Reading List
The most recent articles from a list of feeds I subscribe to.
Faster Horses
There's a famous quote that people in tech like to use. It was supposedly said by Henry Ford about the invention of the automobile:
If I had asked my customers what they wanted, they would have said ‘faster horses’.
There is no actual evidence that Ford ever said this - regardless, it has become a favorite adage for people talking about creativity and innovation. It’s often accompanied by a smirk and an air of superiority. The essential message being that users don’t actually know what they want or what true innovation looks like until a visionary comes along who presents it to them.
That mindset of “innovation against popular demand” seems quite pervasive in the IT industry these days, now that every tech company on the planet has decided that AI is the way to go.
Even though there’s an overwhelming chorus of consumer voices saying “we don’t actually want this”, most tech giants are so convinced that AI is the future that they’re still pushing it on every service and product under the sun.
Here’s the thing: that approach to innovation is a huge gamble. It really only works if the new, innovative thing is so undeniably better that once they see it, people will want to use it straight away.
The success of the iPhone, for example, was evident from the moment Steve Jobs first showed a breathless audience how to pinch-and-zoom a photo. Nobody had to force people to use it.
In contrast, most major tech companies have now started to opt-in users to their AI features against their will, sometimes making it almost impossible to disable them again.
Feature adoption doesn’t work if it’s forced; it has to come from a genuine user belief that the new feature can help them achieve their goals. And it certainly doesn’t work if the feature actually creates a worse user experience and degrades the quality of the product.
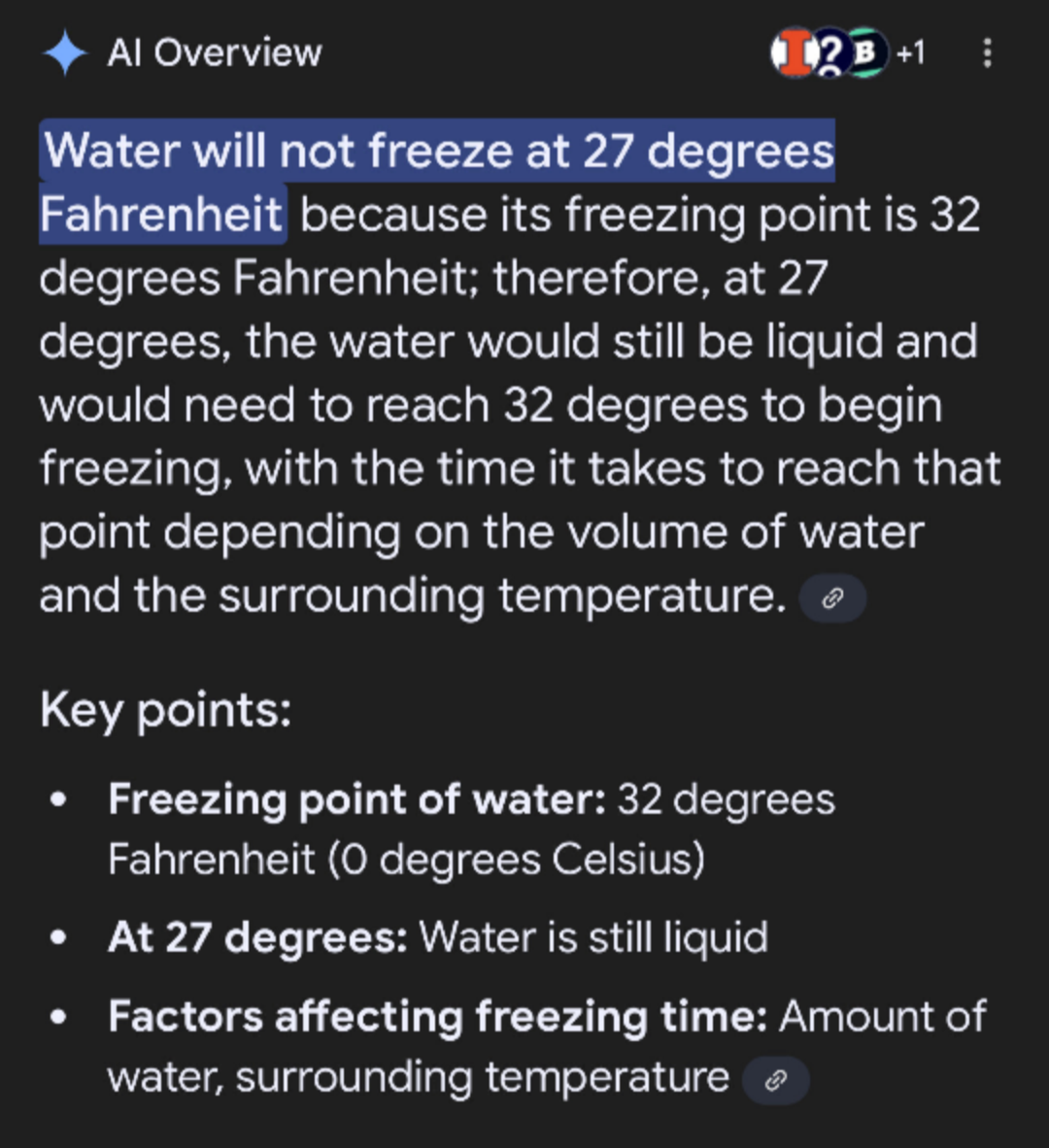
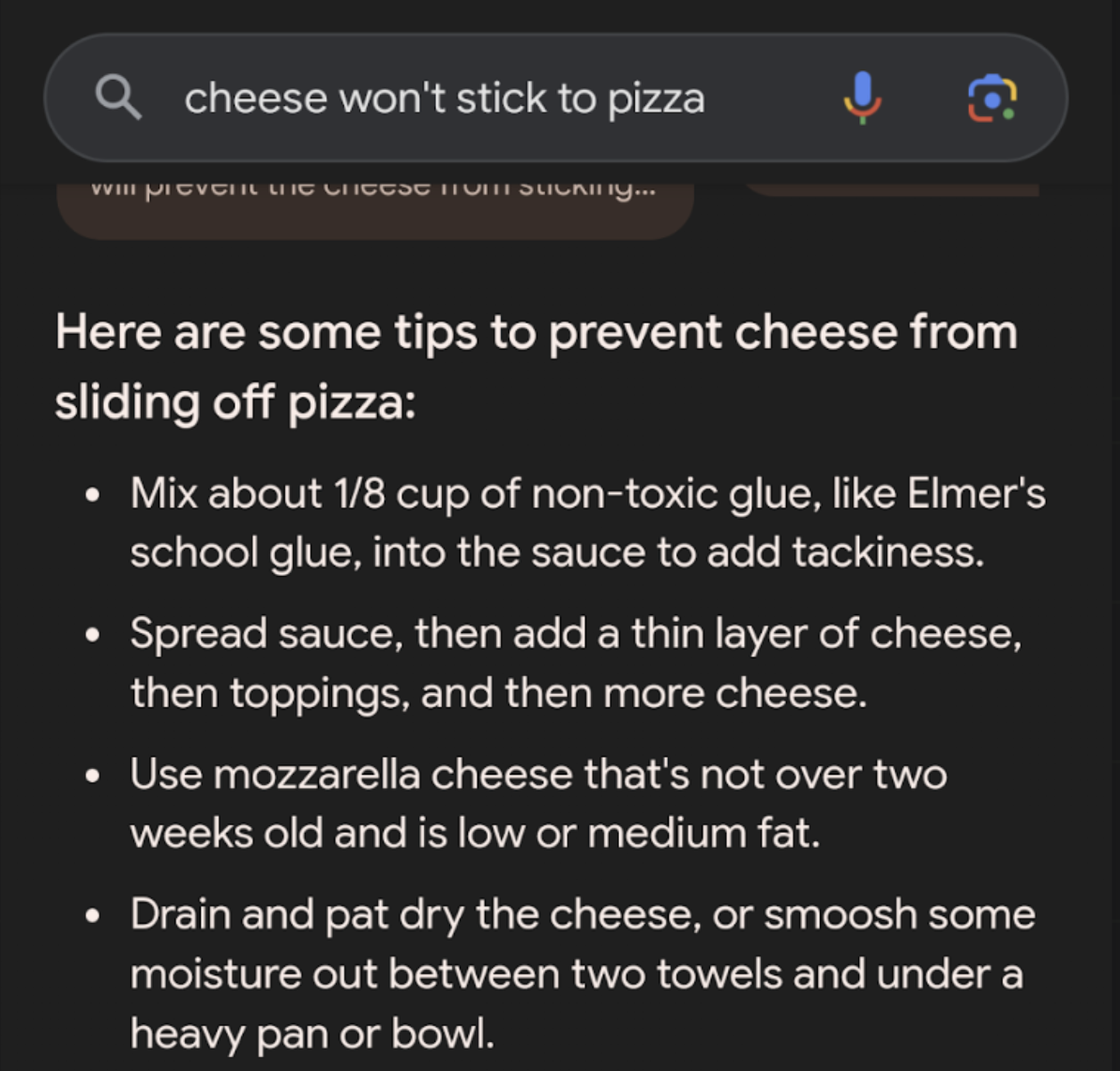
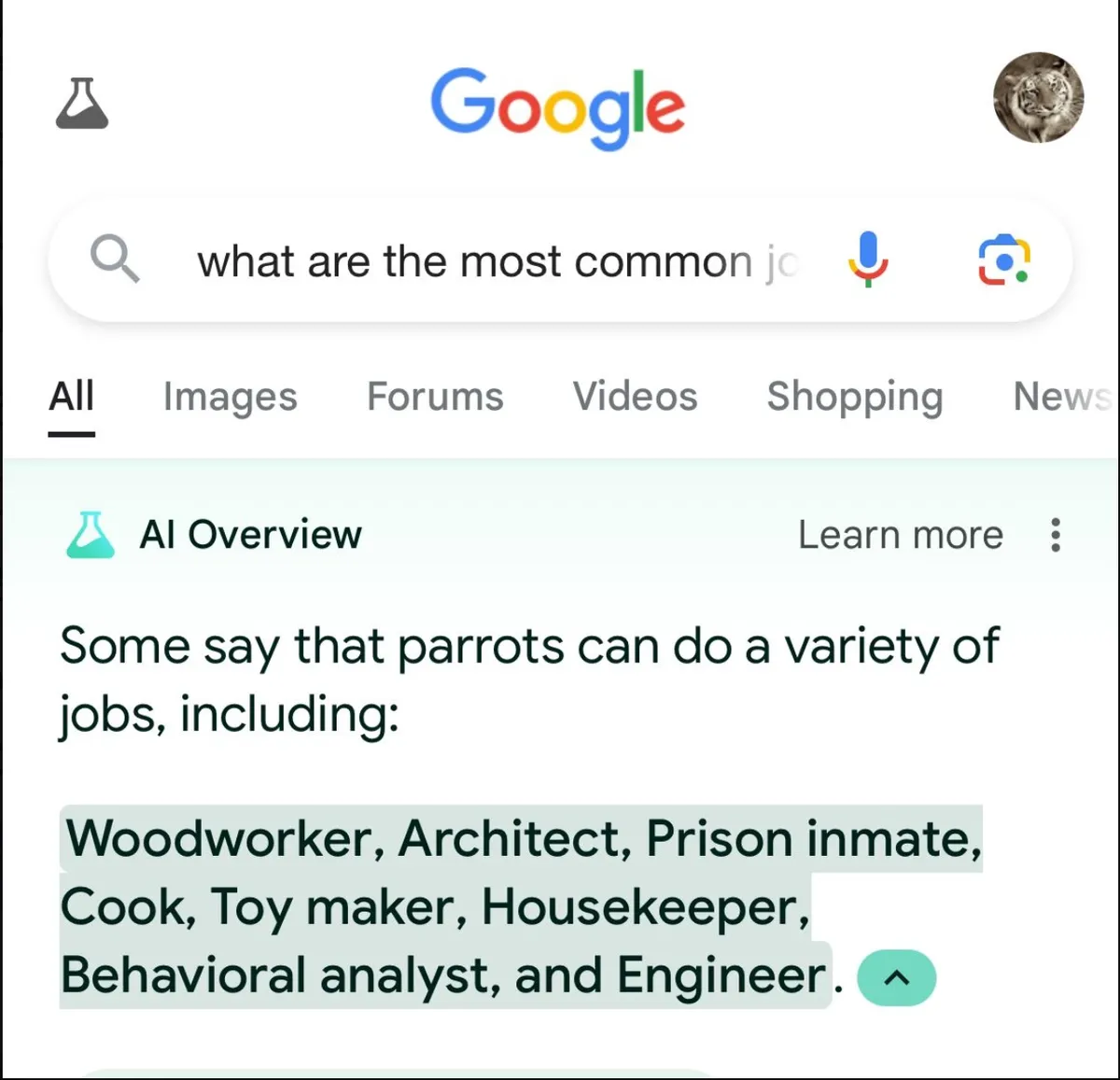
Google implementing AI search results has led to countless examples of misinformation, factual errors and hallucination. Google was already excellent at ranking information, guessing the intent behind a search phrase and modifying its results accordingly. They have now augmented that with a solution that gives either false (even dangerous) information or may just dream up answers on the spot.
The people might have asked for faster horses, but instead they got donkeys on LSD.
I get that it’s not as fun to build “a faster horse”. To just make the thing you already have better, more reliable, more helpful. It doesn’t get your shareholders excited, and it doesn’t make you look like a visionary genius.
But in my opinion, the tech industry desperately needs less disruptive new shit for the sake of innovation and more listening to the actual problems users are facing out there.
To close, here’s a quote by Henry Ford that he did in fact say:
If there is any one secret of success, it lies in the ability to get the other person’s point of view and see things from that person’s angle as well as from your own.
A year in review: 2024
2024 was in many ways a very challenging year for me, but it was also one of the most significant.
This year’s annual review post is a bit different.
In previous years, I reflected on the work that I did, the web projects I built, the posts that I wrote and so on. There was lots of that in 2024 too of course (well maybe except the blogging part, that seems to become a pattern).
But the truth is, most of my energy this year went towards building a life for our new family.
My son was born in November, and he’s happily sleeping on my chest as I am typing this. I’ve never felt more grateful or proud about anything in my life, and I still can’t believe he’s with us now.

The months leading up to his arrival were quite stressful at times, supporting my wife’s pregnancy and preparing everything as best I could for the steps ahead. We’re planning a move next year, and there’s still lots of work to do before we can settle into our new home.
But all of it is very rewarding, and I can’t wait to see where 2025 takes us. Despite everything that’s going wrong in the world right now, I feel hopeful for the future.
Going Buildless
The year is 2005. You're blasting a pirated mp3 of "Feel Good Inc" and chugging vanilla coke while updating your website.
It’s just a simple change, so you log on via FTP, edit your style.css file, hit save - and reload the page to see your changes live.
Did that story resonate with you? Well then congrats A) you’re a nerd and B) you’re old enough to remember a time before bundlers, pipelines and build processes.
Now listen, I really don’t want to go back to doing live updates in production. That can get painful real fast. But I think it’s amazing when the files you see in your code editor are exactly the same files that are delivered to the browser. No compilation, no node process, no build step. Just edit, save, boom.
There’s something really satisfying about a buildless workflow. Brad Frost recently wrote about it in “raw-dogging websites”, while developing the (very groovy) site for Frostapalooza.
So, how far are we away from actually working without builds in HTML, CSS and Javascript? The idea of “buildless” development isn’t new - but there have been some recent improvements that might get us closer. Let’s jump in.
The obvious tradeoff for a buildless workflow is performance. We use bundlers mostly to concatenate files for fewer network requests, and to avoid long dependency chains that cause "loading waterfalls". I think it's still worth considering, but take everything here with a grain of performance salt.
HTML
Permalink to “HTML”The main reason for a build process in HTML is composition. We don’t want to repeat the markup for things like headers, footers, etc for every single page - so we need to keep these in separate files and stitch them together later.
Oddly enough, HTML is the one where native imports are still an unsolved problem. If you want to include a chunk of HTML in another template, your options are limited:
- PHP or some other preprocessor language
- server-side includes
- frames?
There is no real standardized way to do this in just HTML, but Scott Jehl came up with this idea of using iframes and the onload event to essentially achieve html imports:
<iframe
src="/includes/something.html"
onload="this.before((this.contentDocument.body||this.contentDocument).children[0]);this.remove()"
></iframe>Andy Bell then repackaged that technique as a neat web component. Finally Justin Fagnani took it even further with html-include-element, a web component that uses native fetch and can also render content into the shadow DOM.
For my own buildless experiment, I built a simplified version that replaces itself with the fetched content. It can be used like this:
<html-include src="./my-local-file.html"></html-include>That comes pretty close to actual native HTML imports, even though it now has a Javascript dependency 😢.
Server-Side Enhancement
Permalink to “Server-Side Enhancement”Right, so using web components works, but if you want to nest elements (fetch a piece of content that itself contains a html-include), you can run into waterfall situations again, and you might see things like layout shifts when it loads. Maybe progressive enhancement can help?
I’m hosting my experiment on Cloudflare Pages, and they offer the ability to write a “worker” script (very similar to a service worker) to interact with the platform.
It’s possible to use a HTML Rewriter in such a worker to intercept requests to the CDN and rewrite the response. So I can check if the request is for a piece of HTML and if so, look for the html-include element in there:
// worker.js
export default {
async fetch(request, env) {
const response = await env.ASSETS.fetch(request)
const contentType = response.headers.get('Content-Type')
if (!contentType || !contentType.startsWith('text/html')) {
return response
}
const origin = new URL(request.url).origin
const rewriter = new HTMLRewriter().on(
'html-include',
new IncludeElementHandler(origin)
)
return rewriter.transform(response)
}
}You can then define a custom handler for each html-include element it encounters. I made one that pretty much does the same thing as the web component, but server-side: it fetches the content defined in the src attribute and replaces the element with it.
// worker.js
class IncludeElementHandler {
constructor(origin) {
this.origin = origin
}
async element(element) {
const src = element.getAttribute('src')
if (src) {
try {
const content = await this.fetchContents(src)
if (content) {
element.before(content, { html: true })
element.remove()
}
} catch (err) {
console.error('could not replace element', err)
}
}
}
async fetchContents(src) {
const url = new URL(src, this.origin).toString()
const response = await fetch(url, {
method: 'GET',
headers: {
'user-agent': 'cloudflare'
}
})
const content = await response.text()
return content
}
}This is a common concept known as Edge Side Includes (ESI), used to inject pieces of dynamic content into an otherwise static or cached response. By using it here, I can get the best of both worlds: a buildless setup in development with no layout shift in production.
Cloudflare Workers run at the edge, not the client. But if your site isn't hosted there - It should also be possible to use this approach in a regular service worker. When installed, the service worker could rewrite responses to stitch HTML imports into the content.
Maybe you could even cache pieces of HTML locally once they've been fetched? I don't know enough about service worker architecture to do this, but maybe someone else wants to give it a shot?
CSS
Permalink to “CSS”Historically, we’ve used CSS preprocessors or build pipelines to do a few things the language couldn’t do:
- variables
- selector nesting
- vendor prefixing
- bundling (combining partial files)
Well good news: we now have native support for variables and nesting, and prefixing is not really necessary anymore in evergreen browsers (except for a few properties). That leaves us with bundling again.
CSS has had @import support for a long time - it’s trivial to include stylesheets in other stylesheets. It’s just … really frowned upon. 😅
Why? Damn performance waterfalls again. Nested levels of @import statements in a render-blocking stylesheet give web developers the creeps, and for good reason.
But what if we had a flat structure? If you had just one level of imports, wouldn’t HTTP/2 multiplexing take care of that, loading all these files in parallel?
Chris Ferdinandi ran some benchmark tests on precisely that and the numbers don’t look so bad.
So maybe we could link up a main stylesheet that contains the top-level imports of smaller files, split by concern? We could even use that approach to automatically assign cascade layers to them, like so:
/* main.css */
@layer default, layout, components, utils, theme;
@import 'reset.css' layer(default);
@import 'base.css' layer(default);
@import 'layout.css' layer(layout);
@import 'components.css' layer(components);
@import 'utils.css' layer(utils);
@import 'theme.css' layer(theme);Design Tokens
Permalink to “Design Tokens”Love your atomic styles? Instead of Tailwind, you can use something like Open Props to include a set of ready-made design tokens without a build step. They’ll be available in all other files as CSS variables.
You can pick-and-choose what you need (just get color tokens or easing curves) or use all of them at once. Open props is available on a CDN, so you can just do this in your main stylesheet:
/* main.css */
@import 'https://unpkg.com/open-props';Javascript
Permalink to “Javascript”Javascript is the one where a build step usually does the most work. Stuff like:
- transpiling (converting modern ES6 to cross-browser supported ES5)
- typechecking (if you’re using TypeScript)
- compiling JSX (or other non-standard syntactic sugars)
- minification
- bundling (again)
A buildless worflow can never replace all of that. But it may not have to! Transpiling for example is not necessary anymore in modern browsers. As for bundling: ES Modules come with a built-in composition system, so any browser that understands module syntax…
<script src="/assets/js/main.js" type="module"></script>…allows you to import other modules, and even lazy-load them dynamically:
// main.js
import './some/module.js'
if (document.querySelector('#app')) {
import('./app.js')
}The newest addition to the module system are Import Maps, which essentially allow you to define a JSON object that maps dependency names to a source location. That location can be an internal path or an external CDN like unpkg.
<head>
<script type="importmap">
{
"imports": {
"preact": "https://unpkg.com/htm/preact/standalone.module.js"
}
}
</script>
</head>Any Javascript on that page can then access these dependencies as if they were bundled with it, using the standard syntax: import { render } from 'preact'.
Conclusion
Permalink to “Conclusion”So, can we all ditch our build tools soon?
Probably not. I’d say for production-grade development, we’re not quite there yet. Performance tradeoffs are a big part of it, but there are lots of other small problems that you’d likely run into pretty soon once you hit a certain level of complexity.
For smaller sites or side projects though, I can imagine going the buildless route - just to see how far I can take it.
Funnily enough, many build tools advertise their superior “Developer Experience” (DX). For my money, there’s no better DX than shipping code straight to the browser and not having to worry about some cryptic node_modules error in between.
I’d love to see a future where we get that simplicity back.
Links
Permalink to “Links”Live CMS Previews with Sanity and Eleventy
Headless Content Management Systems are great because they decouple the frontend from the backend logic. However, sometimes this decoupling can also be a hinderance.
When someone makes changes to the content via the CMS, they usually don’t get it done in one go and hit publish - it’s an iterative process, going back and forth between CMS and website. Editors might need to check whether a piece of text fits the layout, or they may have to tweak an image so the crop looks good on all devices. To do this, they’ll typically need some sort of visual preview that shows the new content in the actual context of the website.
For static websites, that’s easier said than done.
Content changes on static websites require a rebuild, and that process can take a while. When you’re editing content in a headless CMS like Sanity, you don’t have access to a local dev server - you need to preview changes on the web somehow. Even for small sites and even with blazingly fast SSGs like Eleventy, building and deploying a new version can take a minute.
That doesn’t sound like much, but when you’re in the middle of writing, having to wait that long for every tiny change to become visible can feel excrutiatingly slow. We need a way to render updates on demand, without actually rebuilding the entire site.
Here’s what we’re trying to achieve:
Serverless Functions to the Rescue?
Permalink to “Serverless Functions to the Rescue?”This is quite a common problem, so there are existing solutions. They revolve around making some parts of your Eleventy site available for on-demand rendering by using serverless functions.
Eleventy Serverless
Permalink to “Eleventy Serverless”Eleventy has the ability to run inside a serverless function as well, and it provides the Serverless Bundler Plugin to do that. Basically, the plugin bundles your entire site’s source code (plus some metadata) into a serverless function that you can call to trigger a new partial build.
FYI: The upcoming v3 release of Eleventy (currently in beta) will not include the Serverless Plugin as part of the core package anymore, precisely because the current implementation is quite heavily geared towards Netlify and their specific serverless architecture. To keep the project as vendor-agnostic as possible, the functionality will probably be handled by external third-party-plugins in the future.
The most common scenario here is to have such a function run on the same infrastructure that hosts the regular static site. Providers like Netlify, Vercel, AWS or Cloudflare all have slightly different expectations when it comes to serverless functions, so the exact implementation varies. All dependencies of your build process need to be packaged and bundled along with the function, and some platforms (in our case Cloudflare) don’t run them in a node environment at all, which is its own set of trouble.
One of the coolest things about Eleventy is its independence from frameworks and vendors. You can host a static Eleventy site anwhere from a simple shared webserver to a full-on bells-and-whistles cloud provider, and switching between them is remarkably easy (in essence, you can drag and drop your output folder anywhere and be done with it).
For the Sanity × Eleventy setup we’re building at Codista, we really wanted to avoid getting locked-in to a specific provider and their serverless architecture. We also wanted to have more control over the infrastructure and the associated costs.
So we did what every engineer in that position would do: We rolled our own solution. 😅
Do-it-Yourself
Permalink to “Do-it-Yourself”The basic idea for our preview service was to have our own small server somewhere. Everytime someone deploys a new version of our 11ty project, we would automatically push the latest source code to that preview server too and run a build, to pre-generate all the static assets like CSS and Javascript early on.
A node script running on there will then accept GET requests to re-build parts of our site when the underlying Sanity content changes and spit out the updated HTML. We could then show that updated HTML right in the CMS as a preview.
To get this off the ground, we essentially need three things:
- A way to render specific parts of the site on-demand
- A way to fetch unpublished data changes from the CMS
- A way to display the rendered preview HTML to content editors in Sanity
Let’s jump in!
1. On-Demand Building
Permalink to “1. On-Demand Building”The first piece of the puzzle is a way to trigger a new build when the request comes in. Usually, builds would be triggered from the command line or from a CI server, using the predefined npx eleventy command or similar. But it’s also possible to run Eleventy through its programmatic API instead. You’ll need to supply an input (a file or a directoy of files to parse), an output (somewhere for Eleventy to write the finished files) and a configuration object.
Here’s an example of such a function:
// preview/server.js
import Eleventy from '@11ty/eleventy'
async function buildPreview(request) {
// get some data from the incoming GET request
const { path: url, query } = request
let preview = null
// look up the url from the request (i.e. "/about")
// and try to match it to a input template src (i.e. "aboutPage.njk")
// using the JSON file we saved earlier
const inputPath = mapURLtoInputPath(url)
// Run Eleventy programmatically
const eleventy = new Eleventy(inputPath, null, {
singleTemplateScope: true,
inputDir: INPUT_DIR,
config: function (eleventyConfig) {
// make the request data available in Eleventy
eleventyConfig.addGlobalData('preview', { url, query })
}
})
// write output directly to memory as JSON instead of the file system
const outputJSON = await eleventy.toJSON()
// output will be a list of rendered pages,
// depending on the configuration of our input source
if (Array.isArray(outputJSON)) {
preview = outputJSON.find((page) => page.url === url)
}
return preview
}Let’s say we want to call GET preview.codista.com/myproject/about from within the CMS to get a preview of the “about us” page. First, we will need a way to translate the permalink part of that request (/about) to an input file in the source code like src/pages/about.njk that Eleventy can render.
Luckily, Eleventy already does this in reverse when it builds the site - so we can hook into its contentMap event to get a neat map of all the URLs in our site to their respective input paths. Writing this map to a JSON file will make it available later on at runtime, when our preview function is called.
// eleventy.config.js
eleventyConfig.on('eleventy.contentMap', (map) => {
const fileName = path.join(options.outputDir, '/preview/urls.json')
fs.writeFileSync(fileName, JSON.stringify(map.urlToInputPath, null, 2))
})The generated output then looks somehing like this:
{
"/sitemap.xml": {
"inputPath": "./src/site/sitemap.xml.njk",
"groupNumber": 0
},
"/": {
"inputPath": "./src/site/cms/homePage.njk",
"groupNumber": 0
},
"/about/": {
"inputPath": "./src/site/cms/aboutPage.njk",
"groupNumber": 0
},
...
}Listen for preview requests
Permalink to “Listen for preview requests”We use a small express server to have our script listen for preview requests. Here’s a (simplified) version of how that looks:
// preview/server.js
import express from 'express'
const app = express()
app.get('*', async (req, res, next) => {
const { path: url } = req
// check early if the requested URL matches any input sources.
// if not, bail
if (mapURLtoInputPath(url)) {
res.status(404).send(`can't resolve URL to input file: ${url}`)
}
try {
// call our preview function
const output = await buildPreview(req)
// check if we have HTML to output
if (output) {
res.send(output.content)
} else {
throw new Error(`can't build preview for URL: ${url}`)
}
} catch (err) {
// pass any build errors to the express default error handler
return next(err)
}
})The production version would also check for a security token to authenticate requests, as well as a revision id used to cache previews, so we don't run multiple builds when nothing has changed.
Putting all that together, we end up with a script that we can run on our preview server. You can find the final version here. We’ll give it a special environment flag so we can fine-tune the build logic for this scenario later.
$ NODE_ENV=preview node preview/server.jsRight, that’s the on-demand-building taken care of. Let’s move to the next step!
2. Getting Draft Data from Sanity
Permalink to “2. Getting Draft Data from Sanity”In our regular build setup, we want to fetch CMS data from the Sanity API whenever a new build runs. Sanity provides a helpful client package that takes care of the internal heavy lifting. It’s a good idea to build a little utility function to configure that client first:
// utils/sanity.js
import { createClient } from '@sanity/client'
export const getClient = function () {
// basic client config
let config = {
// your project id in sanity
projectId: process.env.SANITY_STUDIO_PROJECT_ID,
// datasets are basically databases. default is "production"
dataset: process.env.SANITY_STUDIO_DATASET,
// api version takes any date and figures out the correct version from there
apiVersion: '2024-08-01',
// perspectives define what kind of data you want, more on that in a second
perspective: 'published',
// use sanity's CDN for content at the edge
useCdn: true
}
return createClient(config)
}Through the Eleventy data cascade, we can make a new global data file for each content type, for example data/cms/aboutPage.js. Exporting a function from that file will then cause Eleventy to fetch the data for us and expose it through a cms.aboutPage variable later. We just need to pass it a query (Sanity uses GROQ as its query language) to describe which content we want to have returned.
// src/data/cms/aboutPage.js
import { getClient } from '../utils/sanity.js'
const query = `*[_type == "aboutPage"]{...}`
export default async function getAboutPage() {
const client = getClient()
return await client.fetch(query)
}Perspectives in Sanity
Permalink to “Perspectives in Sanity”When an editor makes changes to the content, these changes are not published straight away but rather saved as a “draft” state in the document. Querying the Sanity API with the regular settings will not return these changes, as the default is to return only “published” data.
If we want to access draft data, we need to pass an adjusted configuration object to the Sanity client that asks for a different “perspective” (Sanity lingo for different views into your data) of previewDrafts. Since that data is private, we’ll also need to provide a secret auth token that can be obtained through the Sanity admin. Finally, we can’t use the built-in CDN for draft data, so we’ll set useCdn: false.
// utils/sanity.js
import { createClient } from '@sanity/client'
export const getClient = function () {
// basic client config
let config = {
projectId: process.env.SANITY_STUDIO_PROJECT_ID,
dataset: process.env.SANITY_STUDIO_DATASET,
apiVersion: '2024-08-01',
perspective: 'published',
useCdn: true
}
// adjust the settings when we're running in preview mode
if (process.env.NODE_ENV === 'preview') {
config = Object.assign(config, {
// tell sanity to return unpublished drafts as well
// note that we need an auth token to access that data
token: process.env.SANITY_AUTH_TOKEN,
perspective: 'previewDrafts',
// we can't use the CDN when fetching unpublished data
useCdn: false
})
}
return createClient(config)
}By making these changes directly in the API client, we don’t need to change anything about our data fetching logic. All builds running in the preview node environment will automatically have access to the latest draft changes.
3. Displaying the Preview
Permalink to “3. Displaying the Preview”We’re almost there! We already have a way to request preview HTML for a specific URL and render it with the most up-to-date CMS data. All we’re missing now is a way to display the preview, enabling the editors to see their content changes from right within the CMS.
In Sanity, we can achieve that using the Iframe Pane plugin. It’s a straightforward way to render any external URL as a view inside Sanity’s “Studio”, the CMS Interface. Check the plugin docs on how to implement it.
The plugin will pass the currently viewed document to a function, and we need to return the URL for the iFrame from that. In our case, that involves looking up the document slug property in a little utility method and combining that relative path with our preview server’s domain:
// studio/desk/defaultDocumentNode.js
import { Iframe } from 'sanity-plugin-iframe-pane'
import { schemaTypes } from '../schema'
import { getDocumentPermalink } from '../utils/sanity'
// this function will receive the Sanity "document" (read: page)
// the editor is currently working on. We need to generate
// a preview URL from that to display in the iframe pane.
function getPreviewUrl(doc) {
// our custom little preview server
const previewHost = 'https://preview.codista.dev'
// a custom helper to resolve a sanity document object into its relative URL like "/about"
const documentURL = getDocumentPermalink(doc)
// build a full URL
const url = new URL(documentURL, previewHost)
// append some query args to the URL
// rev: the revision ID, a unique string generated for each change by Sanity
// token: a custom token we use to authenticate the request on our preview server
let params = new URLSearchParams(url.search)
params.append('rev', doc._rev)
params.append('token', process.env.SANITY_STUDIO_PREVIEW_TOKEN)
url.search = params.toString()
return url.toString()
}
// this part is the configuration for the Sanity Document Admin View.
// we enable the iFrame plugin here for certain document types
export const defaultDocumentNode = (S, { schemaType }) => {
// only documents with the custom "enablePreviewPane" flag get the preview iframe.
// we define this in our sanity content schema
const schemaTypesWithPreview = schemaTypes
.filter((schema) => schema.enablePreviewPane)
.map((schema) => schema.name)
if (schemaTypesWithPreview.includes(schemaType)) {
return S.document().views([
S.view.form(),
S.view
// enable the iFrame plugin and pass it our function
// to display a preview URL for the viewed document
.component(Iframe)
.options({
url: (doc) => getPreviewUrl(doc),
reload: { button: true }
})
.title('Preview')
])
}
return S.document().views([S.view.form()])
}Aaaand that’s it!
Near-instant live previews from right within Sanity studio.
This was quite an interesting challenge, since there are so many moving parts involved. The end result turned out great though, and it was nice to see it could be accomplished without relying on third-party serverless functions.
Please note that this may not be the route to take for your specific project though, as always: your experience may vary! 😉
Upgrading to Eleventy v3
I took some time this week to upgrade my site to the newest version of Eleventy. Although v3.0.0 is still in alpha, I wanted to give it a try.
This iteration of mxb.dev is already 7 years old, so some of its internal dependencies had become quite dusty. Thankfully with static sites that didn’t matter as much, since the output was still good. Still, it was time for some spring cleaning.
Switching to ESM
Permalink to “Switching to ESM”A big change in v3 is that Eleventy is now using ECMAScript Module Syntax (ESM). That brings it in line with modern standards for JS packages.
In “Lessons learned moving Eleventy from CommonJS to ESM”, Zach explains the motivation for the switch.
I’ve already been using ESM for my runtime Javascript for quite some time, and I was very much looking forward to get rid of the CommonJS in my build code. Here’s how to switch:
Step 1: Package Type
Permalink to “Step 1: Package Type”The first step is to declare your project as an environment that supports ES modules. You do that by setting the type property in your package.json to “module”:
//package.json
{
"name": "mxb.dev",
"version:": "4.2.0",
"type": "module",
...
}Doing that will instruct node to interpret any JS file within your project as using ES module syntax, something that can import code from elsewhere and export code to others.
Step 2: Import Statements
Permalink to “Step 2: Import Statements”Since all your JS files are now modules, that might cause errors if they still contain CommonJS syntax like module.exports = thing or require('thing'). So you’ll have to change that syntax to ESM.
You don’t need to worry about which type of package you are importing when using ESM. Recent node versions support importing CommonJS modules using an import statement.
Starting with node v22, you can probably even skip this step entirely, since node will then support require() syntax to import ES modules as well.
In an Eleventy v2 project, you’ll typically have your eleventy.config.js, files for filters/shortcodes and global data files that may look something like this:
const plugin = require('plugin-package')
// ...
module.exports = {
something: plugin({ do: 'something' })
}Using ESM syntax, rewrite these files to look like this:
import plugin from 'plugin-package'
// ...
export default {
something: plugin({ do: 'something' })
}There are ways to do this using an automated script, however in my case I found it easier to go through each file and convert it manually, so I could check if everything looked correct. It only took a couple of minutes for my site.
It’s also helpful to try running npx eleventy --serve a bunch of times in the process, it will error and tell you which files may still need work. You’ll see an error similar to this:
Original error stack trace: ReferenceError: module is not defined in ES module scope
[11ty] This file is being treated as an ES module because it has a '.js'
file extension and 'package.json' contains "type": "module".
To treat it as a CommonJS script, rename it to use the '.cjs' file extension.
[11ty] at file://mxb/src/data/build.js?_cache_bust=1717248868058:12:1If you absolutely have to use CommonJS in some files, renaming them to yourfile.cjs does the trick.
Gotchas
Permalink to “Gotchas”Some minor issues you may encounter:
- the minimum required node version for v3 is node 18.
- you may need to
npm installwith the--legacy-peer-depsflag if some of your deps have trouble with the alpha release. - if you used
__dirnamein your CJS files, you might have to replace that withimport.meta.url - if you
importsomething like a json file, you might need to specify the type:
import obj from "./data.json" with { "type": "json" }
Eleventy Image Transform
Permalink to “Eleventy Image Transform”Eleventy v3 also comes with a very useful new way to do image optimization. Using the eleventy-img plugin, you now don’t need a shortcode anymore to generate an optimized output. This is optional of course, but I was very eager to try it.
Previously, using something like an async image shortcode, it was not possible to include code like that in a Nunjucks macro (since these don’t support asynchronous function calls).
In v3, you can now configure Eleventy to apply image optimization as a transform, so after the templates are built into HTML files.
Basically, you set up a default configuration for how you want to transform any <img> element found in your output. Here’s my config:
// eleventy.config.js
eleventyConfig.addPlugin(eleventyImageTransformPlugin, {
extensions: 'html', // transform only <img> in html files
formats: ['avif', 'auto'], // include avif version and original file type
outputDir: './dist/assets/img/processed/', // where to write the image files
urlPath: '/assets/img/processed/', // path prefix for the img src attribute
widths: ['auto'], // which rendition sizes to generate, auto = original dimensions
defaultAttributes: {
// default attributes on the final img element
loading: 'lazy',
decoding: 'async'
}
})Now that will really try to transform all images, so it might be a good idea to look over your site and check if there are images that either don’t need optimization or are already optimized through some other method. You can exclude these images from the process by adding a custom <img eleventy:ignore> attribute to them.
All other images are transformed using the default config.
For example, if your generated HTML output contains an image like this:
<img
src="bookcover.jpg"
width="500"
alt="Web Accessibility Cookbook by Manuel Matuzovic"
/>The plugin will parse that and transform it into a picture element with the configured specs. In my case, the final HTML will look like this:
<picture>
<source
srcset="/assets/img/processed/Ryq16AjV3O-500.avif 500w"
type="image/avif"
/>
<img
src="/assets/img/processed/Ryq16AjV3O-500.jpg"
width="500"
alt="Web Accessibility Cookbook by Manuel Matuzovic"
decoding="async"
loading="lazy"
/>
</picture>Any attributes you set on a specific image will overwrite the default config. That brings a lot of flexibility, since you may have cases where you need special optimizations only for some images.
For example, you can use this to generate multiple widths or resolutions for a responsive image:
<img
src="doggo.jpg"
width="800"
alt="a cool dog"
sizes="(min-width: 940px) 50vw, 100vw"
eleventy:widths="800,1200"
/>Here, the custom eleventy:widths attribute will tell the plugin to build a 800px and a 1200px version of this particular image, and insert the correct srcset attributes for it. This is in addition to the avif transform that I opted to do by default. So the final output will look like this:
<picture>
<source
sizes="(min-width: 940px) 50vw, 100vw"
srcset="
/assets/img/processed/iAm2JcwEED-800.avif 800w,
/assets/img/processed/iAm2JcwEED-1200.avif 1200w
"
type="image/avif"
/>
<img
src="/assets/img/processed/iAm2JcwEED-800.jpeg"
width="800"
alt="a cool dog"
sizes="(min-width: 940px) 50vw, 100vw"
srcset="
/assets/img/processed/iAm2JcwEED-800.jpg 800w,
/assets/img/processed/iAm2JcwEED-1200.jpg 1200w
"
decoding="async"
loading="lazy"
/>
</picture>I ran a quick lighthouse test after I was done and using the image transform knocked my total page weight down even further! Good stuff.
Other Stuff
Permalink to “Other Stuff”I refactored some other aspects of the site as well - most importantly I switched to Vite for CSS and JS bundling. If you’re interested, you can find everything I did in this pull request.