Reading List
The most recent articles from a list of feeds I subscribe to.
Found Myself Driving
Last night I got to ride in my first driverless Cruise car (adorably named Cheddar) and I brought along my guitar.
Lyrics, for the record:
Hop into the back seat
It's time for a ride
Tonight we're Cruisin'
Yeah, let's autonomously drive
There's no one behind the wheel
But it keeps on turning
I still can't believe this thing is real
and it's continuously learning
I found myself driving in a self driving car
I found myself driving in a self driving car
I use a laser beam to find my way to you
I use a laser beam to deliver lots of food
I found myself driving in a self driving car
I found myself driving in a self driving car
I'm assuming this is the first ever song performed in a driverless car. We're making history over here at Cruise.
Other than the song, the ride was unremarkable insofar as it just felt normal, even though there was no one behind the wheel. The whole experience was a weird blend of this is amazing and this is an everyday thing, if that makes sense. I'm excited for more people to get to use Cruise soon!
My DIY Free Podcast Hosting Setup
You either die a hero or start a podcast. That's it. That's the blog post.
If you're still reading, good. Let's do this thing. Let's host a podcast for free.
Wait, some questions
Doesn't iTunes host podcasts?
Nope. They're just the most popular podcast directory. You need to host your RSS feed and audio files somewhere else on the Internet, and ideally somewhere that won't charge you a lot for bandwidth every time someone downloads one of your episodes. You also need to generate a podcast RSS feed (an XML file with specific fields) in the first place.
Well, then, what about Spotify?
Yeah, Spotify does some podcast stuff, too. I think they like podcasts because they don't have to pay royalties like they do on songs. I also remember hearing that they're actually re-hosting public podcasts on their side, which potentially had weird implications for the podcasts with those annoying "dynamic ads." They also bought Anchor, which I think also hosts podcasts for free, but maybe they "own" your podcast or something. Honestly, don't really care and it may be quite different from what I said. Let's just move on.
Shouldn't I use some managed service instead of trying to do this myself?
Yes, probably. In fact, I'd recommend Transistor.fm. I initially used them for Escaping Web before migrating the weird setup I'm about to describe. Transistor comes with great features like analytics, YouTube integration, private feeds, and more. It's a small bootstrapped team and I love their own podcast "Build Your SaaS." Lots of popular podcasts that you may already know and love use Transistor (like Indie Hackers). Shilling complete.
Enough. Get to the good stuff.
Charlie's DIY Free Podcast Hosting Setup
Here's the TLDR:
- Audio for episodes stored on archive.org
- RSS feed (and podcast website) generated by Syte (the cutest little static site generator you ever did see), and both hosted on Cloudflare Pages (or GitHub Pages, or Netlify, or... you get the picture)
That's probably enough to get you started. But, if you're up for it, I'll walkthrough creating a new podcast from scratch.
Quick note - an earlier version of this article recommended using GitHub Pages for audio hosting, but I've switched to using the free tier of archive.org based on some suggestions in the discussion of this post on Lobsters.
Host your episode audio on archive.org

Ah, now eventually you do plan to have audio on your, on your podcast, right? Hello?
Dr. Ian Malcolm's right. We do need some audio. Let's think. I've got this supremely unpopular Twitch / YouTube series called IN THE TROLL PIT where I fix interact with old Apple II computers (and hopefully soon a Commodore 64 and a Mac SE/30!). There's only two episodes so far (I'm not getting in as much Troll Pit time as I'd like to these days), but these YouTube videos should work for our podcast.
Let's use youtube-dl to download just the audio of IN THE TROLL PIT playlist into a new folder:
mkdir in-the-troll-pit-audio
cd in-the-troll-pit-audio
youtube-dl --extract-audio --audio-format mp3 -o "%(title)s.%(ext)s" https://www.youtube.com/playlist?list=PLC_pWofH2gku_gToeh1lZN8dssjcSUAft
Now, I'll rename them because I don't like spaces in my file names:
mv Apple\ IIc\ unboxing.mp3 2-apple-iic-unboxing.mp3
mv Apple\ IIe\ computer\ floppy\ drive\ setup.mp3 1-apple-iie-floppy-drive-setup.mp3
Excellent. Now we can go to archive.org, hit Upload in the upper right, and fill out the metadata for our audio files:
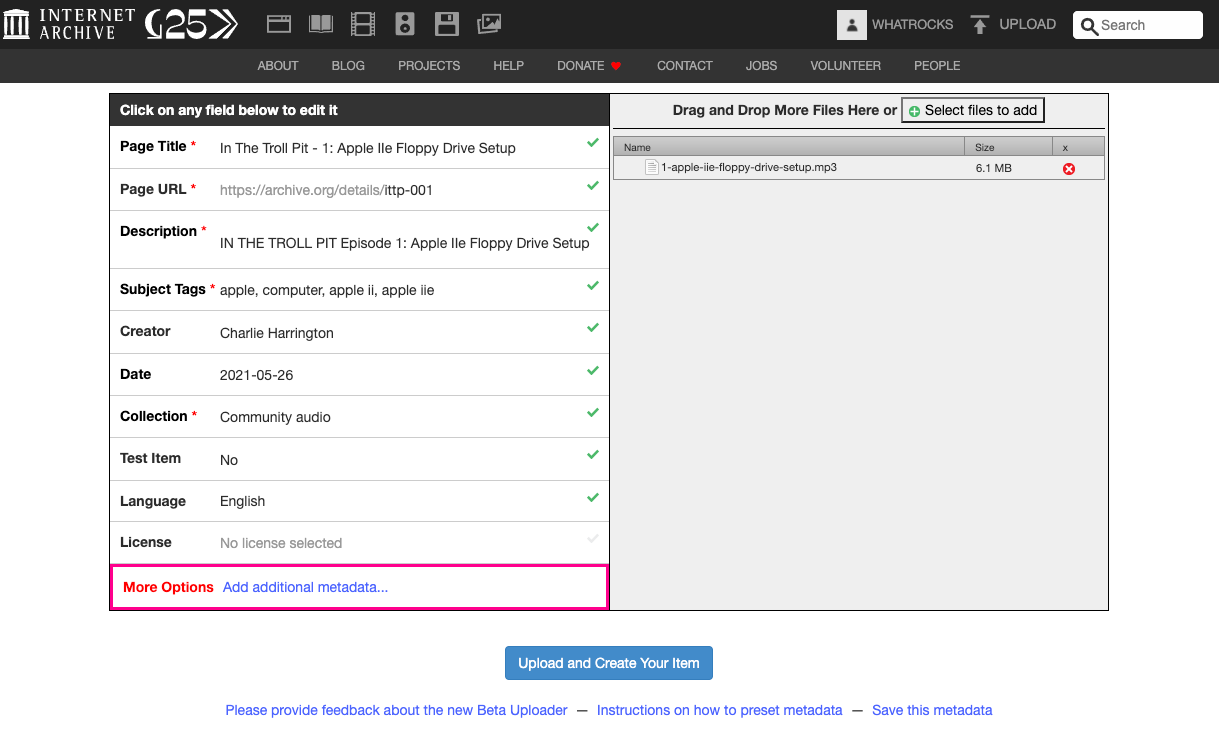
Each episode mp3 file will have its own page on Archive.org, like so:
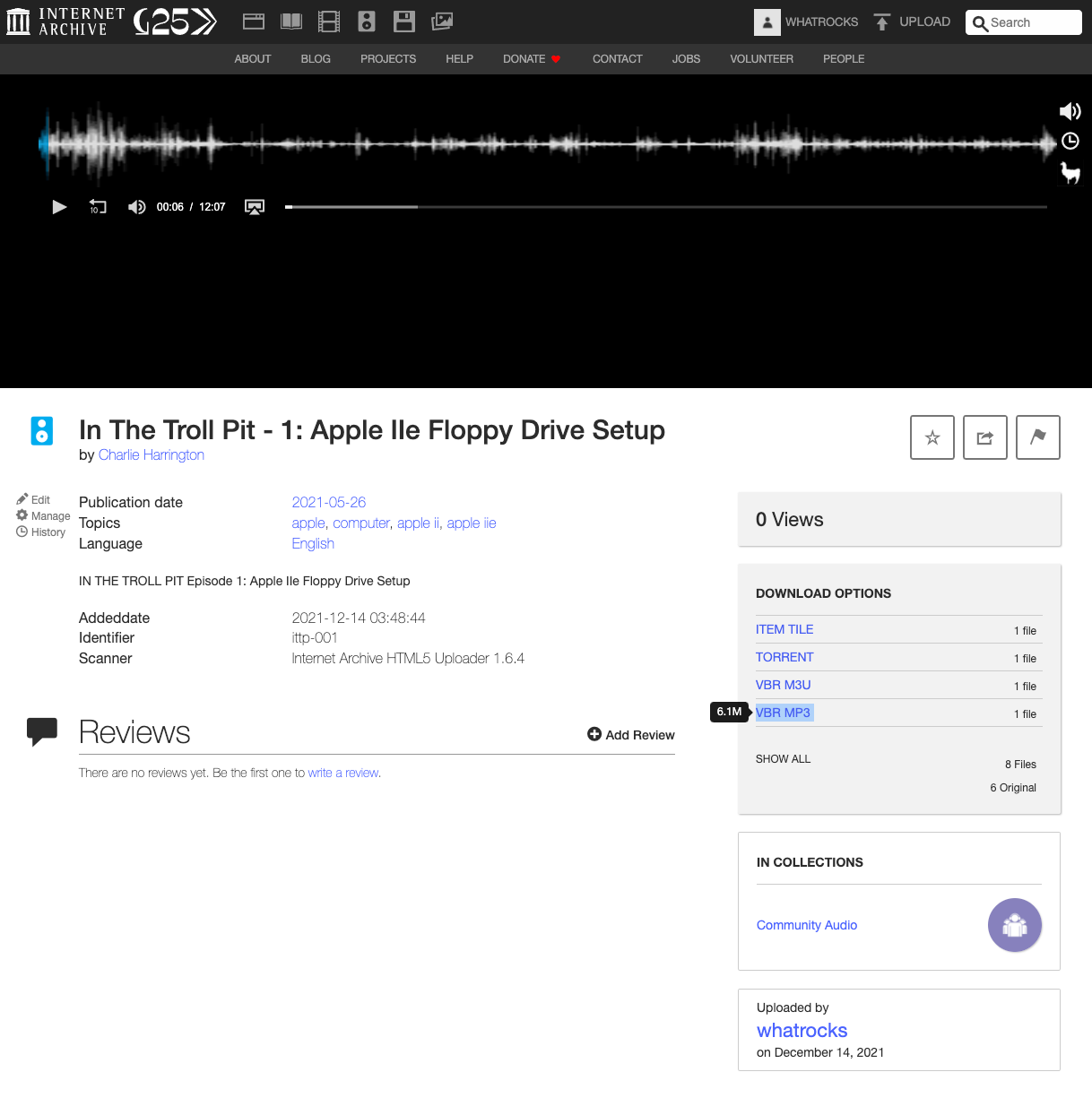
Finally, we can grab our mp3 file URL with the VBR MP3 link, which should give us a URL like this for episode 2: https://archive.org/download/ittp-002/2-apple-iic-unboxing.mp3. Paste each episode's mp3 link into a scratch file somewhere, because we'll need it later!
Generate your podcast RSS Feed and Podcast Website with Syte
Nothing special up to this point, but here's where things get fun. I've written before about my friend Ben's static site generator Syte. It's written in TypeScript and it's quite simple and easy to understand. I'm planning to migrate this here blog to Syte from Gatsby very very soon because I'm tired of my blog breaking every few weeks for some unknown node dependency reason. In the mean time, I've already used Syte for other projects, including my "writing tools" interview site Writes With (repo here).
More to the point, I've contributed two new features to Syte in the last few weeks that make this whole podcast feed thing possible:
- RSS feed generation (aka standard blog RSS feeds - example with Writes With!)
- Podcast RSS feed generation (aka exactly what you need to give the iTunes Podcast Directory to list your show)
We'll use syte to create a website for our show and add a page for each episode. The contents of the episode pages will become the episode shownotes, and the frontmatter for each page will contain metadata that our podcast feed needs.You'll see!
First, let's make a new repo on GitHub called in-the-troll-pit to host our Syte site (hehe).
Now, back on your computer terminal, navigate back to your favorite directory for projects (mainly, just make sure you are not still in the in-the-troll-pit-audio directory). Let's install syte now:
npm install -g syte@0.0.1-beta.12
Yeah, it's still in beta. I keep telling Ben it's ready for prime time. Maybe you can convince him. Anyway, now we can run the syte new <site> command to create a new project:
syte new in-the-troll-pit
cd in-the-troll-pit
Syte does hot-reloading locally, because its 2021, so let's fire it up and see where we're at.
syte serve
Head on over to localhost:3500:

Looking good. Let's first update the home page. Change your pages/index.md file to this:
Nothing's showing up in our episode list anymore (cause I filtered out the homepage), so let's add our episode pages. We'll need a Markdown file for each, and a folder to hold them:
mkdir pages/episodes
touch pages/episodes/{1..2}.md
Let's populate the page for episode 1.
---
title: '1: Apple IIe Floppy Drive Setup'
date: '2021-05-26'
episode_url: 'https://ia801500.us.archive.org/1/items/ittp-001/1-apple-iie-floppy-drive-setup.mp3'
episode_duration: ''
episode_length: ''
episode_summary: Charlie's down in The Troll Pit and he's trying to setup an Apple DuoDisk floppy drive so that he can play the branch new game Attack of the Petscii Robots.
episode_explict: 'no'
---
Charlie installs the DuoDisk floppy drive on his Apple IIe and plays Attack of the Petscii Robots!
Links and resources:
* [Apple IIe](https://en.wikipedia.org/wiki/Apple_IIe)
* [Apple DuoDisc](https://en.wikipedia.org/wiki/Disk_II#DuoDisk)
* [Attack of the Petscii Robots for Apple II](https://www.the8bitguy.com/26654/petscii-robots-for-apple-ii-now-available/)
The fields in the frontmatter are important - they are used by the podcast RSS feed generation process. iTunes needs/wants to know if your expisode is explicit or no, and so on. Take note of the episode_url field - this is the link to the mp3 we uploaded to archive.org. If you go to that link in your browser, it should just play the mp3 file. Very cool.
Also, two of the fields are blank right now - the episode duration and the expisode length. The episode duration refers to the length of your episode in seconds and the episode length refers to the size of your episode in bytes. Maybe these aren't the best names, but that's what I came up with. Let's calculate those from our mp3 file.
First, the duration in seconds:
cd ../in-the-troll-pit-audio
ffprobe -show_entries stream=duration -of compact=p=0:nk=1 -v fatal 1-apple-iie-floppy-drive-setup.mp3
727.693061
There's our duration! Now let's grab the file size in bytes:
wc -c < 1-apple-iie-floppy-drive-setup.mp3
6403740
Now we can update those fields in our frontmatter:
episode_duration: '728'
episode_length: '6403740'
Next, I'll repeat the process for episode two:
---
title: '2: Apple IIc Unboxing'
date: '2021-08-01'
episode_url: 'https://ia601509.us.archive.org/20/items/ittp-002/2-apple-iic-unboxing.mp3'
episode_duration: '2141'
episode_length: '19075912'
episode_summary: Charlie's friend Jason sent him an Apple IIc that's been sitting in Jason's childhood basement, and the two try to see if it still works.
episode_explict: 'no'
---
Charlie's friend Jason sent him an Apple IIc that's been sitting in Jason's childhood basement, and the two try to see if it still works.
Links and resources:
* [Apple IIc](https://en.wikipedia.org/wiki/Apple_IIc)
* [Where in the World Is Carmen Sandiego](https://en.wikipedia.org/wiki/Where_in_the_World_Is_Carmen_Sandiego%3F_(1985_video_game))
If you head back to localhost:3500, our episodes now show up on the homepage:
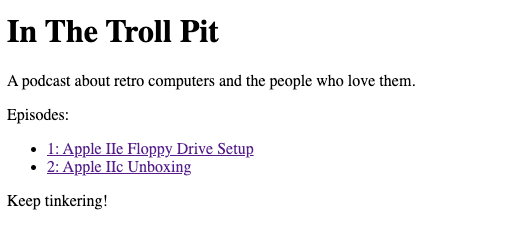
And here's what an episode page looks like.

It's terrible (terribly awesome?). I'll leave it as an exercise to the reader to update the CSS (start with the the app.css in the /static folder). But you know? It's enough for our purposes.
Just two more things to do:
- Add a few more fields to the
app.yamlfile that are needed for podcast feed generation - Create/add podcast cover art
app.yaml
This file is an overall config used by Syte, kind of like frontmatter for the whole website. Let's add some more required fields for podcast feeds.
layout: app
title: in-the-troll-pit
base_url: https://ittp.charlieharrington.com
podcast_category: Technology
podcast_language: en-us
podcast_subtitle: Old computers are the best
podcast_author: Charlie Harrington
podcast_summary: Charlie Harrington has a problem - he loves old computers. He's down in the Troll Pit and
podcast_explicit: 'no'
podcast_email: ittp@whatrocks.org
podcast_img_url: ''
Coverart
We need podcast art! According to the Apple podcast guidance, our podcast art should be 3000 by 3000.
Here's what I'm thinking. Grab a random screenshot from an episode and overlay some text on top. Probably gonna be terrible, but we can always change it later.
I've been thinking a lot about Goosebumps series lately, so that's the vibe I'm feeling for IN THE TROLL PIT logo. I found this font called Creepster on Google Fonts, downloaded it, and installed it locally (easier than you think on a Mac, just double click on the unzipped font file and click Install in the window that pops up).
Here's what I came up with: take a perfect-square screenshot of one of my episodes, add the show title text in Creepster font on top, save it to my Desktop, and then use ImageMagick to resize it:
convert screenshot.jpg -resize 3000x3000 ittp.jpg

Put this awesome file in your /static folder and then add this to app.yaml:
podcast_img_url: https://whatrocks.github.io/in-the-troll-pit/static/ittp.jpg
Let's make our podcast feed!
We're basically done now. let's test out the Syte feed generator. Try this command:
syte build
You should now see a new directory called build with your static site (all the HTML generated from the Markdown) as well as a rss.xml file (this is your site's RSS feed) and a podcast.xml (this is your podcast's RSS feed). Amazing!
All that's left now is to deploy these somewhere on the Internet. I suggest two options here:
(Option 1) Use GitHub Pages
This is the easier option. Tell syte to output to the docs directory, git init this directory, add your origin as the in-the-troll-pit repo, git add everything, commit, and push to your Github repo. Then enable Github Pages in the settings using the docs folder and you're done! You should be able to access your podcast RSS feed on the internet, and then submit that URL to iTunes.
syte build -o docs
I'm going to go with option 2 because I like trying new things.
(Option 2) Use Cloudflare Pages
We're going to set up Cloudflare Pages to deploy on changes to the main branch in this repo. Before we do that, we need to make a few more changes here because Syte is not (yet) natively supported by CloudFlare Pages (I'd love to get this added if anyone from Cloudflare is reading!).
Create a package.json file with these contents:
{
"dependencies": {
"syte": "^0.0.1-beta.12"
}
}
Then npm install, which should create a big ol' node_modules folder.
Finally, add a .gitignore with these contents:
.DS_Store
node_modules
build
Now we're ready to get this up to Github:
git init
git add .
git commit -m "just setting up my syte"
git branch -M main
git remote add origin git@github.com:whatrocks/in-the-troll-pit.git
git push -u origin main
Let's also turn on GitHub Pages for this repo so we can access our coverart. We can do that in the Settings tab and Pages section for this repo.
Set up Cloudflare Pages
Now I'm not going to do a full walkthrough of this part, because Cloudflare Pages is a rapidly changing new product. At a high-level, create a new Project with Pages, add your GitHub repo, and then configure your build. This build configuration step is important to get right, so here's what mine looks like:
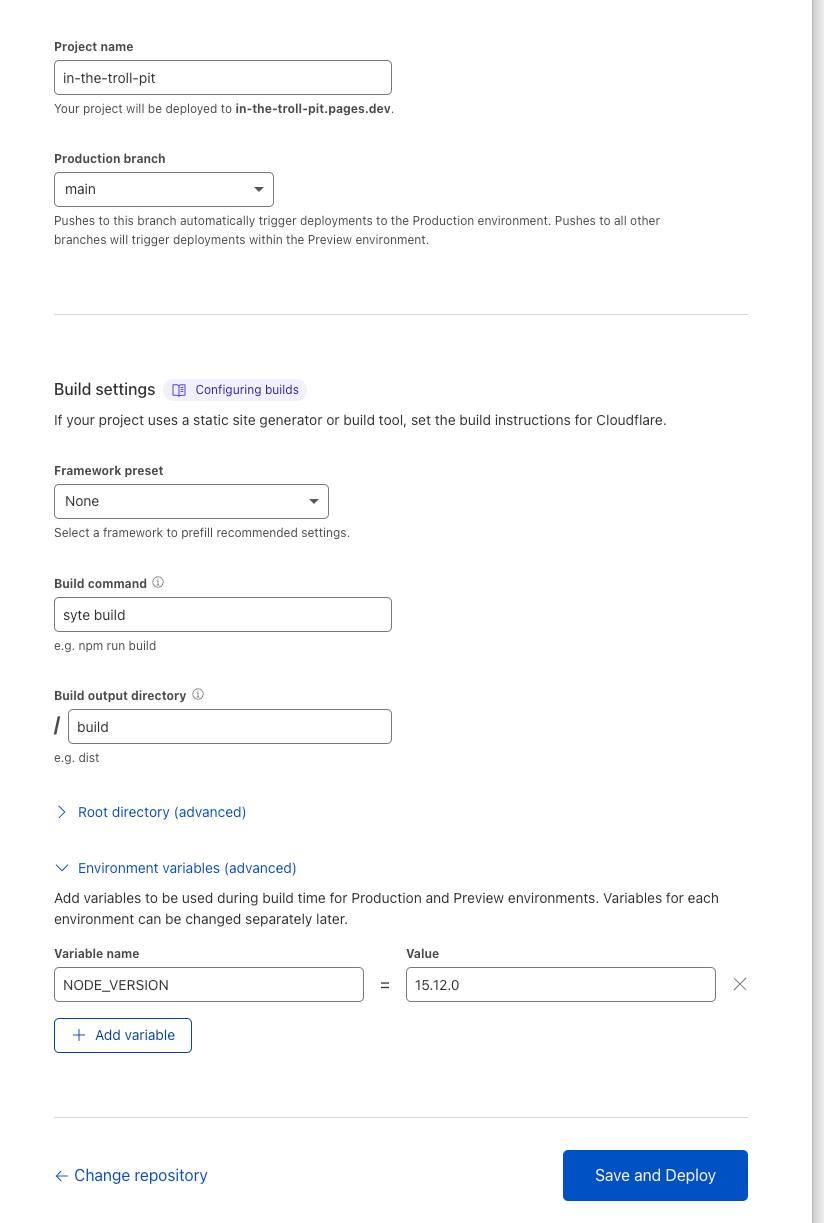
It's important to get these details in the Build Configuration:
Build command: syte buildBuild output directory: /build
Then I'd also add this environment variable:
NODE_VERSION: 15.12.0
I know this one won't age well, but I've found it helps me to stay consistent here.
Then, hit build and Cloudflare will build and deploy your site! Mine's now live here: https://in-the-troll-pit.pages.dev/ and the podcast feed is here: https://in-the-troll-pit.pages.dev/podcast.xml.
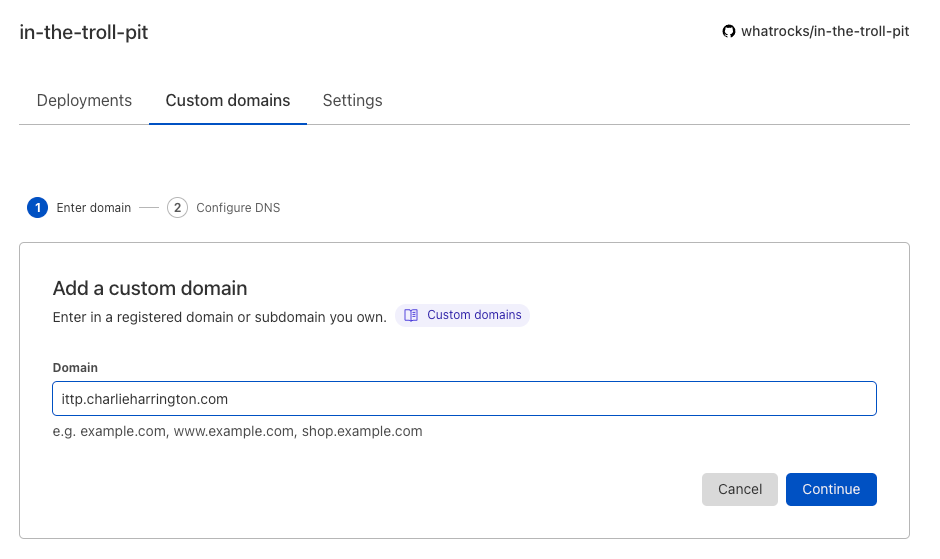
You're basically again at a nice enough place to stop and submit your podcast feed to iTunes. I'm going to go one step further and set up a subdomain on my main website for my project, which I'll also use Cloudflare to do. If you don't want to do this, then just update your app.yaml file to the new base_url provided by Cloudflare Pages:
base_url: https://in-the-troll-pit.pages.dev
But since mine is base_url: https://ittp.charlieharrington.com, I'm going to make that change now in Cloudflare, which is super easy if Cloudflare is managing your DNS - just hit the "Custom domains" tab and follow their guide. It takes a while for DNS to reflect your changes, so just wait ~2 days until the URL works correctly before you move on to the next step.
Upload your RSS feed to iTunes directory
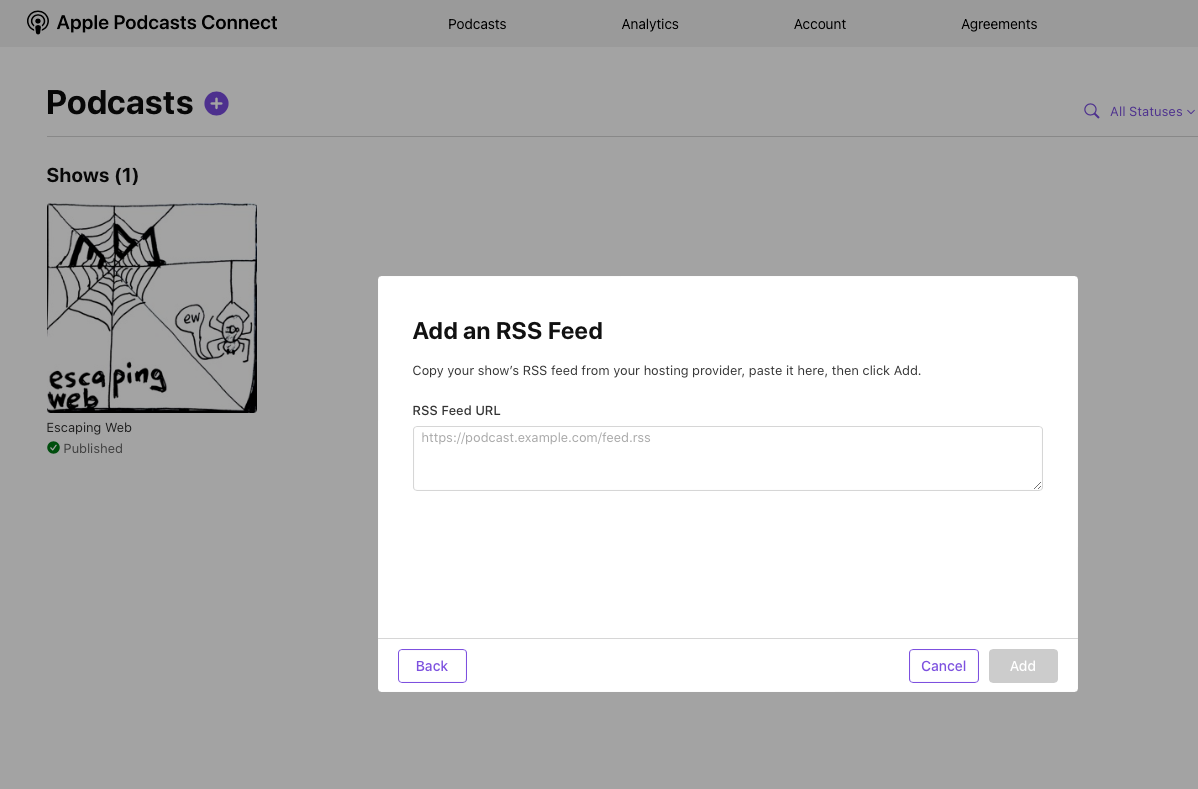
This part is less interesting to me, so I'm not going to go too deep. Go to Podcasts Connect (in Safari!) and create a new show and fill out the info with a link to your feed.
It takes a couple days for the show to appear in iTunes. Keep refreshing, though. That helps it go faster.
You can also upload your show to other directories like Google. I may need to update the Syte feed generation code to provide the required RSS metafields for these other directories, so if you run into any issues, please let me know on Twitter.
If you really can't wait for iTunes, you can usually just add a podcast RSS url manually in your player of choice (mine's Overcast). Let's give that a shot.
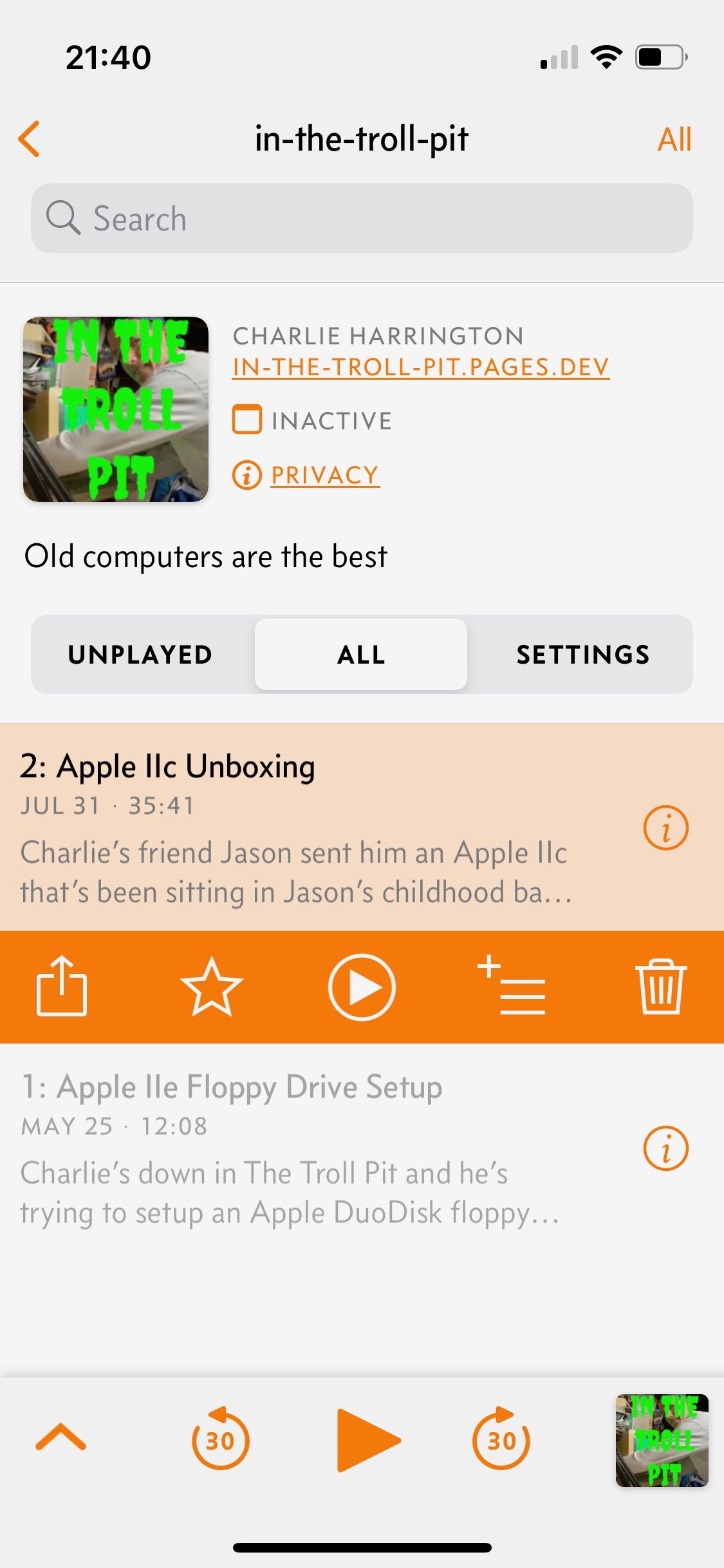
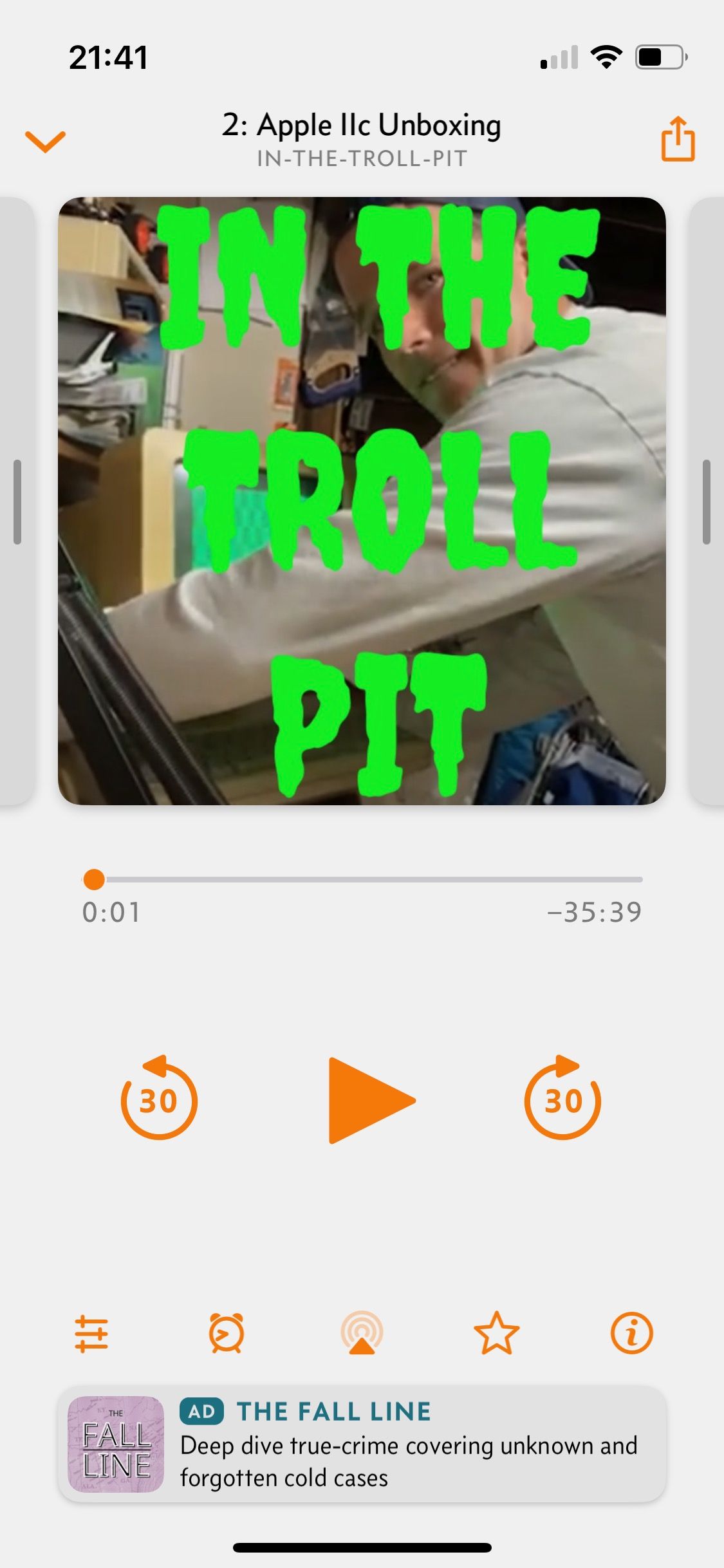
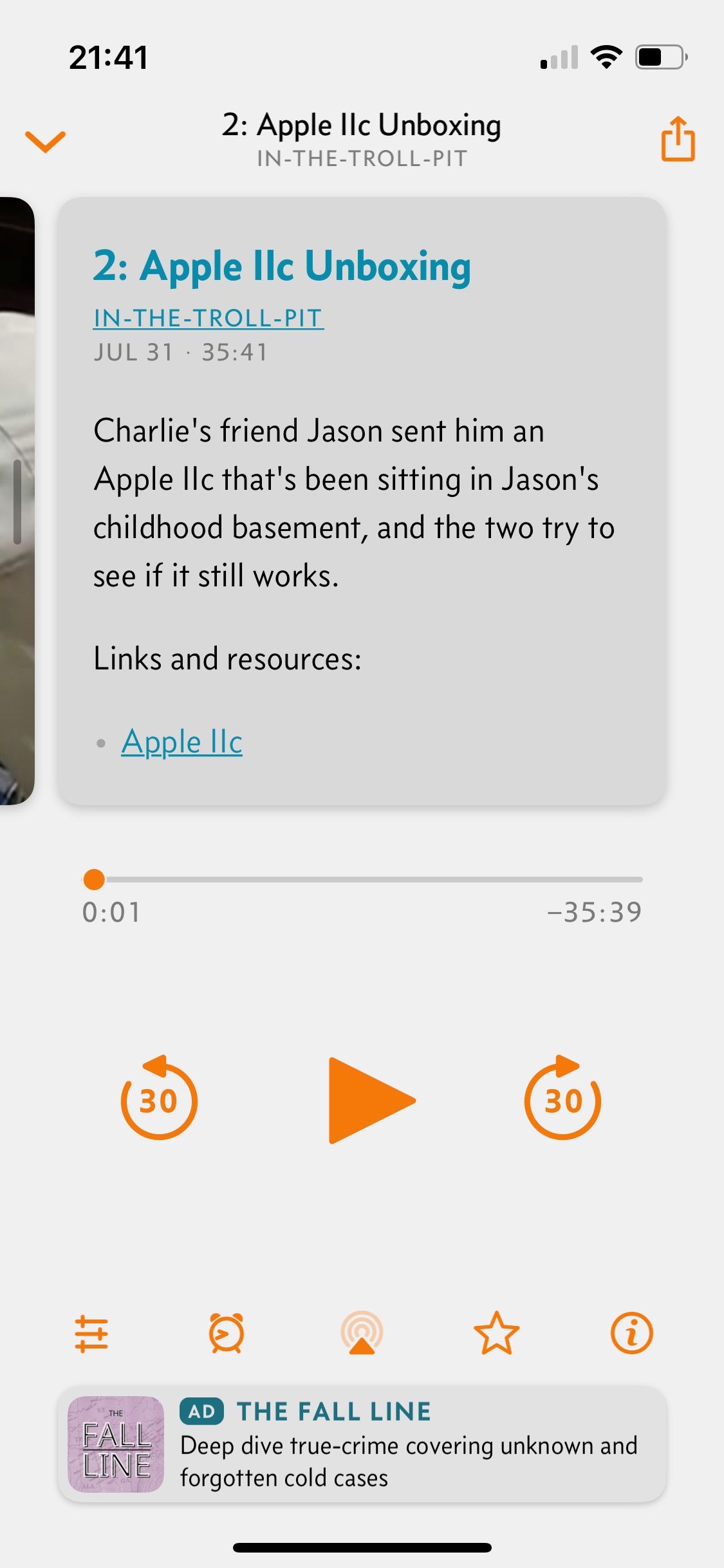
That looks awesome! The shownotes look perfect!!
We're now ready for the final step.
Reach out to Squarespace for sponsorship
Good luck with that!
My final comment is that I think this approach is well-suited for putting your podcast into maintenance mode - no new episodes coming out any time soon, but you still want to keep the old ones up, without paying any monthly fees for hosting. That's exactly what I did with Escaping Web, and I'm sure there are still a few EW-ers out there who are grateful that they can still listen to Oz's wisdom (I know I am!). And who knows, maybe we'll do season two one day :)
There's probably a bunch of things I could have done better or smarter in this article, and I'm open to learning about them if you want to reach out. For now, happy casting, villians!
Better This Christmas
Better This Christmas
I always wanted to write a Christmas song, so here you go (performed live at The Day After Thanksgiving Ping-Pong Tournament Party):
BETTER THIS CHRISTMAS
By Charlie Harrington*
So mad at myself
That elf on the shelf
Oh, if he only knew
How good I can be
As sweet as a pea
I'll even give up my blue.
I'll be better this Christmas
I'll be better this Christmas
I'll be better this Christmas
But it better be Christmas soon
Bet ya heard I didn't listen
Messed up the kitchen
Smudged a window or two.
Just a misunderstandin'
Cause life's pretty demandin'
When you're three-foot-two
I'll be better this Christmas
I'll be better this Christmas
I'll be better this Christmas
But it better be Christmas soon
Wrote you that letter
Said I'd be better
Nothing else I can do.
Cause the clock is a-tickin'
Santa, we're playin' chicken
what are you gonna do
I'll be better this Christmas
I'll be better this Christmas
I'll be better this Christmas
But it better be Christmas soon
Now I'm closing my eyes
Hoping you'll still arrive
I left milk and cookies for you
Now I don't need a thing
But if you happen to bring
Just leave a toy or two
I'll be better this Christmas
I'll be better this Christmas
I'll be better this Christmas
But it better be Christmas soon
But it better be Christmas soon
But it better be Christmas soon!
Lots of asterisks
I listened to a recent Decoder podcast episode about how artists are just giving out songwriting credits readily, rather than face copyright issues, which explains why Olivia Rodrigo gave out credits to T. Swift and Paramore long after her album dropped. Anyway, here's who helped out with BETTER THIS CHRISTMAS:
- Story inspired by my nephew Monte
- Lyrics help from Carly, Molly, Andy, Mom during the Thanksgiving dessert doldrums
- Melody and fa-la-la-la help from Carly during our morning runs
- Musical advice text messages from Michael Byrnes throughout the week
- Performance credits to Michael Byrnes, Peter Clabby, Mikey's dad, Kevin, Patrick Clarke, and the whole Clabby-Byrnes-Harrington clan on fa-la-la-la's.
Happy Advent of Code, everyone!
Magazine Dopamine
As a recent subscriber to Stripe's Increment magazine, I was bummed to learn that "the final quarterly issue of Increment [was] published in November 2021." I'm sure the imprint will live on in some fashion, but, for a short moment, I enjoyed reading its well-edited, super-colorful, overall-nice-feeling dead-tree book-thing about a topic I enjoy in the meatspace.
Which got me a-thinking... what happened to the other magazines I loved as a kid, and where are they now, and can I still get them in the mail? Cause, guess what? Getting something you actually want in the mail is still fun.
So, let's find out!
Oriental Trading
Gotta start off with a banger. I'm shocked that this magazine/company still (or ever) exists. Also, I concede it's technically not a magazine. But, still, I loved crushing this thing as a kid, ogling its weird eyeball candies and probably-inappropriate holiday-themed bubble-sets, pencil sharpeners, and bouncy balls. On that note, if you were ever planning to release 10,000 bouncy balls in your high school hallway on senior prank day, Oriental Trading is how you'd do it. Request a free catalog here. Yes, you'll probably be spammed for life. But you already were, and now you can buy lots of cool plastic stuff (that the state of the California also must remind you, on nearly every single listing, is probably also poisoning you in some terrifying way).
Weird NJ
Speaking on terrifying, I'm happy to report NJ's favorite insane asylum explorers are alive and well! They're down to two issues a year, but they're just as creepy and fun as ever. Sign up for an annual subscription here, in case your local Welsh Farms stopped carrying them.

Nintendo Power
Now we're getting into the good stuff. Nintendo Power was far-and-away the most important magazine of them all to kid-Charlie. When my parents finally agreed to get me a regular Nintendo, we did so in the most Harrington-way possible: at a garage sale, where the guy threw in a bunch of other goodies, including the Power Mat and 20-odd ragged Nintendo Power issues. I read every one roughly ten-billion times before I was finally allowed to subscribe to new issues.
Then, on some horrible, woebegone day 15-odd years ago, I purged their cardboard box home in my parent's attic and only kept three issues (thankfully, I kept the Link to the Past strategy guide, I'm not a complete monster). But I'm still kicking myself every time I think about it.
That was a whole lot of backstory to say that you can't subscribe to Nintendo Power anymore.. in magazine format. But they do have a monthly podcast! And it's kinda fun! Apparently the new president of Nintendo's last name is Bowser and that's an actual, honest-to-goodness coincidence. The spirit of Howard and Nester lives on.
Also, if you really, really do want to get your NP nostalgia on, I suggest checking out retromags.com. Even YouTube doesn't have all the Mega Man X2 level-by-level walkthroughs you might need in a pinch.
CCS
Another not-quite-magazine that I treasured. Many hours were spent daydreaming over which skateboard deck and shoes I wanted to buy instead of actually going outside and practicing skateboarding.

These babies used to arrive 14 times a year, but you can still get them 2x a year by signing up here and I do and I'm still trying to pick the perfect deck rather than work on my heel-flip.
Klutz Press
AFAIK, sending this card in the mail will not result in the Flying Apparatus Catalog by Klutz Press arriving in your mailbox.

But I've just filled it out and I'll update this post if things turn out AWESOME. In the mean time, you can read all about my love of Klutz in this open love-letter, and just scour eBay and Amazon for their used books!
A future golden age
Can magazines work in 2021? Probably not. They probably haven't been working for a long-long time. But who knows? Maybe we'll be flipping through their semi-fungible representations in the Facebook-verse. For now, let's just enjoy the decline and fall while we still can.
Now, zines, on the other hand, are in full-on revival-mode. Just check out wizardzines and you'll be a believer (and you can even print these out at home!)
Actually, that's my final exhortation in this post - get a printer, cause they're awesome. Everyone thinks they suck, and they don't. They're great. In fact, this is my new answer to the What's one important truth do very few people agree with you on? question. Here's the printer I bought and love. Think about it. You can print things out! In your own house, without going anywhere else! Make a zine and print it out. Draw a maze, or a weird coloring shape, and print it out. Make Gutenberg proud.
Mario Paint Masterpiece
Since having a child, I've been on a nostalgia Mega Drive. If you know anything about me, then you'll probably agree I was already at alarming levels of the stuff, and I've now likely reached the nostalgia mesosphere, even if just for a minute or so.
In particular, videos games are dominating my reminiscences. I've been thinking about their role in my development as a human. Spoiler alert: it's an extremely positive one.
There's one game that stands out: Mario Paint.
This 1992 "edutainment" title (a word seemingly devised to revile kids) is a forgotten masterpiece of creativity, fun, and weirdness.
At the surface, its existence doesn't make a whole lot of sense. It's a digital art and music app on the Super Nintendo that uses (comes with!) a separate mouse controller. I can name exactly one video game like this, ever.
From what I've learned in my limited YouTube research, although the Super Nintendo was always the more-parentally-acceptable console of the early 90s console wars (see Mortal Kombat SNES grey matter vs Sega Genesis blood), Nintendo was feeling the pressure to demonstrate that their "family computers" were actually forces for good in the battle for the attention span of the world's youth.
And, thus, Mario Paint.

There's just no reason for this game to be this good. Sure, MS Paint on Windows was always a fun time-waster back in the day. But it certaintly wasn't weird. And Mario Paint is w-e-i-r-d. It's like Photoshop on Magic Mushrooms. Plus an animation studio. Plus a digital audio workstation (aka Garageband). And all this back when we were still recording our favorite songs from the radio on cassette tapes (if we were lucky enough to catch them, and even then usually missing the first few bars).
Don't talk to me about delightful UIs or UXs if you haven't played Mario Paint. Nothing makes sense at a glance. Instead, it's pure discovery. Click-and-see. The undo button is a dog's face. Why? Why not. The fill-paint animation is a break-dancing paint-brush with a smiley-face (that sentence had a lot of hyphens). I spent hours and hours clicking every button in Mario Paint, and just making weird shit.
Now, don't get me wrong, it's not like I exclusively played Mario Paint from 1992 forward (I probably didn't get it until 1993 or 1994 anyway). But I'd find myself drawn back to Mario Paint way more often than my parents even expected.
Thinking about it now, Mario Paint reminds me of that poster of kindergarten classroom yore:
Everything I need to know in life I learned in Mario Paint.
Why do I like making weird songs on Garageband? Mario Paint
Why do I like making logos for bands and apps and companies? Mario Paint.
Why am I a software engineer? Mario Paint.
But, Charlie, there's no "game engine" or programming environment in Mario Paint. What-so-ever do you mean?
Thought you'd never ask. In 2015, I was living in London working in business development for an edtech startup, traveling a whole lot, with a bunch of downtime in airports. I decided to Carpe Diem the idle-airport-time to teach myself programming (something I'd been trying to do, on and off, for the previous seven years), so I bought a Big Nerd Ranch iPhone book. When my company planned a two-day hackathon, I pledged to build a little iPhone app, following the book step-by-step. I've written about this experience before, so I won't fully rehash it. But the key thing is that, in addition to the basic Tinder/flash-card UX, I decided to add some fun little characters for the app (designed by my co-worker and pal Dan McGorry). Then, these characters obviously needed a backstory. A week or so later, I traveled back to New Jersey for my aunt's wedding and I was showing the app to anyone who would listen (not many). Except for my 9 year old cousin. She bit hard. She came up with even more ideas for their powers (hair that grows to become a bridge, melting down into a popsicle liquid so you can glide, and so on). The kicker: the next day, my aunt delivered to me some enemies for the game that my cousin had drawn, like Chill Factor:

I knew then and there that I wanted to create wonderful things, be good, and have fun for my career. I quit my job and studied to become a computer programmer.
Now, years in, am I creating wonderful things ever day? Not necessarily. But I try to keep the joy and weirdness alive in whatever I do.
Last week, I asked my mom to dig through my boxes in the attic to find my Super Nintendo Mouse. She graciously delivered. Even the intro screen screen to Mario Paint is a lesson in weirdness. I love-love-love it:
After about a half hour or so, I produced this masterpiece:
Yes, the main riff is more-or-less China Cat Sunflower by the Grateful Dead (I think).
I'm not the only one who loves Mario Paint, particularly the music-maker. There's a whole Internet of magic Mario Paint music like this, the entire back-side of Abbey Road (including secret track Your Majesty!):
I can't believe that this game exists (and still works!). I guess edutainment ain't so bad after all. For now, back to the drawing board!