Reading List
The most recent articles from a list of feeds I subscribe to.
Mounting git commits as folders with NFS
Hello! The other day, I started wondering – has anyone ever made a FUSE filesystem for a git repository where all every commit is a folder? It turns out the answer is yes! There’s giblefs, GitMounter, and git9 for Plan 9.
But FUSE is pretty annoying to use on Mac – you need to install a kernel extension, and Mac OS seems to be making it harder and harder to install kernel extensions for security reasons. Also I had a few ideas for how to organize the filesystem differently than those projects.
So I thought it would be fun to experiment with ways to mount filesystems on Mac OS other than FUSE, so I built a project that does that called git-commit-folders. It works (at least on my computer) with both FUSE and NFS, and there’s a broken WebDav implementation too.
It’s pretty experimental (I’m not sure if this is actually a useful piece of software to have or just a fun toy to think about how git works) but it was fun to write and I’ve enjoyed using it myself on small repositories so here are some of the problems I ran into while writing it.
goal: show how commits are like folders
The main reason I wanted to make this was to give folks some intuition for how git works under the hood. After all, git commits really are very similar to folders – every Git commit contains a directory listing of the files in it, and that directory can have subdirectories, etc.
It’s just that git commits aren’t actually implemented as folders to save disk space.
So in git-commit-folders, every commit is actually a folder, and if you want
to explore your old commits, you can do it just by exploring the filesystem!
For example, if I look at the initial commit for my blog, it looks like this:
$ ls commits/8d/8dc0/8dc0cb0b4b0de3c6f40674198cb2bd44aeee9b86/
README
and a few commits later, it looks like this:
$ ls /tmp/git-homepage/commits/c9/c94e/c94e6f531d02e658d96a3b6255bbf424367765e9/
_config.yml config.rb Rakefile rubypants.rb source
branches are symlinks
In the filesystem mounted by git-commit-folders, commits are the only real folders – everything
else (branches, tags, etc) is a symlink to a commit. This mirrors how git works under the hood.
$ ls -l branches/
lr-xr-xr-x 59 bork bazil-fuse -> ../commits/ff/ff56/ff563b089f9d952cd21ac4d68d8f13c94183dcd8
lr-xr-xr-x 59 bork follow-symlink -> ../commits/7f/7f73/7f73779a8ff79a2a1e21553c6c9cd5d195f33030
lr-xr-xr-x 59 bork go-mod-branch -> ../commits/91/912d/912da3150d9cfa74523b42fae028bbb320b6804f
lr-xr-xr-x 59 bork mac-version -> ../commits/30/3008/30082dcd702b59435f71969cf453828f60753e67
lr-xr-xr-x 59 bork mac-version-debugging -> ../commits/18/18c0/18c0db074ec9b70cb7a28ad9d3f9850082129ce0
lr-xr-xr-x 59 bork main -> ../commits/04/043e/043e90debbeb0fc6b4e28cf8776e874aa5b6e673
$ ls -l tags/
lr-xr-xr-x - bork 31 Dec 1969 test-tag -> ../commits/16/16a3/16a3d776dc163aa8286fb89fde51183ed90c71d0
This definitely doesn’t completely explain how git works (there’s a lot more to it than just “a commit is like a folder!”), but my hope is that it makes thie idea that every commit is like a folder with an old version of your code” feel a little more concrete.
why might this be useful?
Before I get into the implementation, I want to talk about why having a filesystem with a folder for every git commit in it might be useful. A lot of my projects I end up never really using at all (like dnspeep) but I did find myself using this project a little bit while I was working on it.
The main uses I’ve found so far are:
- searching for a function I deleted – I can run
grep someFunction branch_histories/main/*/commit.goto find an old version of it - quickly looking at a file on another branch to copy a line from it, like
vim branches/other-branch/go.mod - searching every branch for a function, like
grep someFunction branches/*/commit.go
All of these are through symlinks to commits instead of referencing commits directly.
None of these are the most efficient way to do this (you can use git show and
git log -S or maybe git grep to accomplish something similar), but
personally I always forget the syntax and navigating a filesystem feels easier
to me. git worktree also lets you have multiple branches checked out at the same
time, but to me it feels weird to set up an entire worktree just to look at 1
file.
Next I want to talk about some problems I ran into.
problem 1: webdav or NFS?
The two filesystems I could that were natively supported by Mac OS were WebDav and NFS. I couldn’t tell which would be easier to implement so I just tried both.
At first webdav seemed easier and it turns out that golang.org/x/net has a webdav implementation, which was pretty easy to set up.
But that implementation doesn’t support symlinks, I think because it uses the io/fs interface
and io/fs doesn’t support symlinks yet. Looks like that’s in progress
though. So I gave up on webdav and decided to focus on the NFS implementation, using this go-nfs NFSv3 library.
Someone also mentioned that there’s FileProvider on Mac but I didn’t look into that.
problem 2: how to keep all the implementations in sync?
I was implementing 3 different filesystems (FUSE, NFS, and WebDav), and it wasn’t clear to me how to avoid a lot of duplicated code.
My friend Dave suggested writing one core implementation and then writing
adapters (like fuse2nfs and fuse2dav) to translate it into the NFS and
WebDav verions. What this looked like in practice is that I needed to implement
3 filesystem interfaces:
fs.FSfor FUSEbilly.Filesystemfor NFSwebdav.Filesystemfor webdav
So I put all the core logic in the fs.FS interface, and then wrote two functions:
func Fuse2Dav(fs fs.FS) webdav.FileSystemfunc Fuse2NFS(fs fs.FS) billy.Filesystem
All of the filesystems were kind of similar so the translation wasn’t too hard, there were just 1 million annoying bugs to fix.
problem 3: I didn’t want to list every commit
Some git repositories have thousands or millions of commits. My first idea for how to address this was to make commits/ appear empty, so that it works like this:
$ ls commits/
$ ls commits/80210c25a86f75440110e4bc280e388b2c098fbd/
fuse fuse2nfs go.mod go.sum main.go README.md
So every commit would be available if you reference it directly, but you can’t list them. This is a weird thing for a filesystem to do but it actually works fine in FUSE. I couldn’t get it to work in NFS though. I assume what’s going on here is that if you tell NFS that a directory is empty, it’ll interpret that the directory is actually empty, which is fair.
I ended up handling this by:
- organizing the commits by their 2-character prefix the way
.git/objectsdoes (so thatls commitsshows0b 03 05 06 07 09 1b 1e 3e 4a), but doing 2 levels of this so that a18d46e76d7c2eedd8577fae67e3f1d4db25018b0is atcommits/18/18df/18d46e76d7c2eedd8577fae67e3f1d4db25018b0 - listing all the packed commits hashes only once at the beginning, caching them in memory, and then only updating the loose objects afterwards. The idea is that almost all of the commits in the repo should be packed and git doesn’t repack its commits very often.
This seems to work okay on the Linux kernel which has ~1 million commits. It takes maybe a minute to do the initial load on my machine and then after that it just needs to do fast incremental updates.
Each commit hash is only 20 bytes so caching 1 million commit hashes isn’t a big deal, it’s just 20MB.
I think a smarter way to do this would be to load the commit listings lazily –
Git sorts its packfiles by commit ID, so you can pretty easily do a binary
search to find all commits starting with 1b or 1b8c. The git library I was using
doesn’t have great support for this though, because listing all commits in a
Git repository is a really weird thing to do. I spent maybe a couple of days
trying to implement it but I didn’t manage to get the performance I wanted so I
gave up.
problem 4: “not a directory”
I kept getting this error:
"/tmp/mnt2/commits/59/59167d7d09fd7a1d64aa1d5be73bc484f6621894/": Not a directory (os error 20)
This really threw me off at first but it turns out that this just means that there was an error while listing the directory, and the way the NFS library handles that error is with “Not a directory”. This happened a bunch of times and I just needed to track the bug down every time.
There were a lot of weird errors like this. I also got cd: system call
interrupted which was pretty upsetting but ultimately was just some other bug
in my program.
Eventually I realized that I could use Wireshark to look at all the NFS packets being sent back and forth, which made some of this stuff easier to debug.
problem 5: inode numbers
At first I was accidentally setting all my directory inode numbers to 0. This
was bad because if if you run find on a directory where the inode number of
every directory is 0, it’ll complain about filesystem loops and give up, which
is very fair.
I fixed this by defining an inode(string) function which hashed a string to
get the inode number, and using the tree ID / blob ID as the string to hash.
problem 6: stale file handles
I kept getting this “Stale NFS file handle” error. The problem is that I need to be able to take an opaque 64-byte NFS “file handle” and map it to the right directory.
The way the NFS library I’m using works is that it generates a file handle for every file and caches those references with a fixed size cache. This works fine for small repositories, but if there are too many files then it’ll overflow the cache and you’ll start getting stale file handle errors.
This is still a problem and I’m not sure how to fix it. I don’t understand how real NFS servers do this, maybe they just have a really big cache?
The NFS file handle is 64 bytes (64 bytes! not bits!) which is pretty big, so it does seem like you could just encode the entire file path in the handle a lot of the time and not cache it at all. Maybe I’ll try to implement that at some point.
problem 7: branch histories
The branch_histories/ directory only lists the latest 100 commits for each
branch right now. Not sure what the right move is there – it would be nice to
be able to list the full history of the branch somehow. Maybe I could use a
similar subfolder trick to the commits/ directory.
problem 8: submodules
Git repositories sometimes have submodules. I don’t understand anything about submodules so right now I’m just ignoring them. So that’s a bug.
problem 9: is NFSv4 better?
I built this with NFSv3 because the only Go library I could find at the time was an NFSv3 library. After I was done I discovered that the buildbarn project has an NFSv4 server in it. Would it be better to use that?
I don’t know if this is actually a problem or how big of an advantage it would be to use NFSv4. I’m also a little unsure about using the buildbarn NFS library because it’s not clear if they expect other people to use it or not.
that’s all!
There are probably more problems I forgot but that’s all I can think of for now. I may or may not fix the NFS stale file handle problem or the “it takes 1 minute to start up on the linux kernel” problem, who knows!
Thanks to my friend vasi who explained one million things about filesystems to me.
git branches: intuition & reality
Hello! I’ve been working on writing a zine about git so I’ve been thinking about git branches a lot. I keep hearing from people that they find the way git branches work to be counterintuitive. It got me thinking: what might an “intuitive” notion of a branch be, and how is it different from how git actually works?
So in this post I want to briefly talk about
- an intuitive mental model I think many people have
- how git actually represents branches internally (“branches are a pointer to a commit” etc)
- how the “intuitive model” and the real way it works are actually pretty closely related
- some limits of the intuitive model and why it might cause problems
Nothing in this post is remotely groundbreaking so I’m going to try to keep it pretty short.
an intuitive model of a branch
Of course, people have many different intuitions about branches. Here’s the one that I think corresponds most closely to the physical “a branch of an apple tree” metaphor.
My guess is that a lot of people think about a git branch like this: the 2 commits in pink in this picture are on a “branch”.
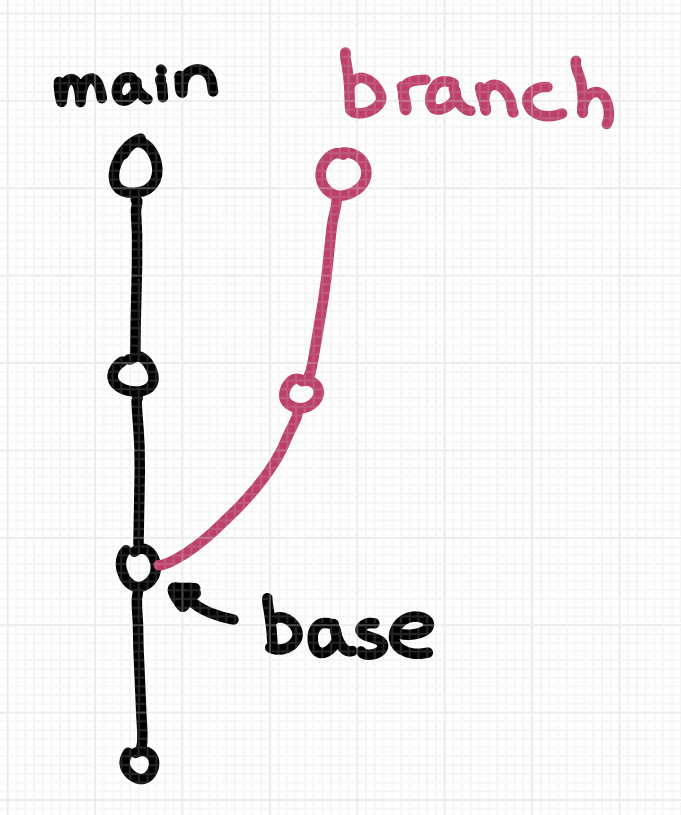
I think there are two important things about this diagram:
- the branch has 2 commits on it
- the branch has a “parent” (
main) which it’s an offshoot of
That seems pretty reasonable, but that’s not how git defines a branch – most importantly, git doesn’t have any concept of a branch’s “parent”. So how does git define a branch?
in git, a branch is the full history
In git, a branch is the full history of every previous commit, not just the “offshoot” commits. So in our picture above both branches (main and branch) have 4 commits on them.
I made an example repository at https://github.com/jvns/branch-example which has its branches set up the same way as in the picture above. Let’s look at the 2 branches:
main has 4 commits on it:
$ git log --oneline main
70f727a d
f654888 c
3997a46 b
a74606f a
and mybranch has 4 commits on it too. The bottom two commits are shared
between both branches.
$ git log --oneline mybranch
13cb960 y
9554dab x
3997a46 b
a74606f a
So mybranch has 4 commits on it, not just the 2 commits 13cb960 and 9554dab that are “offshoot” commits.
You can get git to draw all the commits on both branches like this:
$ git log --all --oneline --graph
* 70f727a (HEAD -> main, origin/main) d
* f654888 c
| * 13cb960 (origin/mybranch, mybranch) y
| * 9554dab x
|/
* 3997a46 b
* a74606f a
a branch is stored as a commit ID
Internally in git, branches are stored as tiny text files which have a commit ID in them. That commit is the latest commit on the branch. This is the “technically correct” definition I was talking about at the beginning.
Let’s look at the text files for main and mybranch in our example repo:
$ cat .git/refs/heads/main
70f727acbe9ea3e3ed3092605721d2eda8ebb3f4
$ cat .git/refs/heads/mybranch
13cb960ad86c78bfa2a85de21cd54818105692bc
This makes sense: 70f727 is the latest commit on main and 13cb96 is the latest commit on mybranch.
The reason this works is that every commit contains a pointer to its parent(s), so git can follow the chain of pointers to get every commit on the branch.
Like I mentioned before, the thing that’s missing here is any relationship at
all between these two branches. There’s no indication that mybranch is an
offshoot of main.
Now that we’ve talked about how the intuitive notion of a branch is “wrong”, I want to talk about how it’s also right in some very important ways.
people’s intuition is usually not that wrong
I think it’s pretty popular to tell people that their intuition about git is “wrong”. I find that kind of silly – in general, even if people’s intuition about a topic is technically incorrect in some ways, people usually have the intuition they do for very legitimate reasons! “Wrong” models can be super useful.
So let’s talk about 3 ways the intuitive “offshoot” notion of a branch matches up very closely with how we actually use git in practice.
rebases use the “intuitive” notion of a branch
Now let’s go back to our original picture.
When you rebase mybranch on main, it takes the commits on the “intuitive”
branch (just the 2 pink commits) and replays them onto main.
The result is that just the 2 (x and y) get copied. Here’s what that looks like:
$ git switch mybranch
$ git rebase main
$ git log --oneline mybranch
952fa64 (HEAD -> mybranch) y
7d50681 x
70f727a (origin/main, main) d
f654888 c
3997a46 b
a74606f a
Here git rebase has created two new commits (952fa64 and 7d50681) whose
information comes from the previous two x and y commits.
So the intuitive model isn’t THAT wrong! It tells you exactly what happens in a rebase.
But because git doesn’t know that mybranch is an offshoot of main, you need
to tell it explicitly where to rebase the branch.
merges use the “intuitive” notion of a branch too
Merges don’t copy commits, but they do need a “base” commit: the way merges work is that it looks at two sets of changes (starting from the shared base) and then merges them.
Let’s undo the rebase we just did and then see what the merge base is.
$ git switch mybranch
$ git reset --hard 13cb960 # undo the rebase
$ git merge-base main mybranch
3997a466c50d2618f10d435d36ef12d5c6f62f57
This gives us the “base” commit where our branch branched off, 3997a4.
That’s exactly the commit you would think it might be based on our intuitive
picture.
github pull requests also use the intuitive idea
If we create a pull request on GitHub to merge mybranch into main, it’ll
also show us 2 commits: the commits x and y. That makes sense and also
matches our intuitive notion of a branch.
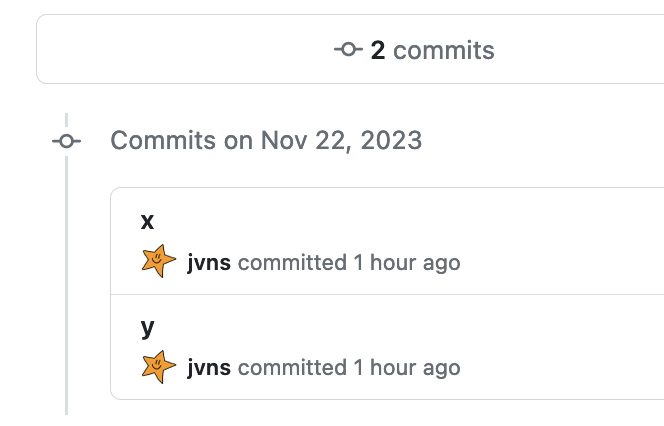
I assume if you make a merge request on GitLab it shows you something similar.
intuition is pretty good, but it has some limits
This leaves our intuitive definition of a branch looking pretty good actually! The “intuitive” idea of what a branch is matches exactly with how merges and rebases and GitHub pull requests work.
You do need to explicitly
specify the other branch when merging or rebasing or making a pull request (like git rebase main),
because git doesn’t know what branch you think your offshoot is based on.
But the intuitive notion of a branch has one fairly serious problem: the way
you intuitively think about main and an offshoot branch are very different,
and git doesn’t know that.
So let’s talk about the different kinds of git branches.
trunk and offshoot branches
To a human, main and mybranch are pretty different, and you probably have
pretty different intentions around how you want to use them.
I think it’s pretty normal to think of some branches as being “trunk” branches, and some branches as being “offshoots”. Also you can have an offshoot of an offshoot.
Of course, git itself doesn’t make any such distinctions (the term “offshoot” is one I just made up!), but what kind of a branch it is definitely affects how you treat it.
For example:
- you might rebase
mybranchontomainbut you probably wouldn’t rebasemainontomybranch– that would be weird! - in general people are much more careful around rewriting the history on “trunk” branches than short-lived offshoot branches
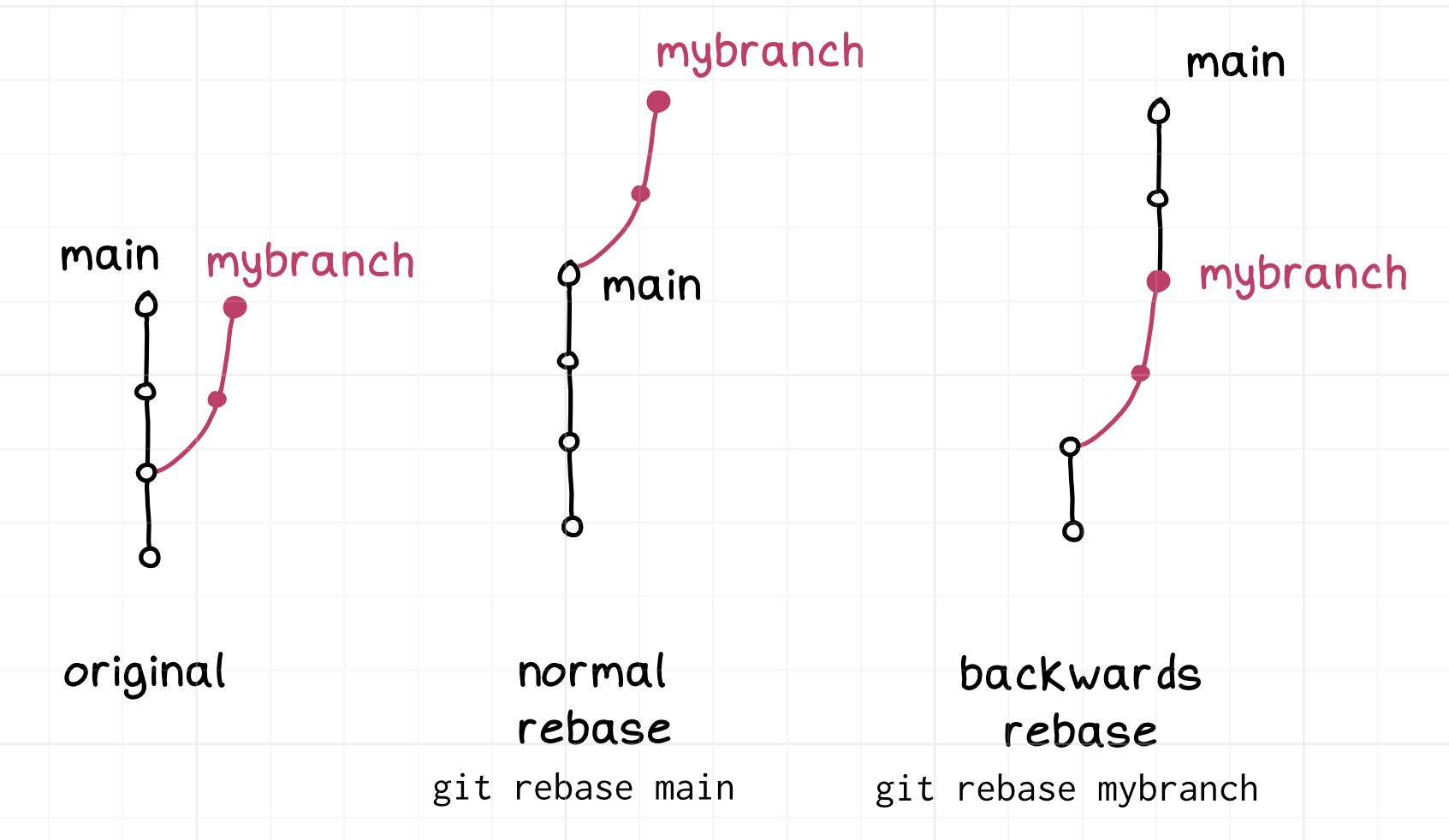
git lets you do rebases “backwards”
One thing I think throws people off about git is – because git doesn’t have any notion of whether a branch is an “offshoot” of another branch, it won’t give you any guidance about if/when it’s appropriate to rebase branch X on branch Y. You just have to know.
for example, you can do either:
$ git checkout main
$ git rebase mybranch
or
$ git checkout mybranch
$ git rebase main
Git will happily let you do either one, even though in this case git rebase main is
extremely normal and git rebase mybranch is pretty weird. A lot of people
said they found this confusing so here’s a picture of the two kinds of rebases:
Similarly, you can do merges “backwards”, though that’s much more normal than
doing a backwards rebase – merging mybranch into main and main into
mybranch are both useful things to do for different reasons.
Here’s a diagram of the two ways you can merge:
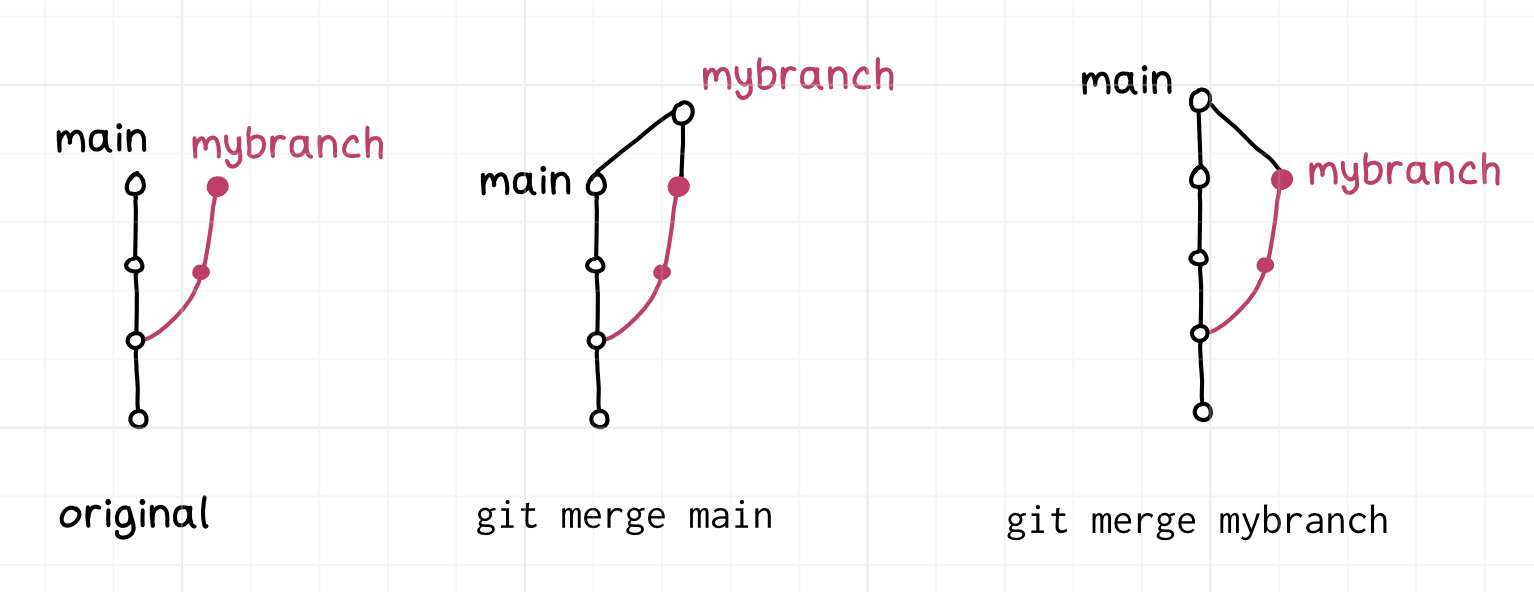
git’s lack of hierarchy between branches is a little weird
I hear the statement “the main branch is not special” a lot and I’ve been
puzzled about it – in most of the repositories I work in, main is
pretty special! Why are people saying it’s not?
I think the point is that even though branches do have relationships
between them (main is often special!), git doesn’t know anything about those
relationships.
You have to tell git explicitly about the relationship between branches every
single time you run a git command like git rebase or git merge, and if you
make a mistake things can get really weird.
I don’t know whether git’s design here is “right” or “wrong” (it definitely has some pros and cons, and I’m very tired of reading endless arguments about it), but I do think it’s surprising to a lot of people for good reason.
git’s UI around branches is weird too
Let’s say you want to look at just the “offshoot” commits on a branch, which as we’ve discussed is a completely normal thing to want.
Here’s how to see just the 2 offshoot commits on our branch with git log:
$ git switch mybranch
$ git log main..mybranch --oneline
13cb960 (HEAD -> mybranch, origin/mybranch) y
9554dab x
You can look at the combined diff for those same 2 commits with git diff like this:
$ git diff main...mybranch
So to see the 2 commits x and y with git log, you need to use 2 dots
(..), but to look at the same commits with git diff, you need to use 3 dots
(...).
Personally I can never remember what .. and ... mean so I just avoid
them completely even though in principle they seem useful.
in GitHub, the default branch is special
Also, it’s worth mentioning that GitHub does have a “special branch”: every
github repo has a “default branch” (in git terms, it’s what HEAD points at),
which is special in the following ways:
- it’s what you check out when you
git clonethe repository - it’s the default destination for pull requests
- github will suggest that you protect the default branch from force pushes
and probably even more that I’m not thinking of.
that’s all!
This all seems extremely obvious in retrospect, but it took me a long time to figure out what a more “intuitive” idea of a branch even might be because I was so used to the technical “a branch is a reference to a commit” definition.
I also hadn’t really thought about how git makes you tell it about the
hierarchy between your branches every time you run a git rebase or git
merge command – for me it’s second nature to do that and it’s not a big deal,
but now that I’m thinking about it, it’s pretty easy to see how somebody could
get mixed up.
Some notes on nix flakes
I’ve been using nix for about 9 months now. For all of that time I’ve been steadfastly ignoring flakes, but everyone keeps saying that flakes are great and the best way to use nix, so I decided to try to figure out what the deal is with them.
I found it very hard to find simple examples of flake files and I ran into a few problems that were very confusing to me, so I wanted to write down some very basic examples and some of the problems I ran into in case it’s helpful to someone else who’s getting started with flakes.
First, let’s talk about what a flake is a little.
addition from a couple months later: I still do not actually understand flakes, but a couple of months after I wrote this post, Jade wrote Flakes aren’t real and cannot hurt you: a guide to using Nix flakes the non-flake way which I still haven’t fully processed but is the closest thing I’ve found to an explanation of flakes that I can understand
flakes are self-contained
Every explanation I’ve found of flakes explains them in terms of other nix concepts (“flakes simplify nix usability”, “flakes are processors of Nix code”). Personally I really needed a way to think about flakes in terms of other non-nix things and someone made an analogy to Docker containers that really helped me, so I’ve been thinking about flakes a little like Docker container images.
Here are some ways in which flakes are like Docker containers:
- you can install and compile any software you want in them
- you can use them as a dev environment (the flake sets up all your dependencies)
- you can share your flake with other people with a
flake.nixfile and then they can build the software exactly the same way you built it (a little like how you can share aDockerfile, though flakes are MUCH better at the “exactly the same way you built it” thing)
flakes are also different from Docker containers in a LOT of ways:
- with a
Dockerfile, you’re not actually guaranteed to get the exact same results as another user. Withflake.nixandflake.lockyou are. - they run natively on Mac (you don’t need to use Linux / a Linux VM the way you do with Docker)
- different flakes can share dependencies very easily (you can technically share layers between Docker images, but flakes are MUCH better at this)
- flakes can depend on other flakes and pick and choose which parts they want to take from their dependencies
flake.nixfiles are programs in the nix programming language instead of mostly a bunch of shell commands- the way they do isolation is completely different (nix uses dynamic linker/rpath tricks instead of filesystem overlays, and there are no cgroups or namespaces or VMs or anything with nix)
Obviously this analogy breaks down pretty quickly (the list of differences is VERY long), but they do share the “you can share a dev environment with a single configuration file” design goal.
nix has a lot of pre-compiled binaries
To me one of the biggest advantages of nix is that I’m on a Mac and nix has a repository with a lot of pre-compiled binaries of various packages for Mac. I mostly mention this because people always say that nix is good because it’s “declarative” or “reproducible” or “functional” or whatever but my main motivation for using nix personally is that it has a lot of binary packages. I do appreciate that it makes it easier for me to build a 5-year-old version of hugo on mac though.
My impression is that nix has more binary packages than Homebrew does, so installing things is faster and I don’t need to build as much from source.
my goal: make a flake with every package I want installed on my system
Previously I was using nix as a Homebrew replacement like this (which I talk about more in this blog post):
- run
nix-env -iA nixpkgs.whateverto install stuff - that’s it
This worked great (except that it randomly broke occasionally, but someone helped me find a workaround for that so the random breaking wasn’t a big issue).
I thought it might be fun to have a single flake.nix file where I could maintain a list
of all the packages I wanted installed and then put all that stuff in a
directory in my PATH. This isn’t very well motivated: my previous setup was
generally working just fine, but I have a long history of fiddling with my
computer setup (Arch Linux ftw) and so I decided to have a Day Of Fiddling.
I think the only practical advantages of flakes for me are:
- I could theoretically use the
flake.nixfile to set up a new computer more easily - I can never remember how to uninstall software in nix, deleting a line in a configuration file is maybe easier to remember
These are pretty minor though.
how do we make a flake?
Okay, so I want to make a flake with a bunch of packages installed in it, let’s say Ruby and cowsay to start. How do I
do that? I went to zero-to-nix and copied and pasted some things and ended up with this flake.nix file (here it is in a gist):
{
inputs.nixpkgs.url = "github:NixOS/nixpkgs/nixpkgs-23.05-darwin";
outputs = { self, nixpkgs }: {
devShell.aarch64-darwin = nixpkgs.legacyPackages.aarch64-darwin.mkShell {
buildInputs = with nixpkgs.legacyPackages.aarch64-darwin; [
cowsay
ruby
];
};
};
}
This has a little bit of boilerplate so let’s list the things I understand about this:
- nixpkgs is a huge central repository of nix packages
aarch64-darwinis my machine’s architecture, this is important because I’m asking nix to download binaries- I’ve been thinking of an “input” as a sort of dependency.
nixpkgsis my one input. I get to pick and choose which bits of it I want to bring into my flake though. - the
github:NixOS/nixpkgs/nixpkgs-23.05-darwinurl scheme is a bit unusual: the format isgithub:USER/REPO_NAME/TAG_OR_BRANCH_NAME. So this is looking at thenixpkgs-23.05-darwintag in theNixOS/nixpkgsrepository. mkShellis a nix function that’s apparently useful if you want to runnix develop. I stopped using it after this so I don’t know more than that.devShell.aarch64-darwinis the name of the output. Apparently I need to give it that exact name or elsenix developwill yell at mecowsayandrubyare the things I’m taking from nixpkgs to put in my output- I don’t know what
selfis doing here or whatlegacyPackagesis about
Okay, cool. Let’s try to build it:
$ nix build
error: getting status of '/nix/store/w1v41cyqyx4d7q4g7c8nb50bp9dvjm29-source/flake.nix': No such file or directory
This error is VERY mysterious – what is /nix/store/w1v41cyqyx4d7q4g7c8nb50bp9dvjm29-source/ and why does nix think it should exist???
I was totally stuck until a very nice person on Mastodon helped me. So let’s talk about what’s going wrong here.
problem 1: nix completely ignores untracked files
Apparently nix flakes have some Weird Rules about git. The way it works is:
- if your current directory isn’t a git repo, everything is fine
- if your are in a git repository, and all your files have been
git added to git, everything is fine - but if you’re in a git directory and your
flake.nixfile isn’t tracked by git yet (because you just created it and are trying to get it to work), nix will COMPLETELY IGNORE YOUR FILE
After someone kindly told me what was happening, I found that this is mentioned in this blog post about flakes, which says:
Note that any file that is not tracked by Git is invisible during Nix evaluation
There’s also a github issue discussing what to do about this.
So we need to git add the file to get nix to pay attention to it. Cool. Let’s keep going.
a note on enabling the flake feature
To get any of the commands we’re going to talk about to work (like nix build), you need to enable two nix features:
- flakes
- “commands”
I set this up by putting experimental-features = nix-command flakes in my
~/.config/nix/nix.conf, but you can also run nix --extra-experimental-features "flakes nix-command" build instead of nix build.
time for nix develop
The instructions I was following told me that I could now run nix develop and get a shell inside my new environment. I tried it and it works:
$ nix develop
grapefruit:nix bork$ cowsay hi
____
< hi >
----
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
Cool! I was curious about how the PATH was set up inside this environment so I took a look:
grapefruit:nix bork$ echo $PATH
/nix/store/v5q1bxrqs6hkbsbrpwc81ccyyfpbl8wk-clang-wrapper-11.1.0/bin:/nix/store/x9jmvvxcys4zscff39cnpw0kyfvs80vp-clang-11.1.0/bin:/nix/store/3f1ii2y5fs1w7p0id9mkis0ffvhh1n8w-coreutils-9.1/bin:/nix/store/8ldvi6b3ahnph19vm1s0pyjqrq0qhkvi-cctools-binutils-darwin-wrapper-973.0.1/bin:/nix/store/5kbbxk18fp645r4agnn11bab8afm0ry3-cctools-binutils-darwin-973.0.1/bin:/nix/store/5si884h02nqx3dfcdm5irpf7caihl6f8-cowsay-3.7.0/bin:/nix/store/5bs5q2dw5bl7c4krcviga6yhdrqbvdq6-ruby-3.1.4/bin:/nix/store/3f1ii2y5fs1w7p0id9mkis0ffvhh1n8w-coreutils-9.1/bin
It looks like every dependency has been added to the PATH separately: for example there’s
/nix/store/5si884h02nqx3dfcdm5irpf7caihl6f8-cowsay-3.7.0/bin for cowsay and
/nix/store/5bs5q2dw5bl7c4krcviga6yhdrqbvdq6-ruby-3.1.4/bin for ruby. That’s
fine but it’s not how I wanted my setup to work: I wanted a single directory of
symlinks that I could just put in my PATH in my normal shell.
getting a directory of symlinks with buildEnv
I asked in the Nix discord and someone told me I could use buildEnv to turn
my flake into a directory of symlinks. As far as I can tell it’s just a way to
take nix packages and copy their symlinks into another directory.
After some fiddling, I ended up with this: (here’s a gist)
{
inputs.nixpkgs.url = "github:NixOS/nixpkgs/nixpkgs-23.05-darwin";
outputs = { self, nixpkgs }: {
defaultPackage.aarch64-darwin = nixpkgs.legacyPackages.aarch64-darwin.buildEnv {
name = "julia-stuff";
paths = with nixpkgs.legacyPackages.aarch64-darwin; [
cowsay
ruby
];
pathsToLink = [ "/share/man" "/share/doc" "/bin" "/lib" ];
extraOutputsToInstall = [ "man" "doc" ];
};
};
}
This put a bunch of symlinks in result/bin:
$ ls result/bin/
bundle bundler cowsay cowthink erb gem irb racc rake rbs rdbg rdoc ri ruby typeprof
Sweet! Now I have a thing I can theoretically put in my PATH – this result directory. Next I mostly just
needed to add every other package I wanted to install to this flake.nix file (I got the list
from nix-env -q).
next step: add all the packages
I ran into a bunch of weird problems adding all the packges I already had installed to my nix, so let’s talk about them.
problem 2: an unfree package
I wanted to install a non-free package called ngrok. Nix gave me 3 options for how I could do this. Option C seemed the most promising:
c) For `nix-env`, `nix-build`, `nix-shell` or any other Nix command you can add
{ allowUnfree = true; }
to ~/.config/nixpkgs/config.nix.
But adding { allowUnfree = true} to ~/.config/nixpkgs/config.nix didn’t do
anything for some reason so instead I went with option A, which did seem to
work:
$ export NIXPKGS_ALLOW_UNFREE=1
Note: For `nix shell`, `nix build`, `nix develop` or any other Nix 2.4+
(Flake) command, `--impure` must be passed in order to read this
environment variable.
problem 3: installing a flake from a relative path doesn’t work
I made a couple of flakes for custom Nix packages I’d made (which I wrote about in my first nix blog post, and I wanted to set them up like this (you can see the full configuration here):
hugoFlake.url = "path:../hugo-0.40";
paperjamFlake.url = "path:../paperjam";
This worked fine the first time I ran nix build, but when I reran nix build
again later I got some totally inscrutable error.
My workaround was just to run rm flake.lock everytime before running nix
build, which seemed to fix the problem.
I don’t really understand what’s going on here but there’s a very long github issue thread about it.
problem 4 : “error while reading the response from the build hook”
For a while, every time I ran nix build, I got this error:
$ nix build
error:
… while reading the response from the build hook
error: unexpected EOF reading a line
I spent a lot of time poking at my flake.nix trying to guess at what I could
have gone wrong.
A very nice person on Mastodon also helped me with this one and it turned out
that what I needed to do was find the nix-daemon process and kill it. I still
have no idea what happened here or what that error message means, I did upgrade
nix at some point during this whole process so I guess the
upgrade went wonky somehow.
I don’t think this one is a common problem.
problem 5: error with share/man symlink
I wanted to install the zulu package for Java, but when I tried to add it to
my list of packages I got this error complaining about a broken symlink:
$ nix build
error: builder for '/nix/store/4n9c4707iyiwwgi9b8qqx7mshzrvi27r-julia-dev.drv' failed with exit code 2;
last 1 log lines:
> error: not a directory: `/nix/store/2vc4kf5i28xcqhn501822aapn0srwsai-zulu-11.62.17/share/man'
For full logs, run 'nix log /nix/store/4n9c4707iyiwwgi9b8qqx7mshzrvi27r-julia-dev.drv'.
$ ls /nix/store/2vc4kf5i28xcqhn501822aapn0srwsai-zulu-11.62.17/share/ -l
lrwxr-xr-x 29 root 31 Dec 1969 man -> zulu-11.jdk/Contents/Home/man
I think what’s going on here is that the zulu package in nixpkgs-23.05 was
just broken (looks like it’s since been fixed in the unstable version).
I decided I didn’t feel like dealing with that and it turned out I already had
Java installed another way outside nix, so I just removed zulu from my list
and moved on.
putting it in my PATH
Now that I knew how to fix all of the weird problems I’d run into, I wrote a
little shell script called nix-symlink to build my flake and symlink it to
the very unimaginitively named ~/.nix-flake. The idea was that then I could
put ~/.nix-flake in my PATH and have all my programs available.
I think people usually use nix flakes in a per-project way instead of “a single global flake”, but this is how I wanted my setup to work so that’s what I did.
Here’s the nix-symlink script. The rm flake.lock is because of that relative path issue,
and the NIXPKGS_ALLOW_UNFREE is so I could install ngrok.
#!/bin/bash
set -euo pipefail
export NIXPKGS_ALLOW_UNFREE=1
cd ~/work/nixpkgs/flakes/grapefruit || exit
rm flake.lock
nix build --impure --out-link ~/.nix-flake
I put ~/.nix-flake at the beginning of my PATH (not at the end), but I might revisit that, we’ll see.
a note on GC roots
At the end of all this, I wanted to run a garbage collection because I’d
installed a bunch of random stuff that was taking about 20GB of extra hard
drive space in my /nix/store. I think there are two different ways to collect
garbage in nix:
nix-store --gcnix-collect-garbage
I have no idea what the difference between them is, but nix-collect-garbage
seemed to delete more stuff for some reason.
I wanted to check that my ~/.nix-flake directory was actually a GC root, so
that all my stuff wouldn’t get deleted when I ran a GC.
I ran nix-store --gc --print-roots to print out all the GC roots and my
~/.nix-flake was in there so everything was good! This command also runs a GC
so it was kind of a dangerous way to check if a GC was going to delete
everything, but luckily it worked.
problem 6: it’s a little slow
The last problem I ran into is speed. Previously, installing a new small package took me 2 seconds with nix-env -iA:
$ time nix-env -iA nixpkgs.sl
installing 'sl-5.05'
these 2 paths will be fetched (0.41 MiB download, 3.77 MiB unpacked):
/nix/store/yv1c98m5pncx3i5q7nr7i7mfjkiyii72-ncurses-6.4
/nix/store/2k78vf30czicjs0dq9x0sj4017ziwxkn-sl-5.05
copying path '/nix/store/yv1c98m5pncx3i5q7nr7i7mfjkiyii72-ncurses-6.4' from 'https://cache.nixos.org'...
copying path '/nix/store/2k78vf30czicjs0dq9x0sj4017ziwxkn-sl-5.05' from 'https://cache.nixos.org'...
building '/nix/store/zadpfs9k1cw5x7iniwwcqd8lb7nnc7bb-user-environment.drv'...
________________________________________________________
Executed in 1.96 secs fish external
Installing the same package with flakes takes 7 seconds, plus the time to edit the config file:
$ vim ~/work/nixpkgs/flakes/grapefruit/flake.nix
$ time nix-symlink
________________________________________________________
Executed in 7.04 secs fish external
usr time 1.78 secs 0.29 millis 1.78 secs
sys time 0.51 secs 2.03 millis 0.51 secs
I don’t know what to do about this so I’ll just live with it. We’ll see if this ends up being annoying or not
that’s it!
Now my new nix workflow is:
- edit my
flake.nixto add or remove packages (this file) - rerun my
nix-symlinkscript after editing it - maybe periodically run
nix-collect-garbage - that’s it
setting up the nix registry
The last thing I wanted to do was run
nix registry add nixpkgs github:NixOS/nixpkgs/nixpkgs-23.05-darwin
so that if I want to ad-hoc run a flake with nix run nixpkgs#cowsay, it’ll
take the version from the 23.05 version of nixpkgs. Mostly I just wanted this
so I didn’t have to download new versions of the nixpkgs repository all the
time – I just wanted to pin the 23.05 version.
I think nixpkgs-unstable is the default which I’m sure is fine too if you
want to have more up-to-date software.
my solutions are probably not the best
My solutions to all the nix problems I described are maybe not The Best ™,
but I’m happy that I figured out a way to install stuff that just involves one
relatively simple flake.nix file and a 6-line bash script and not a lot of other
machinery.
Personally I still feel extremely uncomfortable with nix and so it’s important to me to keep my configuration as simple as possible without a lot of extra abstraction layers that I don’t understand. I might try out flakey-profile at some point though because it seems extremely simple.
you can do way fancier stuff
You can manage a lot more stuff with nix, like:
- your npm / ruby / python / etc packages (I just do
npm installandpip installandbundle install) - your config files
There are all kind of tools that build on top of nix and flakes like home-manager. Like I said before though, it’s important to me to keep my configuration super simple so that I can have any hope of understanding how it works and being able to fix problems when it breaks so I haven’t paid attention to any of that stuff.
there’s a useful discord
I’ve been complaining about nix a little in this post, but as usual with open source projects I assume that nix has all of these papercuts because it’s a complicated system run by a small team of volunteers with very limited time.
Folks on the unofficial nix discord have been helpful, I’ve had a somewhat mixed experience there but they have a “support forum” section in there and I’ve gotten answers to a lot of my questions.
some other nix resources
the main resources I’ve found for understanding nix flakes are:
- Nix Flakes, Part 1: An introduction and tutorial, I think by their creator
- xe iaso’s blog
- ian henry’s blog
- the nix docs
- zero to nix
Also Kamal (my partner) uses nix and that really helps, I think using nix with an experienced friend around is a lot easier.
that’s all!
I still kind of like nix after using it for 9 months despite how confused I am about it all the time, I feel like once I get things working they don’t usually break.
We’ll see if that’s continues to be the case with flakes! Maybe I’ll go back to
just using nix-env -iAing everything if it goes badly.
How git cherry-pick and revert use 3-way merge
Hello! I was trying to explain to someone how git cherry-pick works the other
day, and I found myself getting confused.
What went wrong was: I thought that git cherry-pick was basically applying a
patch, but when I tried to actually do it that way, it didn’t work!
Let’s talk about what I thought cherry-pick did (applying a patch), why
that’s not quite true, and what it actually does instead (a “3-way merge”).
This post is extremely in the weeds and you definitely don’t need to understand this stuff to use git effectively. But if you (like me) are curious about git’s internals, let’s talk about it!
cherry-pick isn’t applying a patch
The way I previously understood git cherry-pick COMMIT_ID is:
- calculate the diff for
COMMIT_ID, likegit show COMMIT_ID --patch > out.patch - Apply the patch to the current branch, like
git apply out.patch
Before we get into this – I want to be clear that this model is mostly right, and if that’s your mental model that’s fine. But it’s wrong in some subtle ways and I think that’s kind of interesting, so let’s see how it works.
If I try to do the “calculate the diff and apply the patch” thing in a case where there’s a merge conflict, here’s what happens:
$ git show 10e96e46 --patch > out.patch
$ git apply out.patch
error: patch failed: content/post/2023-07-28-why-is-dns-still-hard-to-learn-.markdown:17
error: content/post/2023-07-28-why-is-dns-still-hard-to-learn-.markdown: patch does not apply
This just fails – it doesn’t give me any way to resolve the conflict or figure out how to solve the problem.
This is quite different from what actually happens when run git cherry-pick,
which is that I get a merge conflict:
$ git cherry-pick 10e96e46
error: could not apply 10e96e46... wip
hint: After resolving the conflicts, mark them with
hint: "git add/rm <pathspec>", then run
hint: "git cherry-pick --continue".
So it seems like the “git is applying a patch” model isn’t quite right. But the error message literally does say “could not apply 10e96e46”, so it’s not quite wrong either. What’s going on?
so what is cherry-pick doing?
I went digging through git’s source code to see how cherry-pick works, and
ended up at this line of code:
res = do_recursive_merge(r, base, next, base_label, next_label, &head, &msgbuf, opts);
So a cherry-pick is a… merge? What? How? What is it even merging? And how does merging even work in the first place?
I realized that I didn’t really know how git’s merge worked, so I googled it and found out that git does a thing called “3-way merge”. What’s that?
how git merges files: the 3-way merge
Let’s say I want to merge these 2 files. We’ll call them v1.py and v2.py.
def greet():
greeting = "hello"
name = "julia"
return greeting + " " + name
def say_hello():
greeting = "hello"
name = "aanya"
return greeting + " " + name
There are two lines that differ: we have
def greet()anddef say_helloname = "aanya"andname = "julia"
How do we know what to pick? It seems impossible!
But what if I told you that the original function was this (base.py)?
def say_hello():
greeting = "hello"
name = "julia"
return greeting + " " + name
Suddenly it seems a lot clearer! v1 changed the function’s name to greet
and v2 set name = "aanya". So to merge, we should make both those changes:
def greet():
greeting = "hello"
name = "aanya"
return greeting + " " + name
We can ask git to do this merge with git merge-file, and it gives us exactly
the result we expected: it picks def greet() and name = "aanya".
$ git merge-file v1.py base.py v2.py -p
def greet():
greeting = "hello"
name = "aanya"
return greeting + " " + name⏎
This way of merging where you merge 2 files + their original version is called a 3-way merge.
If you want to try it out yourself in a browser, I made a little playground at jvns.ca/3-way-merge/. I made it very quickly so it’s not mobile friendly.
git merges changes, not files
The way I think about the 3-way merge is – git merges changes, not files. We have an original file and 2 possible changes to it, and git tries to combine both of those changes in a reasonable way. Sometimes it can’t (for example if both changes change the same line), and then you get a merge conflict.
Git can also merge more than 2 possible changes: you can have an original file and 8 possible changes, and it can try to reconcile all of them. That’s called an octopus merge but I don’t know much more than that, I’ve never done one.
how git uses 3-way merge to apply a patch
Now let’s get a little weird! When we talk about git “applying a patch” (as you
do in a rebase or revert or cherry-pick), it’s not actually creating a
patch file and applying it. Instead, it’s doing a 3-way merge.
Here’s how applying commit X as a patch to your current commit corresponds to
this v1, v2, and base setup from before:
- The version of the file in your current commit is
v1. - The version of the file before commit X is
base - The version of the file in commit X. Call that
v2 - Run
git merge-file v1 base v2to combine them (technically git does not actually rungit merge-file, it runs a C function that does it)
Together, you can think of base and v2 as being the “patch”: the diff between
them is the change that you want to apply to v1.
how cherry-pick works
Let’s say we have this commit graph, and we want to cherry-pick Y on to main:
A - B (main)
\
\
X - Y - Z
How do we turn that into a 3-way merge? Here’s how it translates into our v1, v2 and base from earlier:
Bis v1Xis the base,Yis v2
So together X and Y are the “patch”.
And git rebase is just like git cherry-pick, but repeated a bunch of times.
how revert works
Now let’s say we want to run git revert Y on this commit graph
X - Y - Z - A - B
Bis v1Yis the base,Xis v2
This is exactly like a cherry-pick, but with X and Y reversed. We have to
flip them because we want to apply a “reverse patch”.
Revert and cherry-pick are so closely related in git that they’re actually implemented in the same file: revert.c.
this “3-way patch” is a really cool trick
This trick of using a 3-way merge to apply a commit as a patch seems really clever and cool and I’m surprised that I’d never heard of it before! I don’t know of a name for it, but I kind of want to call it a “3-way patch”.
The idea is that with a 3-way patch, you specify the patch as 2 files: the file
before the patch and after (base and v2 in our language in this post).
So there are 3 files involved: 1 for the original and 2 for the patch.
The point is that the 3-way patch is a much better way to patch than a normal patch, because you have a lot more context for merging when you have both full files.
Here’s more or less what a normal patch for our example looks like:
@@ -1,1 +1,1 @@:
- def greet():
+ def say_hello():
greeting = "hello"
and a 3-way patch. This “3-way patch” is not a real file format, it’s just something I made up.
BEFORE: (the full file)
def greet():
greeting = "hello"
name = "julia"
return greeting + " " + name
AFTER: (the full file)
def say_hello():
greeting = "hello"
name = "julia"
return greeting + " " + name
“Building Git” talks about this
The book Building Git by James Coglan
is the only place I could find other than the git source code explaining how
git cherry-pick actually uses 3-way merge under the hood (I thought Pro Git might
talk about it, but it didn’t seem to as far as I could tell).
I actually went to buy it and it turned out that I’d already bought it in 2019 so it was a good reference to have here :)
merging is actually much more complicated than this
There’s more to merging in git than the 3-way merge – there’s something called a “recursive merge” that I don’t understand, and there are a bunch of details about how to deal with handling file deletions and moves, and there are also multiple merge algorithms.
My best idea for where to learn more about this stuff is Building Git, though I haven’t read the whole thing.
so what does git apply do?
I also went looking through git’s source to find out what git apply does, and it
seems to (unsurprisingly) be in apply.c. That code parses a patch file, and
then hunts through the target file to figure out where to apply it. The core logic
seems to be around here:
I think the idea is to start at the line number that the patch suggested and
then hunt forwards and backwards from there to try to find it:
/*
* There's probably some smart way to do this, but I'll leave
* that to the smart and beautiful people. I'm simple and stupid.
*/
backwards = current;
backwards_lno = line;
forwards = current;
forwards_lno = line;
current_lno = line;
for (i = 0; ; i++) {
...
That all seems pretty intuitive and about what I’d naively expect.
how git apply --3way works
git apply also has a --3way flag that does a 3-way merge. So we actually
could have more or less implemented git cherry-pick with git apply like
this:
$ git show 10e96e46 --patch > out.patch
$ git apply out.patch --3way
Applied patch to 'content/post/2023-07-28-why-is-dns-still-hard-to-learn-.markdown' with conflicts.
U content/post/2023-07-28-why-is-dns-still-hard-to-learn-.markdown
--3way doesn’t just use the contents of the patch file though! The patch file starts with:
index d63ade04..65778fc0 100644
d63ade04 and 65778fc0 are the IDs of the old/new versions of that file in
git’s object database, so git can retrieve them to do a 3-way patch
application. This won’t work if someone emails you a patch and you don’t have
the files for the new/old versions of the file though: if you’re missing the
blobs you’ll get this error:
$ git apply out.patch
error: repository lacks the necessary blob to perform 3-way merge.
3-way merge is old
A couple of people pointed out that 3-way merge is much older than git, it’s from the late 70s or something. Here’s a paper from 2007 talking about it
that’s all!
I was pretty surprised to learn that I didn’t actually understand the core way that git applies patches internally – it was really cool to learn about!
I have lots of issues with git’s UI but I think this particular thing is not one of them. The 3-way merge seems like a nice unified way to solve a bunch of different problems, it’s pretty intuitive for people (the idea of “applying a patch” is one that a lot of programmers are used to thinking about, and the fact that it’s implemented as a 3-way merge under the hood is an implementation detail that nobody actually ever needs to think about).
Also a very quick plug: I’m working on writing a zine about git, if you’re interested in getting an email when it comes out you can sign up to my very infrequent announcements mailing list.
git rebase: what can go wrong?
Hello! While talking with folks about Git, I’ve been seeing a comment over and over to the effect of “I hate rebase”. People seemed to feel pretty strongly about this, and I was really surprised because I don’t run into a lot of problems with rebase and I use it all the time.
I’ve found that if many people have a very strong opinion that’s different from mine, usually it’s because they have different experiences around that thing from me.
So I asked on Mastodon:
today I’m thinking about the tradeoffs of using
git rebasea bit. I think the goal of rebase is to have a nice linear commit history, which is something I like.but what are the costs of using rebase? what problems has it caused for you in practice? I’m really only interested in specific bad experiences you’ve had here – not opinions or general statements like “rewriting history is bad”
I got a huge number of incredible answers to this, and I’m going to do my best to summarize them here. I’ll also mention solutions or workarounds to those problems in cases where I know of a solution. Here’s the list:
- fixing the same conflict repeatedly is annoying
- rebasing a lot of commits is hard
- undoing a rebase is hard
- force pushing to shared branches can cause lost work
- force pushing makes code reviews harder
- losing commit metadata
- more difficult reverts
- rebasing can break intermediate commits
- accidentally run git commit –amend instead of git rebase –continue
- splitting commits in an interactive rebase is hard
- complex rebases are hard
- rebasing long lived branches can be annoying
- rebase and commit discipline
- a “squash and merge” workflow
- miscellaneous problems
My goal with this isn’t to convince anyone that rebase is bad and you shouldn’t use it (I’m certainly going to keep using rebase!). But seeing all these problems made me want to be more cautious about recommending rebase to newcomers without explaining how to use it safely. It also makes me wonder if there’s an easier workflow for cleaning up your commit history that’s harder to accidentally mess up.
my git workflow assumptions
First, I know that people use a lot of different Git workflows. I’m going to be talking about the workflow I’m used to when working on a team, which is:
- the team uses a central Github/Gitlab repo to coordinate
- there’s one central
mainbranch. It’s protected from force pushes. - people write code in feature branches and make pull requests to
main - The web service is deployed from
mainevery time a pull request is merged. - the only way to make a change to
mainis by making a pull request on Github/Gitlab and merging it
This is not the only “correct” git workflow (it’s a very “we run a web service” workflow and open source project or desktop software with releases generally use a slightly different workflow). But it’s what I know so that’s what I’ll talk about.
two kinds of rebase
Also before we start: one big thing I noticed is that there were 2 different kinds of rebase that kept coming up, and only one of them requires you to deal with merge conflicts.
- rebasing on an ancestor, like
git rebase -i HEAD^^^^^^^to squash many small commits into one. As long as you’re just squashing commits, you’ll never have to resolve a merge conflict while doing this. - rebasing onto a branch that has diverged, like
git rebase main. This can cause merge conflicts.
I think it’s useful to make this distinction because sometimes I’m thinking about rebase type 1 (which is a lot less likely to cause problems), but people who are struggling with it are thinking about rebase type 2.
Now let’s move on to all the problems!
fixing the same conflict repeatedly is annoying
If you make many tiny commits, sometimes you end up in a hellish loop where you have to fix the same merge conflict 10 times. You can also end up fixing merge conflicts totally unnecessarily (like dealing with a merge conflict in code that a future commit deletes).
There are a few ways to make this better:
- first do a
git rebase -i HEAD^^^^^^^^^^^to squash all of the tiny commits into 1 big commit and then agit rebase mainto rebase onto a different branch. Then you only have to fix the conflicts once. - use
git rerereto automate repeatedly resolving the same merge conflicts (“rerere” stands for “reuse recorded resolution”, it’ll record your previous merge conflict resolutions and replay them). I’ve never tried this but I think you need to setgit config rerere.enabled trueand then it’ll automatically help you.
Also if I find myself resolving merge conflicts more than once in a rebase,
I’ll usually run git rebase --abort to stop it and then squash my commits into
one and try again.
rebasing a lot of commits is hard
Generally when I’m doing a rebase onto a different branch, I’m rebasing 1-2 commits. Maybe sometimes 5! Usually there are no conflicts and it works fine.
Some people described rebasing hundreds of commits by many different people onto a different branch. That sounds really difficult and I don’t envy that task.
undoing a rebase is hard
I heard from several people that when they were new to rebase, they messed up a rebase and permanently lost a week of work that they then had to redo.
The problem here is that undoing a rebase that went wrong is much more complicated
than undoing a merge that went wrong (you can undo a bad merge with something like git reset --hard HEAD^).
Many newcomers to rebase don’t even realize that undoing a rebase is even
possible, and I think it’s pretty easy to understand why.
That said, it is possible to undo a rebase that went wrong. Here’s an example of how to undo a rebase using git reflog.
step 1: Do a bad rebase (for example run git rebase -I HEAD^^^^^ and just delete 3 commits)
step 2: Run git reflog. You should see something like this:
ee244c4 (HEAD -> main) HEAD@{0}: rebase (finish): returning to refs/heads/main
ee244c4 (HEAD -> main) HEAD@{1}: rebase (pick): test
fdb8d73 HEAD@{2}: rebase (start): checkout HEAD^^^^^^^
ca7fe25 HEAD@{3}: commit: 16 bits by default
073bc72 HEAD@{4}: commit: only show tooltips on desktop
step 3: Find the entry immediately before rebase (start). In my case that’s ca7fe25
step 4: Run git reset --hard ca7fe25
A couple of other ways to undo a rebase:
- Apparently
@always refers to your current branch in git, so you can rungit reset --hard @{1}to reset your branch to its previous location. - Another solution folks mentioned that avoids having to use the reflog is to
make a “backup branch” with
git switch -c backupbefore rebasing, so you can easily get back to the old commit.
force pushing to shared branches can cause lost work
A few people mentioned the following situation:
- You’re collaborating on a branch with someone
- You push some changes
- They rebase the branch and run
git push --force(maybe by accident) - Now when you run
git pull, it’s a mess – you get the afatal: Need to specify how to reconcile divergent brancheserror - While trying to deal with the fallout you might lose some commits, especially if some of the people are involved aren’t very comfortable with git
This is an even worse situation than the “undoing a rebase is hard” situation because the missing commits might be split across many different people’s and the only worse thing than having to hunt through the reflog is multiple different people having to hunt through the reflog.
This has never happened to me because the only branch I’ve ever collaborated on
is main, and main has always been protected from force pushing (in my
experience the only way you can get something into main is through a pull
request). So I’ve never even really been in a situation where this could
happen. But I can definitely see how this would cause problems.
The main tools I know to avoid this are:
- don’t rebase on shared branches
- use
--force-with-leasewhen force pushing, to make sure that nobody else has pushed to the branch since your last fetch
Apparently the “since your last fetch” is important here – if you run git
fetch immediately before running git push --force-with-lease, the
--force-with-lease won’t protect you at all.
I was curious about why people would run git push --force on a shared branch. Some reasons people gave were:
- they’re working on a collaborative feature branch, and the feature branch needs to be rebased onto
main. The idea here is that you’re just really careful about coordinating the rebase so nothing gets lost. - as an open source maintainer, sometimes they need to rebase a contributor’s branch to fix a merge conflict
- they’re new to git, read some instructions online that suggested
git rebaseandgit push --forceas a solution, and followed them without understanding the consequences - they’re used to doing
git push --forceon a personal branch and ran it on a shared branch by accident
force pushing makes code reviews harder
The situation here is:
- You make a pull request on GitHub
- People leave some comments
- You update the code to address the comments, rebase to clean up your commits, and force push
- Now when the reviewer comes back, it’s hard for them to tell what you changed since the last time you saw it – all the commits show up as “new”.
One way to avoid this is to push new commits addressing the review comments, and then after the PR is approved do a rebase to reorganize everything.
I think some reviewers are more annoyed by this problem than others, it’s kind of a personal preference. Also this might be a Github-specific issue, other code review tools might have better tools for managing this.
losing commit metadata
If you’re rebasing to squash commits, you can lose important commit metadata
like Co-Authored-By. Also if you GPG sign your commits, rebase loses the
signatures.
There’s probably other commit metadata that you can lose that I’m not thinking of.
I haven’t run into this one so I’m not sure how to avoid it. I think GPG signing commits isn’t as popular as it used to be.
more difficult reverts
Someone mentioned that it’s important for them to be able to easily revert merging any branch (in case the branch broke something), and if the branch contains multiple commits and was merged with rebase, then you need to do multiple reverts to undo the commits.
In a merge workflow, I think you can revert merging any branch just by reverting the merge commit.
rebasing can break intermediate commits
If you’re trying to have a very clean commit history where the tests pass on every commit (very admirable!), rebasing can result in some intermediate commits that are broken and don’t pass the tests, even if the final commit passes the tests.
Apparently you can avoid this by using git rebase -x to run the test suite at
every step of the rebase and make sure that the tests are still passing. I’ve
never done that though.
accidentally run git commit --amend instead of git rebase --continue
A couple of people mentioned issues with running git commit --amend instead of git rebase --continue when resolving a merge conflict.
The reason this is confusing is that there are two reasons when you might want to edit files during a rebase:
- editing a commit (by using
editingit rebase -i), where you need to writegit commit --amendwhen you’re done - a merge conflict, where you need to run
git rebase --continuewhen you’re done
It’s very easy to get these two cases mixed up because they feel very similar. I think what goes wrong here is that you:
- Start a rebase
- Run into a merge conflict
- Resolve the merge conflict, and run
git add file.txt - Run
git commitbecause that’s what you’re used to doing after you rungit add - But you were supposed to run
git rebase --continue! Now you have a weird extra commit, and maybe it has the wrong commit message and/or author
splitting commits in an interactive rebase is hard
The whole point of rebase is to clean up your commit history, and combining
commits with rebase is pretty easy. But what if you want to split up a commit into 2
smaller commits? It’s not as easy, especially if the commit you want to split
is a few commits back! I actually don’t really know how to do it even though I
feel very comfortable with rebase. I’d probably just do git reset HEAD^^^ or
something and use git add -p to redo all my commits from scratch.
One person shared their workflow for splitting commits with rebase.
complex rebases are hard
If you try to do too many things in a single git rebase -i (reorder commits
AND combine commits AND modify a commit), it can get really confusing.
To avoid this, I personally prefer to only do 1 thing per rebase, and if I want to do 2 different things I’ll do 2 rebases.
rebasing long lived branches can be annoying
If your branch is long-lived (like for 1 month), having to rebase repeatedly gets painful. It might be easier to just do 1 merge at the end and only resolve the conflicts once.
The dream is to avoid this problem by not having long-lived branches but it doesn’t always work out that way in practice.
miscellaneous problems
A few more issues that I think are not that common:
- Stopping a rebase wrong: If you try to abort a rebase that’s going badly with
git reset --hardinstead ofgit rebase --abort, things will behave weirdly until you stop it properly - Weird interactions with merge commits: A couple of quotes about this: “If you rebase your working copy to keep a clean history for a branch, but the underlying project uses merges, the result can be ugly. If you do rebase -i HEAD~4 and the fourth commit back is a merge, you can see dozens of commits in the interactive editor.“, “I’ve learned the hard way to never rebase if I’ve merged anything from another branch”
rebase and commit discipline
I’ve seen a lot of people arguing about rebase. I’ve been thinking about why this is and I’ve noticed that people work at a few different levels of “commit discipline”:
- Literally anything goes, “wip”, “fix”, “idk”, “add thing”
- When you make a pull request (on github/gitlab), squash all of your crappy commits into a single commit with a reasonable message (usually the PR title)
- Atomic Beautiful Commits – every change is split into the appropriate number of commits, where each one has a nice commit message and where they all tell a story around the change you’re making
Often I think different people inside the same company have different levels of commit discipline, and I’ve seen people argue about this a lot. Personally I’m mostly a Level 2 person. I think Level 3 might be what people mean when they say “clean commit history”.
I think Level 1 and Level 2 are pretty easy to achieve without rebase – for
level 1, you don’t have to do anything, and for level 2, you can either press
“squash and merge” in github or run git switch main; git merge --squash mybranch on the command line.
But for Level 3, you either need rebase or some other tool (like GitUp) to help you organize your commits to tell a nice story.
I’ve been wondering if when people argue about whether people “should” use rebase or not, they’re really arguing about which minimum level of commit discipline should be required.
I think how this plays out also depends on how big the changes folks are making – if folks are usually making pretty small pull requests anyway, squashing them into 1 commit isn’t a big deal, but if you’re making a 6000-line change you probably want to split it up into multiple commits.
a “squash and merge” workflow
A couple of people mentioned using this workflow that doesn’t use rebase:
- make commits
- Run
git merge mainto merge main into the branch periodically (and fix conflicts if necessary) - When you’re done, use GitHub’s “squash and merge” feature (which is the
equivalent of running
git checkout main; git merge --squash mybranch) to squash all of the changes into 1 commit. This gets rid of all the “ugly” merge commits.
I originally thought this would make the log of commits on my branch too ugly,
but apparently git log main..mybranch will just show you the changes on your
branch, like this:
$ git log main..mybranch
756d4af (HEAD -> mybranch) Merge branch 'main' into mybranch
20106fd Merge branch 'main' into mybranch
d7da423 some commit on my branch
85a5d7d some other commit on my branch
Of course, the goal here isn’t to force people who have made beautiful atomic commits to squash their commits – it’s just to provide an easy option for folks to clean up a messy commit history (“add new feature; wip; wip; fix; fix; fix; fix; fix;“) without having to use rebase.
I’d be curious to hear about other people who use a workflow like this and if it works well.
there are more problems than I expected
I went into this really feeling like “rebase is fine, what could go wrong?” But many of these problems actually have happened to me in the past, it’s just that over the years I’ve learned how to avoid or fix all of them.
And I’ve never really seen anyone share best practices for rebase, other than “never force push to a shared branch”. All of these honestly make me a lot more reluctant to recommend using rebase.
To recap, I think these are my personal rebase rules I follow:
- stop a rebase if it’s going badly instead of letting it finish (with
git rebase --abort) - know how to use
git reflogto undo a bad rebase - don’t rebase a million tiny commits (instead do it in 2 steps:
git rebase -i HEAD^^^^and thengit rebase main) - don’t do more than one thing in a
git rebase -i. Keep it simple. - never force push to a shared branch
- never rebase commits that have already been pushed to
main
Thanks to Marco Rogers for encouraging me to think about the problems people have with rebase, and to everyone on Mastodon who helped with this.