could be things like a “toast” notification that is dismissed via a timer or manual button.
Popups also can be opened, closed and toggled without JavaScript: with a <button> in HTML and popupshowtarget, popuphidetarget and popuptoggletarget attributes whose values correspond with the popup's ID, the browser can take care of showing, hiding and toggling.
An example:
<button
type="button"
popuptoggletarget="datepicker"
>Pick date</button>
<div popup id="datepicker"></div>
(the div is made a popup with the popup attribute, the button toggles the popup with popuptoggletarget)
Popups don't have a default role, . Sometimes they could be dialogs, so you would use <dialog popup>,
So, in summary: popups are a behaviour that gets added as an attribute to any element. It brings light dismiss, toggling with or without JS an
Note: Don’t confuse popup with aria-haspopup, which was deprecated in ARIA 1.2, can be a dialog, menu or other things. It requires developers to implement a focusable trigger and browsers to send an alert.
Disclosure widgets
Elements that show and hide things are often called ‘disclosure widget’, as Adrian Roselli describes in [Stop using ‘popup’]](https://adrianroselli.com/2020/05/disclosure-widgets.html). Adrian describes disclosure widgets in more detail in his aptly named post Disclosure widgets.
Disclosure widgets exist in HTML as <details>/<summary>, but can also be built with <div> and the appropriate ARIA attributes. This isn't entirely the same. In Details/summary, again, Scott O'Hara suggests that this is more consistent:
If your goal is to create an absolutely consistent disclosure widget behavior across browsers, i.e., ensuring that all `
s are exposed as expand/collapse buttons, then you’d be better off creating your own using JavaScript and the necessary ARIA attributes.
But, he adds, your ARIA disclosure widget won't have some of the features <details>/<summary> brings, like in-page search (Chromium triggers a <details>'s element open state when an in-page search query is found in its content).
- A dialog is modal when opened with
dialog.showModal()and not modal when opened withdialog.show(); with popups, non modal dialogs are probably going to be obsolete (@@@) - Full screen elements are modal when
Gotchas
Dialog node vs document mode
If you use <dialog> or role="dialog", assistive technologies will switch to application mode when the dialog is opened. This can make it so that some users can't access browse structured content in the way they are used to (eg browse byy heading or lists). For this reason, it is recommended to wrap any structured content inside of an element with role="document", like so:
<dialog>
<div role="document"></div>
</dialog>
Source: https://github.com/twbs/bootstrap/issues/15875#issuecomment-75668416
Hidde's open questions
- is a tooltip a popup? [yes ?]
- is a cookie banner a dialog?
- chat popup
https://developer.apple.com/design/human-interface-guidelines/guidelines/overview
Summing up
Originally posted as A dialog, a modal and a popup walk into a bar. How are they different? on Hidde's blog.
2.4.11 Focus Appearance adds more complexity to WCAG than we should want
Like many people, I have been monitoring the creation of WCAG 2.2, the upcoming new version of the Web Content Accessibility Guidelines. Nine new Sucess Criteria are proposed. One particularly worries me: 2.4.11: Focus Appearance.
Focus Appearance builds on two existing WCAG criteria that affect focus indicators: that users can see which element has focus (2.4.7), and that focus styles have sufficient contrast (1.4.11). Focus indication is essential for a wide range of users, including users who browse by keyboard or zoom in. For an introduction to why focus indication matters, see my post on indicating focus.
What's new about 2.4.11 is adds more requirements for what the indicator looks like:
- an element with focus needs to have sufficient contrast with its non-focused state
- an element with focus needs to have sufficient contrast with its surroundings
- the focus indicator needs to either be a solid line (so not dotted or dashed), or have a certain level or thickness (in which it can be dotted or dashed)
It's a clever new criterion, that addresses important user needs that were previously unaddressed. The Working Group clearly put a lot of research and thought into it. This is hard to do, as co-chair Alastair Campbell mentions in a GitHub issue:
what makes a visible focus indicator is not particularly straightforward
This is the crux of why this isn't trivial to solve and I appreciate everyone's efforts on the proposed Success Criterion. I know the text has had revisions and improvements after people have flagged complexity issues. Still, I'm sorry the Success Criterion as it stands now has me worried.
“Focus Appearance” is “at risk” of being removed from the final version of WCAG 2.2. My vote would be to drastically change it (again) or remove it entirely. Firstly, the requirements are complex to apply or teach. Secondly, browsers, OSes or assistive technologies could guarantee focus appearance better (and I feel it would be easier to talk to them than to convince all of the world's web developers).
Why I hesitate about including 2.4.11
Complex to apply
I expect Focus Appearance would be hard to apply, because the Success Criterion text has a lot of complexity. It is full of clauses and sub clauses. It often includes “and” (8 times), “or” (7 times) and “non”/“not” (4 times). There are two ways to meet it (you can choose one or both), and there are two exceptions and three notes. All in all, it's a lot to grasp.
The wording requires knowledge of a lot of specialised terminology, especially in the “area of the focus indicator” part. It may be that I am a non-native English speaker, but I had to look up what a “perimeter” is. The Oxford Dictionary of English states:
the continuous line forming the boundary of a closed geometrical figure
WCAG 2.2 makes this definition more specific to the web by defining “perimeter” as ”continuous line forming the boundary of a shape not including shared pixels, or the minimum bounding box, whichever is shortest”.
In this, “minimum bounding box” has its own definition:
the smallest enclosing rectangle aligned to the horizontal axis within which all the points of a shape lie
And because it is about web content, another clause is added:
For components which wrap onto multiple lines as part of a sentence or block of text (such as hypertext links), the bounding box is based on how the component would appear on a single line.
This is a lot to take in and it seems easy to misunderstand. There are so many sub definitions needed. One could easily misinterpret the concepts of a bounding box, the perimeter,“shared pixels”, “CSS pixels” (ok, that's already used in Reflow and Target Size) and apply the whole SC wrongly.
This makes 2.4.11 Focus Appearance very different from other criteria, like Non-Text Content or Keyboard. Accessibility specialists will know there are indeed lots of ways not to meet those requirements, but the general idea of how to comply is easier to grasp. Very few people will need to look up what a keyboard or text is.
Admittedly, there are easy ways to comply with the proposed Focus Appearance, too. One is to have a solid outline with a minimal offset of 1px that has sufficient contrast (3 : 1) with its background, as James Edwards explains in New Success Criteria in WCAG 2.2.
Complex to teach
As someone who sometimes teaches WCAG to teams, I also worry about the complexity of 2.4.11. I could teach the ‘easy way’ described above, that doesn't seem too complex to teach. But if I would try to teach the whole Success Criterion with all the requirements, exceptions and notes and also cover what the Understanding document explains, I fear I won't get it across.
“But teaching is your job, Hidde!”, you might say. Yes. And I could probably make it work, but it would take class time that I would like to spend on other barriers, and there is still the risk the information sticks with participants less because of the complexity. There will also be people trying to apply this Success Criterion on their own.
Leave it to browsers
We can't just leave all of our problems to browsers to fix. But if I had any say in it, browsers should fix any accessibility problems they are able to fix. That way, end users have to rely less on individual web developers to make good choices. I feel focus indication is a great example of that: the browser knows what has focus, users want to know it, web developers could fail to add a good indicator. So why rely on web developers?
In a discussion on relying on browsers for focus indication, the Working Group concluded that browsers don't do sufficient default focus indication today, so if we want accessible websites, we need to require it through WCAG. If browsers start to do it later, the requirement could be removed or moved to a different level then. A chicken and egg situation, basically, but with one of them more likely to materialise (I'm not super sure which, to be honest).
A second argument is that web designers are in a better position to design an appropriate indicator, one that fits well with the rest of the site's design. But it's unlikely those designers can take into account user needs as well as a browser could with settings. Some users may prefer an indicator they can see move from one element to another, some may want a very high contrast indicator, some may want it more subtle (see also Rain's comment mentioning high visible focus indicator from a COGA perspective). A browser could provide options. We wouldn't want individual websites to start offering focus indication choosers, right?
Forced focus indication already exists in various forms through OS settings, assistive technologies (like VoiceOver) and even some (buried away) browser settings (in Chrome). There is a bunch of browser plugins and bookmarklets that force focus indication, too. So we've got forced visibility. Forced “good appearance”, however, is not fully in browsers and harder to implement, of course. It would need to account for all the things 2.4.11 requires, like sufficient contrast with surroundings (the browser/add-on/plugin would need to make it work with any background) and sufficient contrast with non-focused state.
I get the idea of putting this on developers before full browser support exists, but it does feel a bit like solving all problems with one (conformance-shaped) hammer. It also doesn't apply when developers simply don't meet WCAG. Yes, there are human rights, ethics and laws, but we know they are violated a lot today. I fear this will only be more common when the requirements are too complex.
How to make it less complex
I know WCAG 2.2 is close to its last standardisation stages, so I'm sorry to bring this up now. I also don't want to just say ‘don't include 2.4.11’. Let me describe a possible way to make the situation less complex for developers, evaluators and teachers, by replacing Focus Appearance with multiple Success Criteria:
- Focus Distance to require a minimum offset between the focused element and its outline
- Focus Solid to require solid, unless a minimum thickness is used
These two on their own seem a lot less complex to apply, test and teach. As minimum contrast and visibility are already covered in other Success Criteria, these two criteria between them would make focus indication much better for low vision users, while not adding the complexity 2.4.11 adds.
Conclusion
The proposed Focus Appearance criterion does a great job at capturing which problems end users have around focus into requirements. But it lacks understandability for users of the standard: people who make websites, people who evaluate accessibility conformance, developers of testing tools, et cetera.
It may seem reasonable to say those understandability concerns are secondary to the ability of end users to use the web. Of course they are. But if there is too much complexity in WCAG wording and mathematics, I worry the web won't actually get better for end users. We'll lose the people who need follow the recommendations. This is already an issue with current requirements, as shown by the many “WCAG in plain words” derivatives and checklists that exist. The original source gets plenty of “appropriate requirements love”, it could use content design love.
I'm sorry, but I feel WCAG 2.2 is better off without 2.4.11. Even after some iterations, it (still) adds more complexity than we should want WCAG to have. It's difficult to apply and teach. It may end up like Terms and Conditions: factually correct, but commonly skipped over. That would be problematic in this case, and mean not considering important end user needs.
My ideal resolution would be (I know, easier said than done): sit down with browser makers and improve the focus indication game structurally together. Meanwhile, people who make websites can prioritise the 86 other WCAG Sucess Criteria (rather than implementing 2.4.11 until browsers are ready). Focus indicators are a core need web users have, it needs better appearance and likely choice in appearance, let's bring the research from AGWG into (browser) practice.
Originally posted as 2.4.11 Focus Appearance adds more complexity to WCAG than we should want on Hidde's blog.
Better accessible names
OK, you've added an accessible name to your control. Maybe you've used aria-label, <label> or some other way to name a control. Now you wonder: what makes a name good, effective or useful?
I wrote about why accessible names matter and where to add them before. In this post, I will go into how to make the actual names more user friendly. These tips are all from an underappreciated piece of content that I love: the Composing Effective and User-Friendly Accessible Names section of the ARIA Authoring Practices Guide. All credits go to the authors, I'm just adding context and examples.
Function over form
An accessible name is used by assistive technologies to refer to things on a web page. For instance, if you use voice control, you could say the accessible name of a particular control to activate it. If you use a screenreader, it is the name that gets read out when you get to the control, or when you pull up a list of controls (eg a list of links on the page).
Because of how we use accessible names, we want to keep them functional and avoid naming controls after what they look like. Ideally, you do this in the imperative form, that makes it easiest to quickly grasp what a thing is going to do.

Examples:
- “Open navigation” works better than “Hamburger” and “More options” better than “Kebab”
- “Next slide” works better than “Arrow right” or “Right pointing triangle”
- “Save document” works better than “Floppy disk”
Most unique part first
In a series of names, like a set of buttons, links, etc, start with the most unique part of the name. This makes it easier to distinguish them.
Let's say you list a bunch of albums and want to include “album” in each name. Most unique first means you say “Midnight Marauders - Album”, “To Pimp A Butterfly - Album” etc, rather than “Album - Midnight Marauders”, “Album - To Pimp A Butterfly”.
Or you have actions for a link: “Edit link”, “Copy link” and “Share link” work better than “Link edit”, “Link copy” and “Link share”.
This even applies to the <title> of web pages: if you're repeating your company name in it, leave it for last and list what's unique about the page first. Technically not an accessible name, but the same naming advice happens to apply.
Be concise
Keep a name to the most important 1-3 words, prefer brevity.
No roles as part of the name
Things that have names in your page will (or should) have roles too. The browser will derive the role for you, whether you've set it explicitly (e.g. role="button") or it comes for free with the element (e.g. <button>). If you add the role, for instance the word ‘button’, to the name, that is redundant and this can be annoying for users.
Examples:
- use “Close” instead of “Close button”
- use “Main” instead of “Main nav”
- use “Save” instead of “Save button”
Keep names unique
Imagine you work in a school and all your students are named “Alice”. It would be hard to address them… this is the same for the names of controls and components in your page, especially for users who use mostly these names to browse the page.
Examples:
- instead of an overview page that shows news items with “read more” links, use the title of each news item as the link name
- instead of saying “click here”, use the name of the page you're linking too, for instance: “See also: [name of the page]”
Sentences aren't names
The last tip in the document is: start names with a capital letter, for better pronounciation in some screenreaders, and don't end with a period, because a name is not a sentence.
I'm not sure if this is the type that this tip is originally referring to, but one example of setences in accessible names is this: a card that has a title, a description and a picture, that is clickable as a whole, implemented by wrapping it all in one <a> element. I've seen this in the wild. It is often problematic, because it creates names that are way too long and confusing. My recommendation would be to do this instead: pick a string that is a more useful (and concise) name and make that the <a>. Then solve the clickability issue with CSS.
Wrapping up
Before I wrap up, I want to assure you that you don't need to use ARIA to provide names, even if this information is part of the ARIA Authoring Practices. Text content in the appropriate HTML elements (<label>, <legend>, <caption>, <button>, <a>) works perfectly fine too. An added benefit is that when you provide visible names with these HTML elements, they can be used by more users, including people who don't use assistive technologies and people collaborating with assistive technology users.
That's all. As mentioned above, these tips are from Composing Effective and User-Friendly Accessible Names in the W3C's ARIA Authoring Practices. That specific page has a lot more tips and also covers accessible descriptions, name and description calculation, per-role guidance on whether you need a name, lots of gotchas and various coding techniques for adding names. Happy naming!
Originally posted as Better accessible names on Hidde's blog.
The last dConstruct
The last dConstruct is a wrap! Jeremy did a great job curating a day that was (loosely) themed around “design transformation”. Here's my writeup of the day.

How does content survive 100 years?
When designing Flickr, George Oates tried to design a “context for interaction, not just an application”. It worked. Flickr allowed people to post content and connect it through tags, comments and more. Today, the site has 50 billion pictures posted by millions of people, making it, in Jason Scott's words, “a world heritage site”. Archivists may have kilometres of underground storage where they keep historical records, a site like Flickr is unique, as so many people contributed to it. For future generations, the sheer amount of visual data could give away a lot about life today. But Flickr isn't a given. Changing owners a few times, the site was almost killed and all content deleted. Now, at Flickr Foundation, George thinks about keeping this content for the future. And by future, she means the next 100 years. Long term preservation most likely needs selection, George clarified, maybe by letting users mark specific photos of theirs as keepworthy. Maybe it needs printing after all, as we are not sure if JPGs or PDFs are still readable in a 100 years. And how do we preserve a picture that is part of a network, if we can only preserve part of that network? How does this wealth of content survive economic forces and corporate whimsey?
 George's team mapping out 100 years
George's team mapping out 100 years
These questions made me worry about the content I create online: blog posts, tweets, videos… it's on my personal website that I'm most sure there won't be corporate whimsey, but it's also unlikely to survive when I'm not around to pay the hosting bills. Should I update my testament?
The fun part of writing is the research
Lauren Beukes is a best-selling author. She travels a lot and said she actually enjoys the all this research more than the actual writing. On these trips, Lauren talks to a lot of people, from detectives in Detroit to teenage theatre geeks. She learns from their perspectives, takes in their sometimes horrifying stories and learns how they are treated by the system. Part of what a novelist does, she explained, is asking “what if?”.
Transformation through type
Type designer and calligrapher Seb Lester showed how a typeface he started designing on a train, came out 8 months later and started getting used. It was on washing powder, sky scrapers and olympic games branding. “When a typeface goes out in the world”, Seb explained, “a little bit of you goes out in the world”. The font was everywhere, but hardly anyone had heard of him (he said). Until he started publishing letter forms and calligraphy on social media. Seb's calligraphy videos and a cheeky comment in an interview in Salon got him jobs designing visuals for rocket scientists and Apple. His videos of lettering in progress are extremely soothing to watch, transforming from what seems like a few scribbles into beautiful works of art. Seb's stories were a reminder that success is very much a combination of two things: you want to “work hard”, “find your passion” and “believe in yourself” on the one hand, and be lucky and get noticed by the right people at the right time on the other. That last part is out of your hands, so you can only really try to do the first.
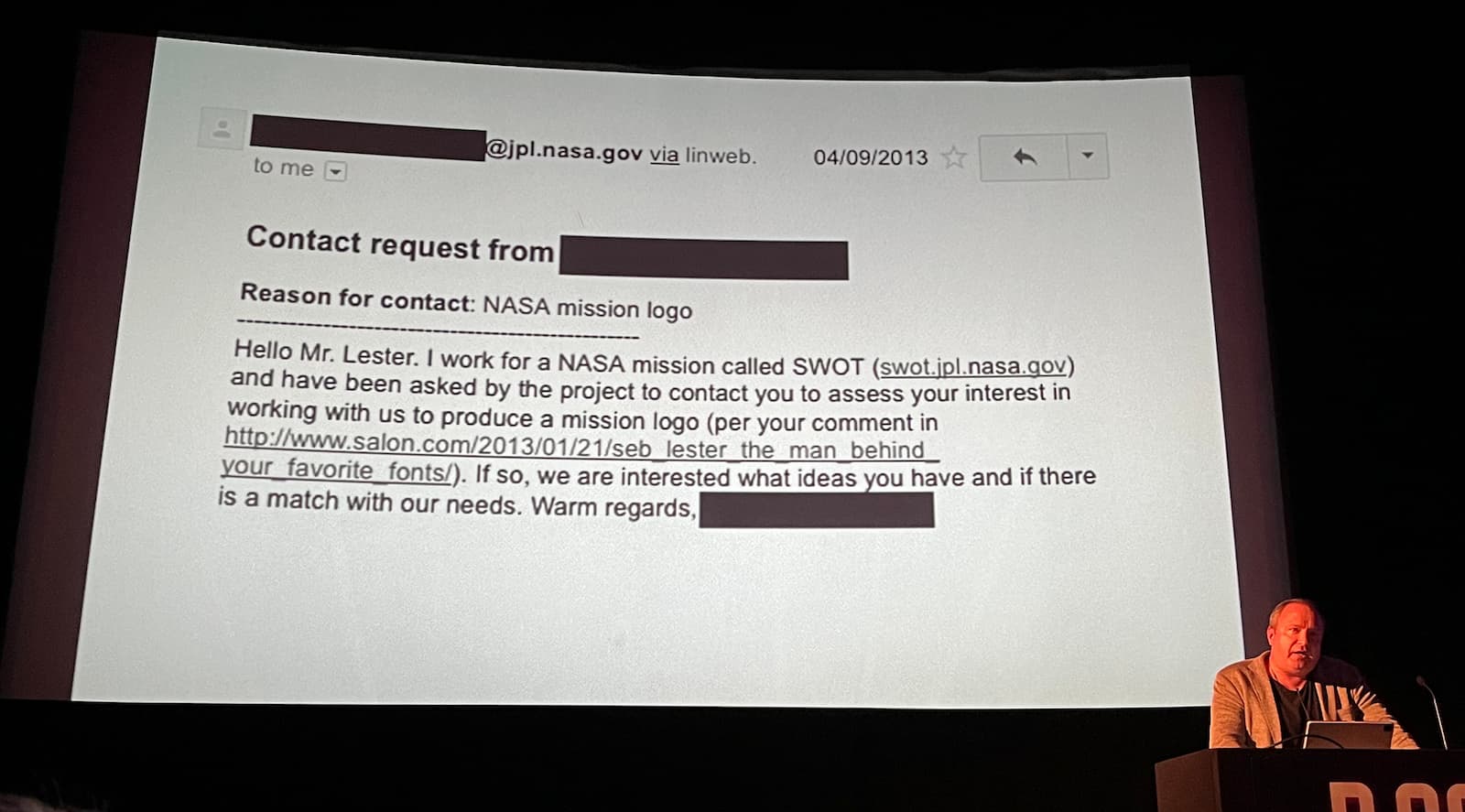 TFW NASA takes note
TFW NASA takes note
Design to make the world better
Daniel Burka has been a designer for a long time. He worked on the Firefox brand for Mozilla, which was interesting because of open source and their mission. He worked on Digg, which was interesting because of their scale. He worked on a game called Glitch, which was interesting because the creators of Flickr were involved, and Glitch became Slack). And then he worked at Google Ventures, where he met a number of companies working on life sciences related products. Then he came to realise that while designers in Silicon Valley are often in a very comfortable position, a lot of the world isn't well designed. This resonated with me: some of our largest's design budgets are used to solve trivial problems, like yet another food delivery service. Education, healthcare, financial services… they are long-term and hard problems. Highly regulated, too, and not very used to having designers on their teams. Daniel ended up working on Resolve to Save Lives, where he makes software that makes it easier to register data about high blood pressure patients. This sort of data saves lives by making it easier to get patients to return regularly. But clinicians want to spend time on patients, not data entry. The technological layer needs to be very light, to be effective.
Beware of tech utopians
In technology we trust. So much, that the Paris climate agreement—essential to humanity's survival on earth—is based on the assumption that technological inventions will be available. Techno-utopianism is not new, Sarah Angliss explained. She told us about Muriel Howorth, who was an amateur nuclear scientist who reckoned that if radiation could be used for atomic bombs, it could be used for atomic gardening. Howorth wanted to use “atom-blasted” seeds to grow a giant vegetable. Sarah also discussed an experiment in which fluoride, which is toxic in high quantities, was added to a city's water supply, with high expectations around improving the citizen's dental health, and “saxton spanglish”, a phonetic and somewhat controversial method of teaching children English. It reminded me of pinyin, that is sometimes used to teach non-native speakers Mandarin Chinese and also controversial for oversimplification and making proper learning harder. They are all attempts to transform through design, that are a little too utopian. Maybe another modern day equivalent, besides climate tech optimism, is that once so popular social network that frantically tries to make the ‘metaverse’ work, or even that we try and sprinkle machine learning on everything, even where it doesn't necessarily make sense (see AI for content creation). Yes, it could work, but it could not.
Computers need to get better at togetherness
Matt Webb talked about reinventing the workplace. One major reinvention was when the personal computer made its debut (see also: the setup). Here's some utopianism that did end up well. Screens, documents, text processing, the mouse: the mission to put a computer on every desk (and Douglas Engelbart's “mother of all demos”) completely reshaped what offices looked like. Speaking of design transformation! Matt noted how, fascinatingly, much of the history of computing is about furniture design. I didn't know Herman Miller worked with Doug Engelbart's team to invent furniture to go along with their machines. Is the office done? Not really, as in 2022 we increasingly find ourselves working together from different locations. The current state of “togetherness” is lacking, Matt explained. We can be in virtual rooms together, but it isn't as good as it could be. For instance, they don't have a window out—you can't see who's approaching the space. There is little of the serendipity you might find in a physical office. With Sparkle, Matt works on a Zoom replacement, a tool that aims to facilitate togetherness better. As a remote worker, and as someone who isn't sure Big Tech has the solution for us, I will be following this work.

Moonlander with applause-controlled lasers
Lasers: they are fascinating. Seb Lee-Delisle showed us how he took animations outside of the projected screen to kick off Smashing Conference in Oxford, displayed love for the NHS onto their Brighton building during the pandemic and displayed laser fireworks that people could interact with. It's impressive, really, how much even one laser can do, let alone the over 30 in different strengths that he currently owns. Seb had the arcade game Moonlander (I had to look it up) projected on the wall with lasers, so that we could all try and safely land a moon lander by affecting the vehicle's thrust with our applause.
Everyone perceives differently
Anil Seth concluded the day with a talk about perception. Questions about how we perceive the world outside and our own bodies have puzzled philosohopers for millennia. Today, neuroscientists try to confirm through experiments that we don't perceive the world directly, showing some of these philosophers were correct. Sensory input, Anil explained, is constantly processed by our brain—it fills in the gaps based on what it remembers of the past and predicts of the future. Seb's lasers had just demonstrated that: when he made his laser move in a circle, we perceived a static circle, not that movement. Just like a film is really 60 different images per second… our brain causes us to perceive it as a film. Anil drew an interesting parallel between perception (“controlled hallucination”) and halluccination (“uncontrolled perception”). This constant interpretation of input by individual brains implies what Anil calls “perceptual diversity”, everyone perceives differently. In an art installation called Dream Machine, participants' perception is triggered and then recorded in the form of drawings afterwards.
Wrapping up
There was a bit of design transformation in each of these talks. We were rightly warned about tech utopianism. Design and technology can't transform everything, yet some speakers shared their plans to transform. They (re)defined what it means to perceive ourselves, collaborate on screens or keep content available over a long stretch of time. Some speakers were right in the process of transforming. They talked about turning a series of penstrokes into art, lasers into fireworks, human experiences into novels and patient data collection into a minimal effort task.
A lot of our work in web design and technology has a power to transform and that is wonderful, especially when we manage to be intentional about the how and why. With that, I'll conclude this write up of the last dConstruct. If it piqued your curiosity, word goes that audio of the full event was recorded. It will be added to the dConstruct Archive in due time. For now, thanks Clearleft for another excellent event.
Originally posted as The last dConstruct on Hidde's blog.