Reading List
The most recent articles from a list of feeds I subscribe to.
On the importance of testing with content blockers
I recommend everyone to browse with content blockers turned on. The goal: protection against tracking. Safari and Firefox have good tracking protection features. With more people using these features, we should test our sites with content blockers turned on.
Content blocking
In the age of surveillance capitalism, some browsers have started getting more aggressive in how they block ad trackers to protect the privacy of their users.
Firefox has had Tracking Protection since version 42. It works with a blacklist of domains. When something is blocked, it will show up in the Dev Tools Console (“The resource at X was blocked, because tracking protection is enabled”).
Safari not only can block trackers for you, it also allows third parties to define blocking behaviour. Third party blockers can match patterns in URLs and detect things like the domain a script is loaded on (same as site vs not same as site, the latter means third party). When a tracker is identified, developers can choose what to do: block it altogether, just block cookies or hide elements from the page. Users can install one or multiple content trackers. There is a “load without content blockers” feature (long press reload on iOS), but note users may be unaware of it. I know I was until very recently.
What can break
Four examples I encountered in the last few months:
- I wanted to purchase clothing on Zara’s website, to pick up in a store. On the part of the form where I had to select which store, nothing showed. I could also not go to the next step.
TypeError: X is nullwas thrown in the browser Console. A Facebook tracking script was blocked by my content blocker, presumably the reason for the script to fail. - I wanted to find opening times at my local supermarket. Search did not yield results until I turned off content blockers.
- I wanted to open a hamburger menu. It did not open. (This one is very common, actually)
- A link did not work at all.
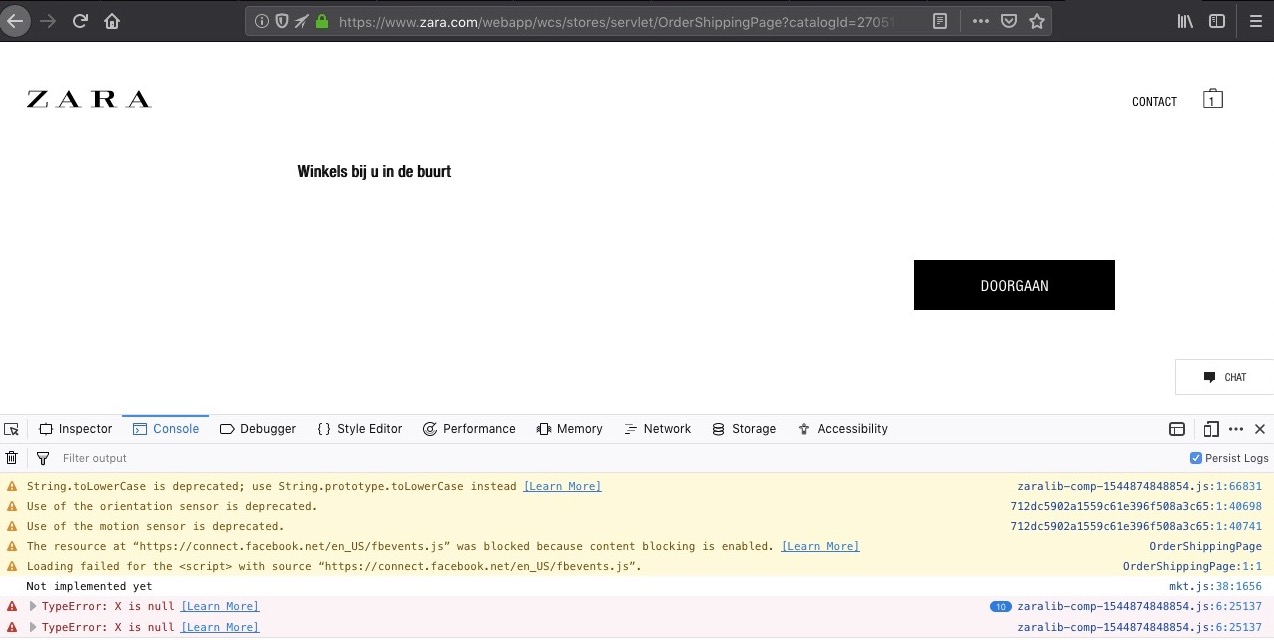 On this page, I could not select a store or press continue, because Facebook’s tracking script did not load
On this page, I could not select a store or press continue, because Facebook’s tracking script did not load
To understand the last example better, see Stephanie Hobson’s Google Analytics, Privacy, and Event Tracking, which shows how Google Analytics recommended tracking code breaks links for people who block the tracker.
We should not need to track to take people’s money. Or to let them find opening times, open a hamburger menu or follow a link. Metrics can be useful, but they are rarely questioned.
A working website: some strategies
I understand companies want behavioral data in order to improve their sites. But if it puts a stop to taking people’s actual money, doesn’t that defeat the purpose of why you have a website as a company? Is figuring out how many people open your hamburger menu more important than having the feature work at all?
Use no scripts
This one is easy in theory. It is hard in the reality of modern web development, because people will laugh at the suggestion. If your site does not rely on JavaScript to build features like to take people’s money, search for opening times, show a navigation on mobile or go to other pages, these features can potentially just work.
Progressive enhancement
If you manage to develop in a way that does not assume JavaScript (or CSS), you’re likely doing progressive enhancement of some sort. It means that when you build new features, you start with the very basic building blocks, like headings and lists. Simple HTML that describes the feature in a way the most basic browsers understand. You then turn it into something fancy, using web technology a modern as you like. For example, use Web Components to make it tabs, as Andy Bell described. If the fancy thing breaks, the basic building block likely still works.
Not only should progressive enhancement help make your site more robust and resilient, if your whole team can think this way, it can help setting priorities sensibly. See also Resilient Web Design, Jeremy Keith’s free book on building resilient web sites and Dear developer, a talk by Charlie Owen.
Conclusion
To build good websites, I think we should prioritise working websites above gathering potentially useful data (if doing that at all). As developers, we should keep in mind trackers could get blocked and, consequently, never rely on their availability.
Originally posted as On the importance of testing with content blockers on Hidde's blog.
Return of the blog roll
Personal blogs are making a comeback among web folks. I like this. I have even gone so far as to add a blog roll to this site, so that you can see which blogs I like to read (fwiw).
Personal blogs FTW
When I started getting interested in the web, about 15 years ago, blogs were how I learned new stuff. It was not just learning either, it was reading what interesting people were up to. This is something I heavily used RSS for: the data format that allows easy subscribing to content (or ‘syndication’). In an RSS reader, for whoever is unfamiliar with it, I was able to follow all the feeds I subscribed to in one place.
In the last 5-10 years, Twitter took over a lot of that. I stopped using an RSS reader at some point. If I discovered blog posts, it was because the authors tweeted about them, via round-ups like The Daily Nerd (it was great and is dearly missed) or via newsletters like Rachel Andrew’s CSS Layout News, David A. Kennedy’s A11y Weekly and Zoran Jambor’s CSS Weekly.
Twitter has become a little less attractive recently. They made changes so that third-party apps like Tweetbot are mostly broken. The platform’s leadership fails to deal with the abuse that happens to its users. They keep experimenting with orders that are not historic order… all this made me realise I should go back to consuming blogs directly. I have been gone back to reading blogs through an RSS reader for a couple of months now (I use Feedbin).
There seems to be a revival of RSS, Jonathan Snook noted this week:
I like that RSS seems to be making a very small comeback. I find it easier to keep track of and means I don’t have to be on constant lookout on Twitter for updates.
Sara Soueidan said reading RSS gives less noise:
My RSS reader is like a private, quiet, comfy reading room, compared to Twitter which is more like a crowded, noisy coffee shop.
RSS is a great means to take back control over the web we love from platforms like Twitter. Ben Ubois, founder of Feedbin, a service to read RSS, explicitly says so in his latest blog post, Private by default:
I want Feedbin to be the opposite of Big Social. I think people should have the right not to be tracked on the Internet and Feedbin can help facilitate that.
This is music to my ears.
Earlier this year, NetNewsWire, the 16 year old RSS reader for Mac, was returned to Brent Simmons, its original inventor. He plans to release a new reader, open source, and make it the very best.
Šime Vidas of Web Platform News recently published his list of over 600 RSS feeds, worth a scroll through.
So yes, more people are getting interested in using RSS again. And in personal sites.
This site now has a blog roll
For those who aren’t using it: this site has two RSS feeds: full articles and summaries. You can read them in whichever reader you like, or open the posts in the browser from your RSS reader. Then you’ll see my fonts of choice.
And, as of this week, this site has a blog roll. Blog rolls are lists of (personal) blogs, usually displayed in a sidebar of a website. They have disappeared from a lot of blogs in the past years (I do like Jeremy Keith’s bedroll), but I completely agreed with Marcus Herrmann, when he suggested they should make a comeback. I love blog rolls to discover more people to follow, sometimes outside my own bubble.
On this blog, the blog roll has sites of people whose stuff I like to read. The people that inspire my writing here. The blogs I can recommend. For what it’s worth. I hope more people will follow Marcus’ example.
Originally posted as Return of the blog roll on Hidde's blog.
2018 in review
The year is about to end, so here is another year in review post!
Some might think it is odd to summarise one’s own year, but I think it is fun to share some facts and thoughts. I love reading these kinds of posts from others (hi Zell, Andy, Chee-Aun, Nienke, Heydon). So here we go. Like last year, I’ve divided stuff into highlights and things I learned. To be clear, that doesn’t mean I had a year consisting of 100% highlights and learnings. That would be weird. Of course there was also stuff that went wrong, wasn’t amazing or was personal. I just think they’re for elsewhere (in person over drinks).
Highlights
Projects
In 2018, I spent most of my time in Mozilla’s Open Innovation team, that I’ve been part of for over a year now (as a contractor). I feel very lucky to get to work with so many smart people. I’m specifically working on the IAM project. For those unfamiliar with the acronym: IAM is short for identity and access management, it is about how people prove who they are (for instance, with email or a third party) and get access to stuff with as little friction as possible. That is particularly challenging when people have multiple identities, which most do. As part of the IAM effort, it’s been super exciting to build most of the front-end for a project codenamed “DinoPark”, which is currently in closed beta. I’m excited to continue this work in 2019 and share more when we can.
In Q4, I also spent a day a week working at the City of The Hague, specifically helping with improving accessibility and profesionalising front-end development of their digital services. It’s been great to see improvements shipped both in the application’s code as well as the content management system product. Looking forward to what we’ll do next year.
Other short engagements included:
- teaming up with Jeroen and Peter, I helped NOS, the Dutch broadcaster, with an accessibility audit, user tests with visually impaired users and an in-house presentation on technical accessibility
- I ran a one day workshop on accessibility guidelines at Zilveren Kruis
- with Peter, I worked on JavaScript to power a chat-like interface for the Dutch government
Volunteering
I did not do a lot of volunteering this year, but I did translate the Inclusive Design Principles into Dutch and worked on improving MDN documentation on accessibility.
Cities
This year, I traveled to Munich, Bristol, Munich (twice), Taipei, San Francisco, Mountain View, Paris, Como, London (twice), Berlin (twice), and Düsseldorf. I’m not so proud of this carbon footprint, and experimented with European train travel, which took a bit more time, but was pretty ok for productivity.
 My terrible attempt at taking a panorama picture from the rooftop of the Mozilla offices in San Francisco
My terrible attempt at taking a panorama picture from the rooftop of the Mozilla offices in San Francisco
Conferences and events
This year, I attended these events:
- Beyond Tellerand Munich
- Fronteers Conference
- Mozilla Festival (UK)
- performance.now()
- Design Ethics Conference
 Proof that I attended events: new stickers!
Proof that I attended events: new stickers!
I spoke multiple times, too:
- about password managers at MozTW community meetup (Taiwan) and #HackOnMDN (UK)
- about graphic design and the web at Front-end United and CSS Day
- about accessibility essentials at Refresh Conference
- about philosophical ethics at Accessibility Club Conference (Germany)
I did my CSS Layout workshop three more times (for Fronteers and at Front-end United) and ran a new accessible components workshop (for Frozen Rockets).
Organisers, thanks so much for having me, a newbie speaker. The first time conference speaking was stressful, time-consuming and very scary, but also satisfying. I got great feedback, both praise (yay!) and things I can improve on (thanks, you know who you are).
I’d love to speak more in 2019, please do get in touch if you want to have me present at your event or give a workshop.
Writing
I published 26 posts on this blog, not including this one. Like I said in last year’s review: I very much recommend writing to fellow people who work on the web, it can be helpful in many ways. It is also great to be able to do this on a domain you own, on pages you designed and built. If anyone needs mentoring around this, get in touch, I would love to help!
Some of the most read posts:
- More accessible markup with display:contents on a bug in
display: contentsimplementation in major browswers that undoes accessibility benefits the property could have brought otherwise (since fixed in Firefox stable and being fixed in Chromium) - What kind of ethics do front-end developers need? - in which I tried to make the idea of ‘more ethics’ practical for front-end developers
- Let’s serve everyone good looking content on, wow, really, in 2018, that websites don’t need to look the same in 2018. I find this is still a thing at my clients and those of devs I talked to.
- How to make password managers play ball with your login form sharing what I learned about password manager compatibility
Reading
It felt a bit weird to have the Goodreads app keep me in check reading-wise, but it did the job. I managed to read more than the goal I set: 46 books. Some that readers of this blog might find interesting:

- Brotopia, about the ‘bros’ that founded some of the biggest Sillicon Valley corporations and the culture they created. I must admit some doubts towards the word ‘bro’ , but wow, the book taught me a lot about how I don’t want to be and where I don’t want to work.
- Klont – if you read Dutch, get it! This novel brilliantly captures the phenomenon ‘datafication’ and how it endangers some of the basic concepts of free societies, as well as, unrelated, the phenomenon of ‘experts’ traveling the world to give talks
- Common sense, the Turing test and the quest for real AI – sometimes fairly technical and academic, but I loved the hype-free thinking about artifical intelligence and what to expect from it
- Killing Commendatore – if you’re into Murakami or want to start reading his work, this is great. It is a lot of pages, in two parts, but worthwile. I read the Dutch translation, it is available in many other languages, too.
For all the ‘big data’ and AI expertise that Amazon, which owns Goodreads, has, the app is still very bad at recommending new books. For me, it doesn’t go beyond what the most generic airport bookshops stock. The real human beings I follow on the platform brought much more reading inspiration.
Things I learned
Some random things I learned:
- I finally got my hands dirty in declarative client-side component frameworks. My framework of choice was Vue.JS. I learned concepts like routers, props down / events up, reactivity and lifecycle hooks, found they mostly just made sense and enjoyed working in this paradigm. I also found that within these concepts, I mostly wrote just JavaScript, good markup and sensible CSS. For instance, X is now ran inside a lifecycle hook, but X itself is just a method in JavaScript. Y is exposed as a component template, but Y itself is just plain old good
table. - I learned in multiple projects this year how hard it can be to explain the concept of focus. It exists as a thing in the browser (the
document.activeElement), but also as a thing in people’s thinking, not necessarily the same way. And then I’m not even talking about indicating focus yet. In my talk in Groningen I spent a number of slides trying to get it crystal clear. I like Laura Carvajals “You wouldn’t steal their cursor” and tried a streetlights metaphor (they are not pretty, but if they’re not there, you can’t see where you’re going at night) - I worked with WCAG 2.1 in real projects (testing for the newly added success criteria and talking about them in slides)
- I added CSPs to some sites (see also How I learned to stop worrying and love CSPs)
- I did more background reading to better understand the world we’re developing front-ends for (super meta), inspired by various colleagues, conference speakers and friends
- It’s totally workable to use Firefox Nightly as a main development browser, I had expected the occasional crash, because it is an early release channel, but had none. It is not as unstable as it advertises as. Also: tabs and sessions get recovered after updating (I knew this, but had not taken the risk before).
What I want to get better at next year:
- writing and presenting
- I want to try and build something with Rust
- get more people excited about having a personal website with a blog
- take more time off
With that, I wish all readers a fantastic 2019! If anyone has written year in review posts, I’d love to hear about them in the comments/webmentions, and read what you have done.
Originally posted as 2018 in review on Hidde's blog.
Making single color SVG icons work in dark mode
In a project I work on, we had a couple of buttons that consisted of just icons (with visually hidden help text). The QA engineer I worked with, found some of those did not show up in dark mode, which rendered the buttons unusable for users of that mode. Using inline SVGs with currentColor fixed the issue.
What’s dark mode?
Dark mode (similar-ish to high contrast mode) is a setting on platforms, browsers or devices that inverts a user’s colour scheme: from dark elements on a light background to light elements on a dark background.
This setting improves the experience for all sorts of users. For instance, people who work in the evening, those spend a lot of time behind their screens and users with low vision. It also saves energy on some types of screens.
Dark mode is available on the latest macOS and Windows 10, but also in the form of a browser plugin (Dark Background and Light Text add-on for Firefox, Dark Night Mode Chrome extension). In this post I’ll refer to Dark Modes as one thing that generally works the same across different implementations. In reality, there can be inconsistencies, of course. They can be tricky to test remotely, as testing platforms like Browserstack don’t support dark modes for security reasons.
Some dark modes will flip colors on existing websites, turning your white colours black. In our project, we try to make our interface work with that kind of dark mode, as some of our users use these settings and it lets them have a much better experience. This is a relatively cheap accessibility win.
Inline SVGs to the rescue
Let’s assume our site has a light background with black icons. One way to include an SVG icon is to use an <img> tag pointing to the SVG. Here’s an example of a chevron icon:
<img src="chevron-right.svg" alt="" aria-hidden="true" role="presentation" />In Windows High Contrast, Dark Background and Light Text and Dark Night Mode, the icon simply did not show. I believe the reason is that Dark Modes generally parse style sheets only, they ignore the contents of markup (including SVG files). In those cases, they will not replace black with white.
If we could only set the color for these SVGs in our stylesheets! Well, currentColor allows for that, and, it turns out, that actually works with Dark Modes:
<svg
xmlns="http://www.w3.org/2000/svg"
width="24"
height="24"
viewBox="0 0 24 24"
fill="none"
stroke="currentColor"
stroke-width="2"
stroke-linecap="round"
stroke-linejoin="round"
>
<polyline points="9 18 15 12 9 6" />
</svg>For those new to currentColor: it resolves to whatever the CSS color is (as set or inherited) of the element the svg is used in. So if a tool updates all colors in the page, the SVGs automagically change colour too. It is also popular because it works great with states like hovers: for icons with text, icon colours will change whenever you change the text colour.
Declaring supported color schemes
After I posted this, Amelia Bellamy-Royds helpfully pointed me at a proposal for declaring color schemes preference. It is proposed to be a property you can set at root level (supported-color-schemes: light || dark) or as a meta tag, so that browsers can be in the know before they start parsing CSS. The property basically lets you tell a browser that your CSS supports dark modes and will not break in them. Safari has experimental support for the property in Technology Preview 71.
The supported-color-schemes property is meant to be used in conjunction with the prefers-color-scheme media query.
Conclusion
So, if you use currentColor for the only (or primary) colour in your SVG icons, they will work better in dark modes. I’ve not done much more research than this, but hope it helps others who try to make their icons work in dark mode. Feedback more than welcome!
Originally posted as Making single color SVG icons work in dark mode on Hidde's blog.
Scroll an element into the center of the viewport
Say your page displays a list of names and you want a certain person to be highlighted and scrolled into view. There’s a browser API for that: Element.scrollIntoView(), which scrolls an element into view.
Element.scrollIntoView() can take two types of elements: a boolean or an object. The object argument gives developers more control over how elements ‘in view’ are aligned, but has slightly less browser support. Let’s look at what we can do with both.
The boolean argument
Say, you have a couple of people in a list:
<ul>
<li id="alice">Alice Cruz</li>
<li id="daniel">Daniel Ho</li>
…
<li id="julie">Julie Howard</li>
…
</ul>If you want Julie to be scrolled into view, find the relevant element, then call scrollIntoView():
const julie = document.getElementById('julie');
julie.scrollIntoView();This scrolls the element into view. With a boolean argument, you can have some control over alignment. If you pass true (default), the browser will scroll so that the element is at the top of your viewport or other scrollable element. With false, it scrolls so the element is at the bottom of the viewport:
julie.scrollIntoView(true) // align top
julie.scrollIntoView(false) // align bottomNote that the underlying terminology is not ‘top’ or ‘bottom‘, I’ll get into that in the next section.
For most use cases, this boolean argument may be all you need. It lets you choose if you want the element to align top or bottom.
This isn’t always ideal, sometimes you may have a sticky header, so scrollling an element to the top of the document would not actually get it into view. If something like that is the case in your project, the object argument comes in handy. It gives more control over alignment and allows for smooth scroll.
The object argument
In the latest version, you can also pass Element.scrollIntoView() an object, which lets you set two things:
- should it scroll smoothly or jump instantly?
- how should the element align along the block and inline axes?
julie.scrollIntoView({
behavior: "smooth" | "auto";
block: "start" | "center" | "end" | "nearest";
inline: "start" | "center" | "end" | "nearest";
});Smooth scroll
With the behavior parameter, you can set whether scrolling should be instant, so the page just jumps to the element, or smoothly, over a number of seconds (to be decided by the browser).
Unsurprisingly, the "smooth" value triggers smooth scroll. The "auto" value triggers instant scroll, as long as the element’s computed value for the scroll-behavior in CSS is not "smooth".
Alignment
Where I’ve been saying ‘top’ and ‘bottom’, I should have said ‘start‘ or ‘end’. They are the logical properties that you might recognise from other recent CSS specs like Grid Layout and flexbox.
As a quick reminder, the inline direction is the direction in which your text runs: it is the direction in which the words of this article are added. The block direction is the opposite of that, it is where block level elements are stacked, or where paragraphs of this text are added.
In a page with a vertical scrollbar, on the block axis, start means top, end means bottom. That’s the case on this page, for instance. But if your page uses vertical writing mode, you’d scroll horizontally, like in Hui-Jing Chen’s example of Chinese typography; in those cases, start means right, end means left on the block axis.
Fallbacks can be tricky
All browsers that understand element.scrollIntoView() accept the boolean argument. But only some accept the object argument. The good thing is, browsers will fallback for you. The default for the boolean argument is true, which sets the equivalent to block: start. If you use the object argument to use block: center or block: end, browsers that don’t do the object argument, will regard the argument to be true (because objects are truthy). So you’ll end up with block: start in those browsers. That’s often great, except when it is the opposite of what you’re fallbacking for.
If your interface requires precisely control over scroll alignment, fallbacks can be tricky. As an alternative you can also roll your own alignment with element.scrollTo(), as Jan Hoogeveen pointed out (thanks Jan!). If you end up going for that, I would recommend using coordinates as an argument, as the object argument does not work in some recent browsers, including Edge. See also window.scrollTo on MDN.
In the works: scroll snap
If you find scrollIntoView interesting, you may be interested in Scroll Snap, too. This is new CSS, currently being worked on, which lets you define things like a padding for the scroll container. Rachel Andrew has written a guide on the basic concepts of Scroll Snap on MDN. Some of the properties are already available in some browsers.
Originally posted as Scroll an element into the center of the viewport on Hidde's blog.