Reading List
The most recent articles from a list of feeds I subscribe to.
More accessible defaults, please!
Useful HTML elements like date inputs and <video> could make the web a much better place, if browser accessibility bugs in their implementations were prioritised.
On ‘the web is accessible by default’
I like to claim ‘the web is accessible by default’, a sentence that requires nuance (see below). Yes, the web is accessible by default in many ways. The fact that websites are made of text, structured text in most cases, allows for an amount of accessibility that print never had. We can enlarge it, copy paste it, feed it to translation software, have it read out by screenreaders… this is awesome, and very helpful.
But the web has become more than text, in 2020 it is a lot more than that. Websites and web apps now have videos, complex forms and clickable areas that are usually more than a couple of words to form a link. I would love to tell my clients that they can just use HTML, the language that has accessibility built in. More often, the answer is ‘it depends’, when people ask for solutions.
The components of an accessible web
An accessible web has many components, which all somehow circle around web content. On an accessible web, everyone can create and view web content. That’s the basic premise (and the basic promise). To get there, we need not just accessible content. We also need tools that can create accessible content (like CMSes), web standards that allow for marking up accessible content (like HTML) and tools that can display content accessibly (like browsers). We need developers, authoring tools, web standards and browsers to all play along, if we want the web to be accessible.
The browser part of the accessibility picture can have a huge impact. Last month, I wrote about the potential for browsers to automatically fix accessibility problems, in other words mitigate issues caused by inaccessible content. But what about content that is accessible in principle. but breaks ‘because of browsers’?
What browsers could do
In HTML, the inaccessible parts, Dave Rupert listed a bunch of HTML elements that have known accessibility problems in browsers, like date inputs and <video> . Developers use these elements because they trust the web to be accessible by default, their strategy is to stick close to the standards. That promise is somewhat broken for these specific elements.
In Dave’s article, there is a link with more details for each problem (recommended reading!). It somewhat shocked me to see all these issues in one list, even though I had heard about the majority. Basically, if any of those HTML elements are used, a browser displays the content inaccessibly, despite that the standard defined a thing that could be accessible, and developers implemented a thing that could be accessible.
It’s important for me to note at this point: browsers are complex beasts. Browser engineers are extraordinary people who work very hard to build all sorts of features that generally benefit the web. And, of course, we don’t just need an accessible web. We also need a secure web, a web with user privacy, a web with amazing graphic design capabilities (I love CSS Grid), a web that doesn’t lose market share to app ecosystems, a web that efficiently runs complex JavaScript applications, a web that’s fast, a web that can be a compilation target for Rust and C/C++, et cetera.
I should also clarify that while browsers might be breaking things in these examples, there are also plenty of examples where standards are inconsistent despite heroic efforts, or developers build things that cause nightmares for web compatibility engineers (keeping browsers compatible with the web is hard, explained Mike Taylor at View Source 2016).
So, with the caveats that browsers have many priorities, and that standards and developers can also cause trouble, let’s return to the issue of this post: inaccessible HTML elements in browsers. How can we mitigate these problems? Some of the issues can be addressed by web developers themselves with trivial code. If they have heard of the bug, not all developers will. For other issues, there are third party libraries, like AblePlayer for more accessible video. Again, it’s safe to say only a subset of developers is aware of the issues like those with <video> .
Browser makers are in a unique position to fix all of these particular issues for all, so that people with disabilities need to rely less on the willingness of individual developers to enjoy content. There are bugs filed against the relevant browsers, some of which have been open for over a decade, like the bug for keyboard accessibility for <video> in Firefox.
It would be so good if accessible rendering of HTML elements was prioritised more.
Some developments are happening:
- There is some exciting work being done in Edge/Chromium to make the default rendering of form controls better
- For elements beyond what exists in HTML today, my hopes are on OpenUI, a project of the W3C’s Web Incubator Community Group. They aim to standardise form controls and components in which, among other things, “accessibility, focus and other foundational items work as expected”.
- Firefox has recently improved the accessibility of number input types
Wrapping up
Yes, there are lots of priorities beyond the rendering of HTML elements in browsers. Yet, I’d like to make the case for browsers to prioritise accessible implementations of HTML elements. If browsers implement these elements with maximum default accessibility, they can make improve a lot of the web platform at once.
As Eric Eggert said on Twitter:
We need a movement to fix the web platform to make those essential building blocks of the web accessible for all.
I’d like to join this movement, please! But really, I hope for browsers to support this movement.
Originally posted as More accessible defaults, please! on Hidde's blog.
Could browsers fix more accessibility problems automatically?
Last year, I was lucky to be selected to present at the Web We Want session at View Source in Amsterdam, to argue for something that’s bugged me (and others) for a while: browsers could be more proactive in fixing accessibility issues for end users.
This post is part write-up of that 5 minute talk, part new additions.
Outreach only does so much
The accessibility community produces lots of information about making accessible websites. Especially for folks who want to get the basics right, detailed info is out there. Sources like WAI, The Accessibility Project and MDN Accessibility have information on what to do as designers, developers and content creators.
This is great, but realistically, this guidance is only ever going to reach a subset of website owners. There are always going to be websites that do not include accessibility best practices, for all sorts of reasons. Whether it’s ill will or obliviousness, it impacts people’s ability to use the web effectively.
It would be pretty useful if browsers could give users the power to override the web, so that they can browse it better. They would then be less at the mercy of willing or knowing developers.
Note: I do not want to say browser features can remove the need for us to worry about improving accessibility. Usually, websites can make the best choices about accessibly offering their content. When it comes to responsibility for accessibility, it is the website’s, not the browser’s.
Can browsers fix issues when they find them?
Most web folks will be aware of WCAG 2.1, the internationally embraced web standard that defines what it means for a website to be “accessible”. The sources I mentioned earlier often refer to this document (or earlier versions of it). When we speak of an “accessibility problem”, there’s often a specific success criterion in WCAG that specifies it.
WCAG conformance is largely tested manually, but luckily we can detect some accessibility problems automatically. An interesting project to mention in that regard, is ACT Rules, a Community Group at the W3C. They are mostly people from accessibility testing software vendors, like aXe and SiteImprove, who work on rewriting WCAG as testing rules (paraphrase mine). While doing that, they help harmonise interpretation of the WCAG success criteria, in other words: find agreement about when some web page conforms and when it does not. Guideline interpretation is not trivial, see The Web Accessibility Interpretation Problem by Glenda Sims and Wilco Fiers of Deque.
Interpretation may not be trivial, there are issues that are pretty clear. There are some that we can get true positives for (note, this is a small subset of WCAG; useful, but small). So, if we can automatically find these issues, can we also automatically fix them?
What browsers could do today
There are some issues that browsers could fix automatically today. In my ideal world, when a website has one of those barriers, the user notices nothing, because the browser fixed it proactively. This is not a Get out of jail free card for developers, designers or content people, but more so one for end users, to improve their experience when they encounter inaccesibility.
For lack of a better metaphor, I imagine each of these features to exist as a checkbox within the browser. I’ll gladly admit this is somewhat oversimplified and high level, it is really just to make the point. Browser makers will likely solve these problems most effectively.
During my research, I found that some browsers already fix some of these issues. Yay, go browsers!
Force zoomability
Some users may depend on zoom functionality to read content. With the Apple-invented viewport meta-tag, web developers can disable zooming:
<meta name="viewport" content="user-scalable=no">This may be useful in some edge cases, like in photo cropping or maps functionality. But often, it prevents what was a useful feature to some users.
Browsers could fix this automatically, for example via some sort of preference that bypasses the developer’s preferences in favour of the user’s.
This fix exists currently, as Apple does ignore the user-scalable directive in the latest versions of iOS (>10), and it seems some Android browsers do, too.
Force readability
Claiming that 95% of the web is text, Oliver Reichenstein once said:
It is only logical to say that a web designer should get good training in the main discipline of shaping written information
(from: Web Design is 95% Typography)
Plenty of websites out there aren’t great at “shaping written information” at all. There may be differences in taste and all, but some design decisions objectively make content illegible to at least a portion of users. Common problems include: light grey text on a white background, typefaces with extremely thin letters as body text and way too many words per line.
Browsers could fix such readability problems automatically, by forcing page content into a lay-out optimised for reading. Examples of browser features that do this:
- Safari has had a Reader View for a long time, it lets you select fonts and colours and is marketed as allowing for distraction-free reading
- Firefox Reader View, which will let you make some choices in typography, dark modes and can even speak the page content out loud so that users can listen instead of read
- Microsoft Edge has Immersive Reader View (previously Reader View), which can, like Firefox, read aloud. It even has grammar tools, that will let you do things like highlight nouns.
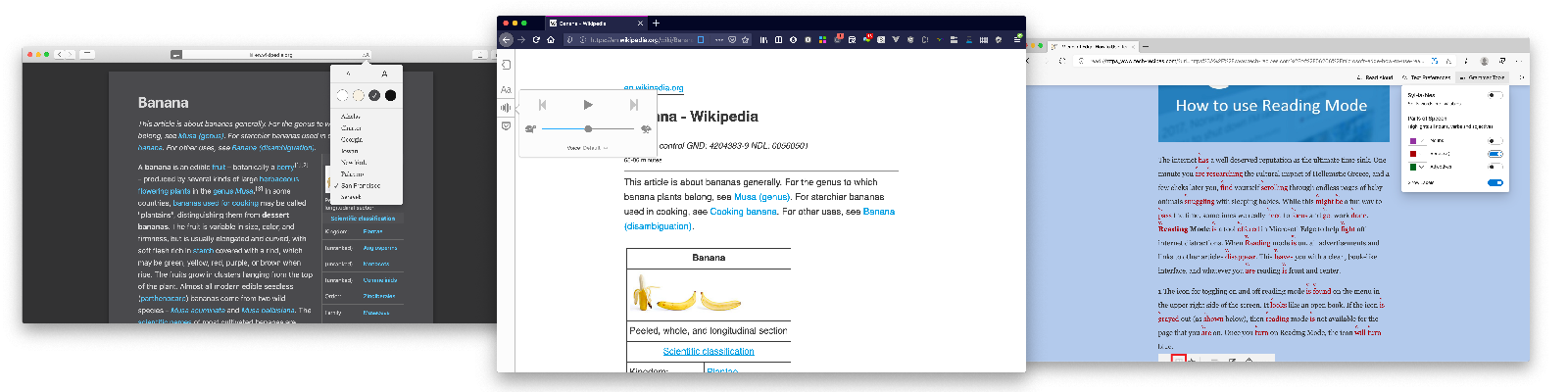 Examples of reader mode: Safari, Firefox, Edge
Examples of reader mode: Safari, Firefox, Edge
Enforce contrast
When there is too little colour contrast in our UIs, they are harder to use for people with low vision and as well as people with color deficiencies. With contrast checkers (like Contrast Ratio), designers can ensure their work meets WCAG criteria like Contrast Minimum and Non-text Contrast. Still, whenever new content gets added, there’s a risk new contrast problems emerge. That text on a photo on the homepage could turn from super readable to hardly readable in a whim.
You might be getting the theme by now… browsers can deal with contrast problems automatically. Why not have a “enforce contrast” setting, that adds a black background to any white text, always?
It turns out, some browsers are already working on this, too! I was unaware when I prepared my talk. The basic idea is to fix contrast for users that use Windows High Contrast Mode (HCM). So, rather than the individual setting I suggested, it ties in with a related and existing preference. Much better!
The details:
- Microsoft Edge’s solution is a readability backplate that could be behind all text when High Contrast Mode is on. Melanie Richards also mentioned this in her talk Effectively Honoring Visual Preferences at View Source 2019 (also goes into some great other colour-related accessibility features Microsoft are working on)
- Firefox is also adding a backplate, see bug 153912, which works in HCM and uses theme background color. Firefox used to completely disable background images in HCM, which ensured lots of contrast, but also in losing potentially important context.
Fix focus styles
For many different kinds of users, it is important to see which element they are interacting with. As I wrote in Indicating focus to improve accessibility, focus indicators are an essential part of that.
Some websites remove them, which makes navigation with keyboards and some other input methods nearly impossible. It is a bit like removing the mouse indicator. CSS allows for doing either, but that doesn’t mean we should.
Browsers could fix this automatically! I would welcome a setting that forces a super clear focus indicator. Basically, it would activate a stylesheet like :focus { outline: 10px solid black; } (and probably a white outline for dark backgrounds), and boom, people who need focus indication no are no longer dependent on individual website’s willingness to provide it.
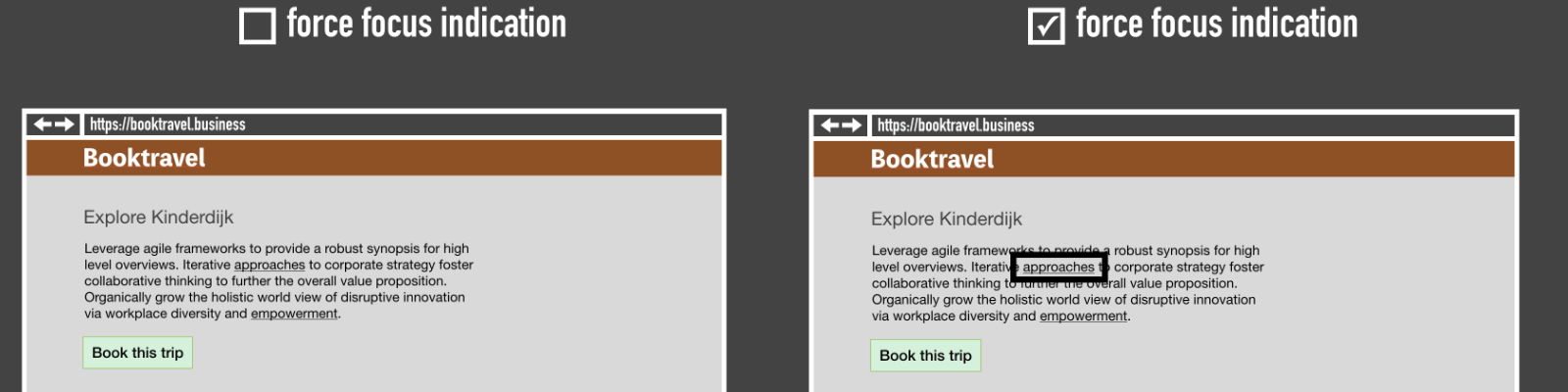 A simplified example of what “force focus indication” could look like
A simplified example of what “force focus indication” could look like
I am not aware of any browsers that implement this, but believe it could be an effective way to mitigate a common problem.
Update 26 April 2021: From Chrome 86, there is a Quick Highlight functionality that can be turned on in settings://accessibility. It will force focus outlines on any interactive element, even if the website didn’t provide any. The outline disappears after a few seconds.
Autoplay optional
There’s a number of potential accessibility problems with autoplaying content:
- autoplayed audio can get in the way for screenreader users trying to navigate (see Understanding 1.4.2)
- some autoplayed content can be in the way for people with attention deficit disorders (see Understanding 2.2.2)
- certain autoplayed videos (notably with flashing content) could cause seizure (see Web accessibility for seizures and physical reactions on MDN).
Some websites fix this automatically now. Twitter disabled animated PNGs after they had been used to attack users with epilepsy.
Browsers could fix such issues automatically, too… what if they had a setting that would never allow anything to autoplay? It turns out, Firefox has a flag for this. In about:config, you can set image_animation_mode to none, or once if you prefer (via PCMag). For Chromium, there are plugins.
Block navigation
When every page on a website starts with a bunch of navigation and header elements, it can be cumbersome to users of some assistive tech. If you use a system that reads out web pages sequentially, you don’t want to listen to the navigation menu for every page you go to. 2.4.1 Bypass Blocks exists for this reason, and many websites implement it with a “skip link” (e.g. “Skip to content”) that lets users jump to the content they need.
Browsers can determine blocks of repeated content between pages, especially if they are marked up as labeled regions (see: Labeling regions). If a page has one <main> element, browsers could provide navigation to skip to that element.
Wrapping up
In an ideal world, websites ensure their own accessibility, so that they can do it in a way that works with their content and (sometimes) their brand. Website owners have the responsibility to make their stuff accessible, not browsers or other tools.
Yet, when websites ship with accessibility problems, browsers could fix some. They could automatically “fix” zoomability, readability, colour contrast, focus indication, autoplay and block navigation. If they did, users need to rely less on what websites provide them.
Originally posted as Could browsers fix more accessibility problems automatically? on Hidde's blog.
2019 in review
Wow, the year only has 8 days left 😱! Time for a review, with some useless stats and links to things I worked on.
Like last year, I’ve divided this into highlights and things I learned.
Highlights
Projects
In the first half year of 2019, I continued my project at Mozilla’s Open Innovation team, building their People directory, and worked in the City of The Hague on accessibility and the internal design system.
In July I started a new project: at the W3C’s Web Accessibility Initiative (WAI), I am now working as part of the European Commission-funded WAI-Guide project. My work there is focused on improving the accessibility of/in tools that create web content, like CMSes. In short: we want more accessibility both for content editors (a good editing experience) and for end users (good output).
Apart from my work at the W3C, I’ve been doing the occasional WCAG audit and accessibility/CSS workshop in my own capacity too.
Speaking
Last year I spoke at my first conference. This year I got the opportunity to do new (and some older) talks in various places, of which some were as part of my project at the W3C/WAI.
In March, I did a talk called It’s the markup that matters at De Voorhoede. It was part of their Future Proof Components event, and covered building accessible components, accessibility trees and the AOM.
At WordCamp Rotterdam and Inclusive Design Ghent, I shared 6 ways to make your site more accessible, based on my experience looking at common accessibility problems that front-end developers can do something about.
In October, I presented a very short lightning talk at the Web We Want session at View Source Conference, about how some accessibility problems could cease to exist if browsers would automatically fix them. The problems: zoomability, readability, color contrast and focus indication (the first three are each solved in at least one browser, the fourth has not). This talk, shockingly, won both the jury and audience award.
Also in October was a talk called Breaking barriers with your CMS at the Fronteers Jam Session (on behalf of W3C/WAI). This presented some of my recent work at WAI: it explained ATAG and the role of the CMS in accessibility efforts.
At the Design in Government Conference in November, I talked about the case for web accessibility from philosophical ethics, again on behalf of W3C/WAI, and I did an updated version of my graphic design on the web talk in Dutch for Freshheads in Tilburg.
Then in December, I joined dotCSS to talk about the history of CSS: On the origin of cascades put some of that in a Darwin-themed talk. The venue was enormous and intimidating, and there was transport strikes, but the event itself was excellent, with a great atmosphere and very well organised.
I also did a number of in-house talks and workshops, about CSS Layout, ARIA and accessibility guidelines.
Reading
I read much more than last year (72 books so far), and have written more about books on this blog (see reading list about equality and reading list about tech and society). Reading more books helped me read less social media, watch less video and generally relax more. Please become my friend on Goodreads (it’s not great, but if more people join we can all share recommendations)!
Some notes:
- Audiobooks are great as you can read them in situations where holding a book doesn’t work (e.g. walking a dog, housework)
- To read more, finding the right books is half of the work (I mean, not literally… but it is important). I found more people to follow on Goodreads, keep a close eye on the literary supplements in the papers and love posts like 2018: books in review by Karolina Szczur.
- Dutch libraries have ebooks and audiobooks that can be ‘borrowed’ via apps.
Writing
This year I wrote 24 posts (including this one), which means I have now over 100 posts in total on this blog.
Some posts that people found interesting:
- On the importance of testing with content blockers
- Component frameworks and web standards on my first experience using a front-end framework
- Naming things to improve accessibility on the importance of accessible names in things like buttons, links and tables
- Baking accessibility into components: how frameworks help: frameworks can get a bad name in the accessibility world, but I increasingly think when used by accessibility-aware developers, they can make things better, not worse
- Meaning without markup: Accessibility Object Model: a primer on the Accessibility Object Model, a technology that is still under development and potentially interesting for a variety of reasons
I also contributed to the Mozilla Hacks blog, writing Indicating focus to improve accessibility and How accessibility trees inform assistive tech. Thanks to Havi Hoffman for the opportunity!
Cities
This year I traveled to Antwerp, Berlin, Bristol, Essen, Ghent, Nice, Paris, Taipei and Vienna, using trains where possible, but I need to do better at that.
Things I learned
Here’s some random things that I learned about in the past year:
- Recently I started working on an app with Svelte, the front-end framework that doesn’t ship in its entirety to the user’s runtime, but tries to compile as much as possible to vanilla JavaScript. Small bundles, yay!
- As I started my project at the W3C, I learned a lot the standards process, the dynamics in Working Groups and the bots that help run teleconferences.
- A large part of my work centered around authoring tools, or tools that create web content, and how they can help bring more accessibility in the world.
- I became increasingly aware of the role of surveillance capitalism in the world.
- I learned to love AirTable as a way to organise and plan the non-coding parts of my work, which are becoming a larger part of the whole
In any case, I’d like to thank the readers of this blog for reading and sharing the posts I’ve published, it means the world to me.
I wish you all a great 2020!
Originally posted as 2019 in review on Hidde's blog.
Tech vs society: a reading list
Within the bubble of technologists, the future looks bright and exciting. Outside of it, worried scholars and publicists have written a lot of books about the dangers of Big Tech, surveillance and the power of the market. This is a list of some interesting reads to better understand the impact of technology on society.
This may sound depressing, and it is, to some extent. The world is doomed and it is technologists’ fault! But when we understand better how technology, the tech sector and “computational thinking” fit in the context of society, it will get easier to decide whether we should push back.
As always, this reading list is what I happened to read on the subject, there are lots of other interesting publications out there.
How power dynamics changed
I already wrote about The Age of Surveillance Capitalism before, but I wanted to re-include it here. This book really ought to be the first item on a list of books about how tech impacts society. It defines “surveillance capitalism” and shows its workings in great detail. As I said in my review, it is not a quick read, but absolutely recommended for anyone who works in tech. We’ve got to understand this if we want to make things right.
The Age of Surveillance Capitalism by Shoshana Zuboff

A critique of “disruptive” technologies
In his fantastic Radical Technologies, “to be played at maximum volume” as the last page says, Adam Greenfield explains and critically evaluates a wide range technologies that are supposedly the future, including internet of things, augmented reality, blockchain, 3D printing and machine learning. His angle is not “wow, exciting!”, but ”what is this, is it really as good as promised, and how will large-scale deployment impact society?”. I wish we would all adapt the same mindset when assessing new tech, because there are many reasons to oppose these “radical” technologies. Blockchain doesn’t scale, internet of things devices have major security and privacy implications and machine learning is, despite many practical applications, often not fully misunderstood (as people tend to forgot that data is not neutral, not objective and always a subset of reality). The book ends with a number of future scenarios, ranging from utopias to dystopias, which help ask the question: “what do we want a tech-driven society to look like?”
Radical Technologies by Adam Greenfield
Has Big Tech lost its soul?
Many of Silicon Valley’s big companies once started with idealistic mantras and values, like ‘Don’t be evil’ and ‘Information wants to be free’, but the tide has turned. The book shows how (excerpt from the cover):
a world where “information wants to be free” became one in which we are the product being monetized, how the geeks tinkering with motherboards in their basements grew to be arrogant billionaires monopolizing the lion‘s share of the economy, and how the “democratized” internet we were promised can threaten the very fabric of our democracy.
Foroohar brilliantly explains where it went wrong. Tech companies made their products extremely addictive with the help of behaviorist psychology. Secondly, they have become monopolies in ways we haven’t seen before by both creating the market and operating in it. Thirdly, they got heavily involved in government with far-reaching lobbying for tax cuts and deregulation and by lending their targeted advertising platforms (as well as their consultants (!) for advice) to political campaigns. All of this is enabled and strengthened by surveillance capitalism.
Foroohar backs up her arguments with extensive research, and provides solutions, too. Is it depressing? Well, slightly, but it certainly left me with the feeling that having the picture painted so clearly will help address it.
Don’t Be Evil - The Case Against Big Tech by Rana Foroohar
What government surveillance looks like
The extent of Big Tech’s collection of personal data may be extraordinary, but the government’s mass surveillance programs are as disturbing, as Edward Snowden’s 2013 revelations have shown in great detail. In Permanent Record, Snowden tells two histories: that of his own growing up and that of how the intelligence community (IC) got more and more powerful after 9/11. I found the personal stories interesting, the analysis thorough and the details thought-provoking. He makes useful semantic distinctions; for instance, he explains how metadata is more intimate than content data, because we create it unknowingly, rather than thoughtfully. The book is full of wordplay… a “permanent record” is what this book is of Snowden’s life, but also what the intelligence communmity keeps of every citizen. “Hacking” is what Snowden used to do as a kid to minimise time spent on homework, but also what would become part of his work and revelations.
Permanent Record by Edward Snowden
The impact of tech company culture on society
Super Pumped is New York Times journalist Mike Isaac’s book about Uber. It gives detailed accounts of the company’s founder, culture and attitude. Three things that are are, it turns out, closely interrelated. The book’s odd name is literally one of Uber’s corporate “values”, and yes, I too was surprised to read that this company has those (given the plethora of scandals on so many different aspects of human dignity). There are the accounts of bad things that happened, but then there’s also how the company tried to cover those bad things by hiring prominent PR firms. I understand… every organisation above a certain size will have people who work to maintain and defend the company’s public image. Sure. But this book shows it clearly Uber doesn’t care, the company carries out an agenda that benefits few and hurts many, and has its bro-y culture leak into society in many bad ways. This has definitely put Uber on the top of my list of companies I would never want to work for.
Super Pumped by Mike Isaac

Political activism through technology
When an anthropologist studies a hacker slash activist movement, it might just yield a super interesting book about online culture. Hacker, Hoaxer, Whistleblower, Spy by Gabriella Coleman is a investigative study of Anonymous, with a look into what they do, want and think, completed with IRC logs, which I think were a great way to provide a look into online culture. Sometimes she talks a little too much about herself, but I feel it kind of works in this context. This book gives some interesting insights into Anonymous, the “lulz” and the motivations between some of the group’s core members.
Hacker, Hoaxer, Whistleblower, Spy: The Many Faces of Anonymous by Gabriella Coleman
Originally posted as Tech vs society: a reading list on Hidde's blog.
Breaking barriers with your CMS
A couple of weeks ago, I joined the Fronteers Jam Session to talk about something that I’ve been working on in the last couple of months: the ways in which CMSes can bring accessibility benefits. This is a written version of that talk.
Note that these are just some examples of things that CMSes can do… truth is, I only had ten minutes. But still, I’m hoping more people will think of CMSes as accessibility accelerators, as there is lots of potential!
From one block of content to lots of content blocks
As an industry, we have gotten a lot better at designing content on the web since the early days. Away are the times of boring looking documents with little white space and ineffective typography.
 We have gotten better at web design since this.
We have gotten better at web design since this.
Part of why we got better, is that modern CSS has gotten some exciting new features in recent years. We now have things like variable fonts, HSL colours, blend modes and floats that are not rectangular. And of course, there’s this now widely supported new lay-out mode: Grid Layout. It lets us be intentional about white space. We can lay content out in ways that we truly did not have before.
Something else that has changed is how we thing about what we are designing. Thanks to the work of people like Alla Kholmatova (Design Systems) and Brad Frost (Atomic Design), we have, as an industry, started to think about our work in terms of components or patterns… distinct pieces of functionality, rather than full, all-encompassing pages.

This leaves us with a new content management challenge. Previously, these long documents could be edited with one big block of WYSIWYG-text. Components require something different, you would probably create fields for every bit of data they contain.
A teaser component might have fields for a title, sub title, call to action text and link destination, for instance. For front-end developers, that might mean you can have all this data as strings, and wrap it in whatever HTML makes most sense. This isn’t necessarily new or recent, many CMSes have had this option for years, and it is has become the standard in headless systems. But still, many large organisations don’t.
 Example component-specific edit screen
Example component-specific edit screen
There is also a different content management trend that addresses our new component-based world: visual editors. Or, as they’re sometimes referred to: “no code editors”. This might sound worrying to all front-end developers, because when you wrap markup around data, you can do all sorts of good for performance, code quality and accessibility. Having a system deal with all of that automatically is… scary? And what about accessibility specifically, what if this harms actual users?
I could turn this question around… what if CMSes benefit actual users, by having accessibility built in?
The accessibility standard for CMSes
Accessibility standards consider CMSes as part of a larger group, that also includes other tools, like Learning Management Systems (LMS), wikis, social media, WYSWIYG editors, ”Save as HTML” functionality… basically everything that creates web content or facilitates the creation of HTML. These tools that create web content are also known as authoring tools. They can potentially improve a lot of accessibility at once.
Among a number of standards and specifications, the W3C has published three standards for web accessibility (“Accessibility Guidelines”):
- WCAG is for web content, adopted by governments worldwide
- UAAG is for browsers (“user agents”)
- ATAG is for authoring tools, like CMSes
So yes, there is a standard specifically about the accessibility of authoring tools, including CMSes and other things that produce HTML (see also: ATAG: the standard for accessibility of content creation).
There are two things that ATAG requires from CMSes: they should be accessible themselves (i.e. work for people with disabilities), and they should encourage accessibility (i.e. produce and assist content editors with producing accessible output).
The editing experience
Creating an accessible editing experience means that people with disabilities have no barriers to create content: they can use the buttons, understand relevant context and access the interface with the input method that works for them.
To give some examples, and yes, these also exist on websites that are not CMSes:
- Accessible names
- A common accessibilitity issue is that the buttons in the interface are visually just icons. To make those work for users of assistive technologies, it is important that they have proper labels or accessible names. More about this in Naming things to improve accessibility
- Keyboard accessibility
- Something else that is common in CMSes is that they require a mouse to be fully used. By ensuring keyboard accessibility, you can make the interface work for various groups of people. This includes indicating what has focus. See also: Indicating focus to improve accessibility
- Zooming
- Some users will be using the CMS interface with their screen set to zoom in considerably, say 200 to 300 percent. This works well in the type of text documents I discussed at the start. On the web, text just reflows. It becomes more tricky in complex CMS interfaces, because there could be floating and sticky things that overlap with content when zoomed too much. See: Test content scaling
An interesting overview of what accessibility issues could look like in a real CMS is the crowdsourced accessibility audit that was done for WordPress’ new Gutenberg editor. As someone who is interested in the accessibility of content management systems, I am grateful that this was released publicly, this way everyone can learn.
The output
Apart from breaking barriers in the editing experience, we can also break barriers for users of the actual website. If we improve how HTML is produced by a CMS, we can potentially make a difference for all pages and sites produced by it.
Alt attributes
Most front-end developers will be aware images require alternative text in their alt attribute (or a conscious decision to leave it blank). Yet lots of websites lack it on some of their images. I don’t think this is because people aren’t aware of what the alt attribute is for. This could simply be a responsibility issue: the developer only built the template, the content editor only used the template, etc… Somewhere in between the attribute did not get shipped to the user.
The CMS could be smart about this. It could:
- throw an error for missing alt attributes when an editor saves a page
- provide information on what makes a good alt text
- come with a checkbox that says “This needs no alternative, it is a decoration or already covered in other text”
- throw an error if someone tries to link an image that has no
alt(becausealtattributes can become link texts)
Spelling
If you’ve accidentally used “Swbmit” as a button text, that might not impact visual users so much, as they will probably see from the visual context what the word should be. For someone using a tool like Dragon NaturallySpeaking, which lets users tell their computer which buttons to click, the mismatch could be more problematic. For someone who uses a screenreader, it could also be annoying to have misspelled content, because if it is misspelled, it will get mispronounced , too.
What if the CMS had a built-in spelling checker? That way, we could identify issues before they exist, and fix them before they get shipped to the user.
Colour contrast
When your site uses that design pattern where there is a text layed over a photo, it matters a lot what the photo is. Is it a dark-ish photo with light text on it, or are text and photo both light? The latter could lead to super low contrast, and with that, barriers for all sorts of users. This can affect people with various kinds of visual impairments, but also people who are outside in the sun, or those who have turned Brightness on their phone down to safe battery life.
Colour contrast issues can be programmatically detected, so why not do it right in the CMS? After uploading a new header image, the CMS could do a quick contrast check and display an error if the page no longer meets the criteria. Again, we could identify issues before they exist, and fix before shipping.
Whether it be with automated checks, carefully crafted content editing screens, extensive documentation of accessibility features… if we manage to bring some of our accessibility fixing to the CMS, we may be able to prevent barriers from shipping to users.
Conclusion
As front-end developers, we are all involved in the creation of web content. With this post, I hope to have given some examples of how CMSes can help create more accessible web content. Of course, it is just a couple of examples… but I think there are CMS-based solutions like this for a lot of different accessibility problems that we see on the web today. To be continued!
Originally posted as Breaking barriers with your CMS on Hidde's blog.