Reading List
The most recent articles from a list of feeds I subscribe to.
Dealing with diverged git branches
Hello! One of the most common problems I see folks struggling with in Git is
when a local branch (like main) and a remote branch (maybe also called
main) have diverged.
There are two things that make this situation hard:
- If you’re not used to interpreting git’s error messages, it’s nontrivial to
even realize that your
mainhas diverged from the remotemain(git will often just give you an intimidating but generic error message like! [rejected] main -> main (non-fast-forward) error: failed to push some refs to 'github.com:jvns/int-exposed') - Once you realize that your branch has diverged from the remote
main, there no single clear way to handle it (what you need to do depends on the situation and your git workflow)
So let’s talk about a) how to recognize when you’re in a situation where a local branch and remote branch have diverged and b) what you can do about it! Here’s a quick table of contents:
Let’s start with what it means for 2 branches to have “diverged”.
what does “diverged” mean?
If you have a local main and a remote main, there are 4 basic configurations:
1: up to date. The local and remote main branches are in the exact same place. Something like this:
a - b - c - d
^ LOCAL
^ REMOTE
2: local is behind
Here you might want to git pull. Something like this:
a - b - c - d - e
^ LOCAL ^ REMOTE
3: remote is behind
Here you might want to git push. Something like this:
a - b - c - d - e
^ REMOTE ^ LOCAL
4: they’ve diverged :(
This is the situation we’re talking about in this blog post. It looks something like this:
a - b - c - d - e
\ ^ LOCAL
-- f
^ REMOTE
There’s no one recipe for resolving this (how you want to handle it depends on the situation and your git workflow!) but let’s talk about how to recognize that you’re in that situation and some options for how to resolve it.
recognizing when branches are diverged
There are 3 main ways to tell that your branch has diverged.
way 1: git status
The easiest way to is to run git fetch and then git status. You’ll get a message something like this:
$ git fetch
$ git status
On branch main
Your branch and 'origin/main' have diverged, <-- here's the relevant line!
and have 1 and 2 different commits each, respectively.
(use "git pull" to merge the remote branch into yours)
way 2: git push
When I run git push, sometimes I get an error like this:
$ git push
To github.com:jvns/int-exposed
! [rejected] main -> main (non-fast-forward)
error: failed to push some refs to 'github.com:jvns/int-exposed'
hint: Updates were rejected because the tip of your current branch is behind
hint: its remote counterpart. Integrate the remote changes (e.g.
hint: 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
This doesn’t always mean that my local main and the remote main have
diverged (it could just mean that my main is behind), but for me it often
means that. So if that happens I might run git fetch and git status to
check.
way 3: git pull
If I git pull when my branches have diverged, I get this error message:
$ git pull
hint: You have divergent branches and need to specify how to reconcile them.
hint: You can do so by running one of the following commands sometime before
hint: your next pull:
hint:
hint: git config pull.rebase false # merge
hint: git config pull.rebase true # rebase
hint: git config pull.ff only # fast-forward only
hint:
hint: You can replace "git config" with "git config --global" to set a default
hint: preference for all repositories. You can also pass --rebase, --no-rebase,
hint: or --ff-only on the command line to override the configured default per
hint: invocation.
fatal: Need to specify how to reconcile divergent branches.
This is pretty clear about the issue (“you have divergent branches”).
git pull doesn’t always spit out this error message though when your branches have diverged: it depends on how
you configure git. The three other options I’m aware of are:
- if you set
git config pull.rebase false, it’ll automatically start merging the remotemain - if you set
git config pull.rebase true, it’ll automatically start rebasing onto the remotemain - if you set
git config pull.ff only, it’ll exit with the errorfatal: Not possible to fast-forward, aborting.
Now that we’ve talked about some ways to recognize that you’re in a situation where your local branch has diverged from the remote one, let’s talk about what you can do about it.
there’s no one solution
There’s no “best” way to resolve branches that have diverged – it really depends on your workflow for git and why the situation is happening.
I use 3 main solutions, depending on the situation:
- I want to keep both sets of changes on
main. To do this, I’ll rungit pull --rebase. - The remote changes are useless and I want to overwrite them. To do this,
I’ll run
git push --force - The local changes are useless and I want to overwrite them. To do this, I’ll
run
git reset --hard origin/main
Here are some more details about all 3 of these solutions.
solution 1.1: git pull --rebase
This is what I do when I want to keep both sets of changes. It rebases main
onto the remote main branch. I mostly use this in repositories where I’m
doing all of my work on the main branch.
You can configure git config pull.rebase true, to do this automatically every
time, but I don’t because sometimes I actually want to use solutions 2 or 3
(overwrite my local changes with the remote, or the reverse). I’d rather be
warned “hey, these branches have diverged, how do you want to handle it?” and
decide for myself if I want to rebase or not.
solution 1.2: git pull --no-rebase
This starts a merge between the local and remote main. Here you’ll need to:
- Run
git pull --no-rebase. This starts a merge and (if it succeeds) opens a text editor so that you can confirm that you want to commit the merge - Save the file in your text editor.
I don’t have too much to say about this because I’ve never done it. I always use rebase instead. That’s a personal workflow choice though, lots of people have very legitimate reasons to avoid rebase.
solution 2.1: git push --force
Sometimes I know that the work on the remote main is actually useless and I
just want to overwrite it with whatever is on my local main.
I do this pretty often on private repositories where I’m the only committer, for example I might:
git pushsome commits- belatedly decide I want to change the most recent commit
- make the changes and run
git commit --amend - run
git push --force
Of course, if the repository has many different committers, force-pushing in this way can cause a lot of problems. On shared repositories I’ll usually enable github branch protection so that it’s impossible to force push.
solution 2.2: git push --force-with-lease
I’ve still never actually used git push --force-with-lease, but I’ve seen a
lot of people recommend it as an alternative to git push --force that makes
sure that nobody else has changed the branch since the last time you pushed or
fetched, so that you don’t accidentally blow their changes away.
Seems like a good option. I did notice that --force-with-lease isn’t
foolproof though – for example this git commit
talks about how if you use VSCode’s autofetching feature to continuously git fetch,
then --force-with-lease won’t help you.
Apparently now Git also has --force-with-lease --force-if-includes
(documented here),
which I think checks the reflog to make sure that you’ve already integrated the
remote branch into your branch somehow. I still don’t totally understand this
but I found this stack overflow conversation
helpful.
solution 3.1: git reset --hard origin/main
You can use this as the reverse of git push --force (since there’s no git pull --force). I do this when I know that
my local work shouldn’t be there and I want to throw it away and replace it
with whatever’s on the remote branch.
For example, I might do this if I accidentally made a commit to main that
actually should have been on new branch. In that case I’ll also create a new
branch (new-branch in this example) to store my local work on the main
branch, so it’s not really being thrown away.
Fixing that problem looks like this:
git checkout main
# 1. create `new-branch` to store my work
git checkout -b new-branch
# 2. go back to the `main` branch I messed up
git checkout main
# 3. make sure that my `origin/main` is up to date
git fetch
# 4. double check to make sure I don't have any uncomitted
# work because `git reset --hard` will blow it away
git status
# 5. force my local branch to match the remote `main`
# NOTE: replace `origin/main` with the actual name of the
# remote/branch, you can get this from `git status`.
git reset --hard origin/main
This “store your work on main on a new branch and then git reset --hard” pattern can
also be useful if you’re not sure yet how to solve the conflict, since most
people are more used to merging 2 local branches than dealing with merging a
remote branch.
As always git reset --hard is a dangerous action and you can permanently lose
your uncommitted work. I always run git status first to make sure I don’t
have any uncommitted changes.
Some alternatives to using git reset --hard for this:
- check out some other branch and run
git branch -f main origin/main. - check out some other branch and run
git fetch origin main:main --force
that’s all!
I’d never really thought about how confusing the git push and git pull
error messages can be if you’re not used to reading them.
Inside .git
Hello! I posted a comic on Mastodon this week about what’s in the .git
directory and someone requested a text version, so here it is. I added some
extra notes too. First, here’s the image. It’s a ~15 word explanation of each
part of your .git directory.

You can git clone https://github.com/jvns/inside-git if you want to run all
these examples yourself.
Here’s a table of contents:
- HEAD: .git/head
- branch: .git/refs/heads/main
- commit: .git/objects/10/93da429…
- tree: .git/objects/9f/83ee7550…
- blobs: .git/objects/5a/475762c…
- reflog: .git/logs/refs/heads/main
- remote-tracking branches: .git/refs/remotes/origin/main
- tags: .git/refs/tags/v1.0
- the stash: .git/refs/stash
- .git/config
- hooks: .git/hooks/pre-commit
- the staging area: .git/index
- this isn’t exhaustive
- this isn’t meant to completely explain git
The first 5 parts (HEAD, branch, commit, tree, blobs) are the core of git.
HEAD: .git/head
HEAD is a tiny file that just contains the name of your current branch.
Example contents:
$ cat .git/HEAD
ref: refs/heads/main
HEAD can also be a commit ID, that’s called “detached HEAD state”.
branch: .git/refs/heads/main
A branch is stored as a tiny file that just contains 1 commit ID. It’s stored
in a folder called refs/heads.
Example contents:
$ cat .git/refs/heads/main
1093da429f08e0e54cdc2b31526159e745d98ce0
commit: .git/objects/10/93da429...
A commit is a small file containing its parent(s), message, tree, and author.
Example contents:
$ git cat-file -p 1093da429f08e0e54cdc2b31526159e745d98ce0
tree 9f83ee7550919867e9219a75c23624c92ab5bd83
parent 33a0481b440426f0268c613d036b820bc064cdea
author Julia Evans <julia@example.com> 1706120622 -0500
committer Julia Evans <julia@example.com> 1706120622 -0500
add hello.py
These files are compressed, the best way to see objects is with git cat-file -p HASH.
tree: .git/objects/9f/83ee7550...
Trees are small files with directory listings. The files in it are called blobs.
Example contents:
$ git cat-file -p 9f83ee7550919867e9219a75c23624c92ab5bd83
100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 .gitignore
100644 blob 665c637a360874ce43bf74018768a96d2d4d219a hello.py
040000 tree 24420a1530b1f4ec20ddb14c76df8c78c48f76a6 lib
The permissions here LOOK like unix permissions, but they’re actually super restricted, only 644 and 755 are allowed.
blobs: .git/objects/5a/475762c...
blobs are the files that contain your actual code
Example contents:
$ git cat-file -p 665c637a360874ce43bf74018768a96d2d4d219a
print("hello world!")
Storing a new blob with every change can get big, so git gc periodically
packs them for efficiency in .git/objects/pack.
reflog: .git/logs/refs/heads/main
The reflog stores the history of every branch, tag, and HEAD. For (mostly) every file in .git/refs, there’s a corresponding log in .git/logs/refs.
Example content for the main branch:
$ tail -n 1 .git/logs/refs/heads/main
33a0481b440426f0268c613d036b820bc064cdea
1093da429f08e0e54cdc2b31526159e745d98ce0
Julia Evans <julia@example.com>
1706119866 -0500
commit: add hello.py
each line of the reflog has:
- before/after commit IDs
- user
- timestamp
- log message
Normally it’s all one line, I just wrapped it for readability here.
remote-tracking branches: .git/refs/remotes/origin/main
Remote-tracking branches store the most recently seen commit ID for a remote branch
Example content:
$ cat .git/refs/remotes/origin/main
fcdeb177797e8ad8ad4c5381b97fc26bc8ddd5a2
When git status says “you’re up to date with origin/main”, it’s just looking
at this. It’s often out of date, you can update it with git fetch origin main.
tags: .git/refs/tags/v1.0
A tag is a tiny file in .git/refs/tags containing a commit ID.
Example content:
$ cat .git/refs/tags/v1.0
1093da429f08e0e54cdc2b31526159e745d98ce0
Unlike branches, when you make new commits it doesn’t update the tag.
the stash: .git/refs/stash
The stash is a tiny file called .git/refs/stash. It contains the commit ID of a commit that’s created when you run git stash.
cat .git/refs/stash
62caf3d918112d54bcfa24f3c78a94c224283a78
The stash is a stack, and previous values are stored in .git/logs/refs/stash (the reflog for stash).
cat .git/logs/refs/stash
62caf3d9 e85c950f Julia Evans <julia@example.com> 1706290652 -0500 WIP on main: 1093da4 add hello.py
00000000 62caf3d9 Julia Evans <julia@example.com> 1706290668 -0500 WIP on main: 1093da4 add hello.py
Unlike branches and tags, if you git stash pop a commit from the stash, it’s
deleted from the reflog so it’s almost impossible to find it again. The
stash is the only reflog in git where things get deleted very soon after
they’re added. (entries expire out of the branch reflogs too, but generally
only after 90 days)
A note on refs:
At this point you’ve probably noticed that a lot of things (branches,
remote-tracking branches, tags, and the stash) are commit IDs in .git/refs.
They’re called “references” or “refs”. Every ref is a commit ID, but the
different types of refs are treated VERY differently by git, so I find it
useful to think about them separately even though they all use
the same file format. For example, git deletes things from the stash reflog in
a way that it won’t for branch or tag reflogs.
.git/config
.git/config is a config file for the repository. It’s where you configure
your remotes.
Example content:
[remote "origin"]
url = git@github.com: jvns/int-exposed
fetch = +refs/heads/*: refs/remotes/origin/*
[branch "main"]
remote = origin
merge refs/heads/main
git has local and global settings, the local settings are here and the global
ones are in ~/.gitconfig hooks
hooks: .git/hooks/pre-commit
Hooks are optional scripts that you can set up to run (eg before a commit) to do anything you want.
Example content:
#!/bin/bash
any-commands-you-want
(this obviously isn’t a real pre-commit hook)
the staging area: .git/index
The staging area stores files when you’re preparing to commit. This one is a binary file, unlike a lot of things in git which are essentially plain text files.
As far as I can tell the best way to look at the contents of the index is with git ls-files --stage:
$ git ls-files --stage
100644 e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 0 .gitignore
100644 665c637a360874ce43bf74018768a96d2d4d219a 0 hello.py
100644 e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 0 lib/empty.py
this isn’t exhaustive
There are some other things in .git like FETCH_HEAD, worktrees, and
info. I only included the ones that I’ve found it useful to understand.
this isn’t meant to completely explain git
One of the most common pieces of advice I hear about git is “just learn how
the .git directory is structured and then you’ll understand everything!”.
I love understanding the internals of things more than anyone, but there’s a LOT that “how the .git directory is structured” doesn’t explain, like:
- how merges and rebases work and how they can go wrong (for instance this list of what can go wrong with rebase)
- how exactly your colleagues are using git, and what guidelines you should be following to work with them successfully
- how pushing/pulling code from other repositories works
- how to handle merge conflicts
Hopefully this will be useful to some folks out there though.
some other references:
- the book building git by James Coglan (side note: looks like there’s a 50% off discount for the rest of January)
- git from the inside out by mary rose cook
- the official git repository layout docs
Do we think of git commits as diffs, snapshots, and/or histories?
Hello! I’ve been extremely slowly trying to figure how to explain every core concept in Git (commits! branches! remotes! the staging area!) and commits have been surprisingly tricky.
Understanding how git commits are implemented feels pretty straightforward to me (those are facts! I can look it up!), but it’s been much harder to figure out how other people think about commits. So like I’ve been doing a lot recently, I went on Mastodon and started asking some questions.
how do people think about Git commits?
I did a highly unscientific poll on Mastodon about how people think about Git commits: is it a snapshot? is it a diff? is it a list of every previous commit? (Of course it’s legitimate to think about it as all three, but I was curious about the primary way people think about Git commits). Here it is:
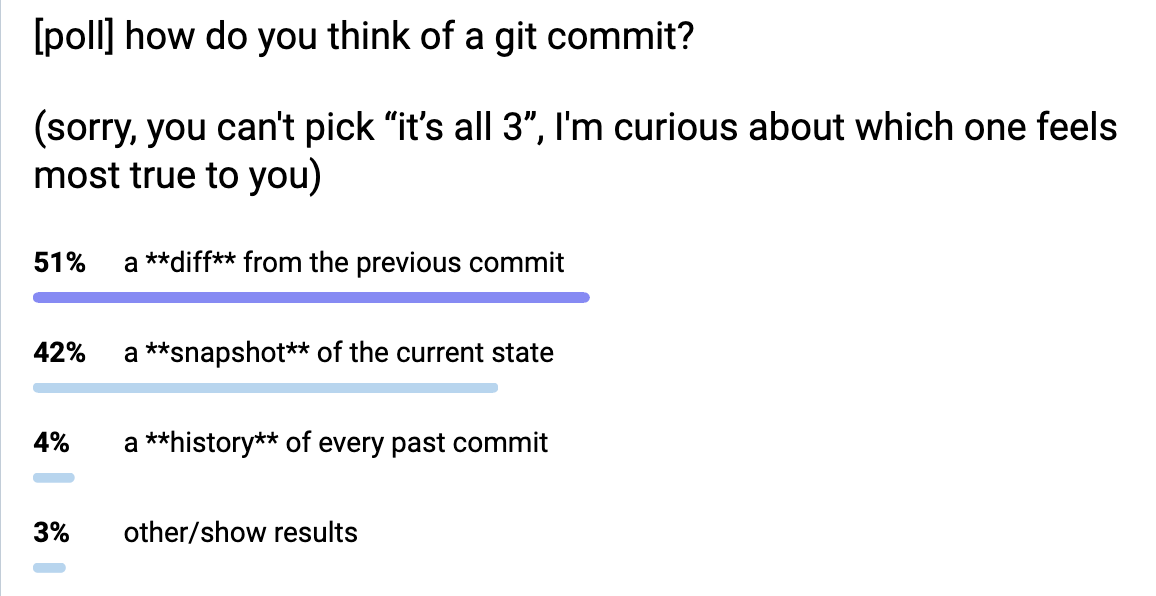
The results were:
- 51% diff
- 42% snapshot
- 4% history of every previous commit
- 3% “other”
I was really surprised that it was so evenly split between diffs and snapshots. People also made some interesting kind of contradictory statements like “in my mind a commit is a diff, but I think it’s actually implemented as a snapshot” and “in my mind a commit is a snapshot, but I think it’s actually implemented as a diff”. We’ll talk more about how a commit is actually implemented later in the post.
Before we go any further: when we say “a diff” or “a snapshot”, what does that mean?
what’s a diff?
What I mean by a diff is probably obvious: it’s what you get when you run git show COMMIT_ID. For example here’s a typo fix from rbspy:
diff --git a/src/ui/summary.rs b/src/ui/summary.rs
index 5c4ff9c..3ce9b3b 100644
--- a/src/ui/summary.rs
+++ b/src/ui/summary.rs
@@ -160,7 +160,7 @@ mod tests {
";
let mut buf: Vec<u8> = Vec::new();
- stats.write(&mut buf).expect("Callgrind write failed");
+ stats.write(&mut buf).expect("summary write failed");
let actual = String::from_utf8(buf).expect("summary output not utf8");
assert_eq!(actual, expected, "Unexpected summary output");
}
You can see it on GitHub here: https://github.com/rbspy/rbspy/commit/24ad81d2439f9e63dd91cc1126ca1bb5d3a4da5b
what’s a snapshot?
When I say “a snapshot”, what I mean is “all the files that you get when you
run git checkout COMMIT_ID”.
Git often calls the list of files for a commit a “tree” (as in “directory tree”), and you can see all of the files for the above example commit here on GitHub:
https://github.com/rbspy/rbspy/tree/24ad81d2439f9e63dd91cc1126ca1bb5d3a4da5b (it’s /tree/ instead of /commit/)
is “how Git implements it” really the right way to explain it?
Probably the most common piece of advice I hear related to learning Git is “just learn how Git represents things internally, and everything will make sense”. I obviously find this perspective extremely appealing (if you’ve spent any time reading this blog, you know I love thinking about how things are implemented internally).
But as a strategy for teaching Git, it hasn’t been as successful as I’d hoped! Often I’ve eagerly started explaining “okay, so git commits are snapshots with a pointer to their parent, and then a branch is a pointer to a commit, and…”, but the person I’m trying to help will tell me that they didn’t really find that explanation that useful at all and they still don’t get it. So I’ve been considering other options.
Let’s talk about the internals a bit anyway though.
how git represents commits internally: snapshots
Internally, git represents commits as snapshots (it stores the “tree” of the current version of every file). I wrote about this in In a git repository, where do your files live?, but here’s a very quick summary of what the internal format looks like.
Here’s how a commit is represented:
$ git cat-file -p 24ad81d2439f9e63dd91cc1126ca1bb5d3a4da5b
tree e197a79bef523842c91ee06fa19a51446975ec35
parent 26707359cdf0c2db66eb1216bf7ff00eac782f65
author Adam Jensen <adam@acj.sh> 1672104452 -0500
committer Adam Jensen <adam@acj.sh> 1672104890 -0500
Fix typo in expectation message
and here’s what we get when we look at this tree object: a list of every file / subdirectory in the repository’s root directory as of that commit:
$ git cat-file -p e197a79bef523842c91ee06fa19a51446975ec35
040000 tree 2fcc102acd27df8f24ddc3867b6756ac554b33ef .cargo
040000 tree 7714769e97c483edb052ea14e7500735c04713eb .github
100644 blob ebb410eb8266a8d6fbde8a9ffaf5db54a5fc979a .gitignore
100644 blob fa1edfb73ce93054fe32d4eb35a5c4bee68c5bf5 ARCHITECTURE.md
100644 blob 9c1883ee31f4fa8b6546a7226754cfc84ada5726 CODE_OF_CONDUCT.md
100644 blob 9fac1017cb65883554f821914fac3fb713008a34 CONTRIBUTORS.md
100644 blob b009175dbcbc186fb8066344c0e899c3104f43e5 Cargo.lock
100644 blob 94b87cd2940697288e4f18530c5933f3110b405b Cargo.toml
What this means is that checking out a Git commit is always fast: it’s just as easy for Git to check out a commit from yesterday as it is to check out a commit from 1 million commits ago. Git never has to replay 10000 diffs to figure out the current state or anything, because commits just aren’t stored as diffs.
snapshots are compressed using packfiles
I just said that Git commits are snapshots, but when someone says “I think of git commits as a snapshot, but I think internally they’re actually diffs”, that’s actually kind of true too! Git commits are not represented as diffs in the sense you’re probably used to (they’re not represented on disk as a diff from the previous commit), but the basic intuition that if you’re editing a 10,000 lines 500 times, it would be inefficient to store 500 copies of that file is right.
Git does have a way of storing files as differences from other ways. This is
called “packfiles” and periodically git will do a garbage collection and
compress your data into packfiles to save disk space. When you git clone a
repository git will also compress the data.
I don’t have space for a full explanation of how packfiles work in this post (Aditya Mukerjee’s Unpacking Git packfiles is my favourite writeup of how they work). But here’s a quick summary of my understanding of how deltas work and how they’re different from diffs:
- Objects are stored as a reference to an “original file”, plus a “delta”
- the delta has a bunch of instructions like “read bytes 0 to 100, then insert bytes ‘hello there’, then read bytes 120 to 200”. It cobbles together bytes from the original plus new text. So there’s no notion of “deletions”, just copies and additions.
- I think there are less layers of deltas: I don’t know how to actually check how many layers of deltas Git actually had to go through to get a given object, but my impression is that it usually isn’t very many. Probably less than 10? I’d love to know how to actually find this out though.
- The “original file” isn’t necessarily from the previous commit, it could be anything. Maybe it could even be from a later commit? I’m not sure about that.
- There’s no “right” algorithm for how to compute deltas, Git just has some approximate heuristics
what actually happens when you do a diff is kind of weird
When I run git show SOME_COMMIT to look at the diff for a commit, what
actually happens is kind of counterintuitive. My understanding is:
- git looks in the packfiles and applies deltas to reconstruct the tree for that commit and for its parent.
- git diffs the two directory trees (the current commit’s tree, and the parent commit’s tree). Usually this is pretty fast because almost all of the files are exactly the same, so git can just compare the hashes of the identical files and do nothing almost all of the time.
- finally git shows me the diff
So it takes deltas, turns them into a snapshot, and then calculates a diff. It feels a little weird because it starts with a diff-like-thing and ends up with another diff-like-thing, but the deltas and diffs are actually totally different so it makes sense.
That said, the way I think of it is that git stores commits as snapshots and packfiles are just an implementation detail to save disk space and make clones faster. I’ve never actually needed to know how packfiles work for any practical reason, but it does help me understand how it’s possible for git commits to be snapshots without using way too much disk space.
a “wrong” mental model for git: commits are diffs
I think a pretty common “wrong” mental model for Git is:
- commits are stored as diffs from the previous commit (plus a pointer to the parent commit(s) and an author and message).
- to get the current state for a commit, Git starts at the beginning and replays all the previous commits
This model is obviously not true (in real life, commits are stored as snapshots, and diffs are calculated from those snapshots), but it seems very useful and coherent to me! It gets a little weird with merge commits, but maybe you just say it’s stored as a diff from the first parent of the merge.
I think wrong mental models are often extremely useful, and this one doesn’t seem very problematic to me for every day Git usage. I really like that it makes the thing that we deal with the most often (the diff) the most fundamental – it seems really intuitive to me.
I’ve also been thinking about other “wrong” mental models you can have about Git which seem pretty useful like:
- commit messages can be edited (they can’t really, actually you make a copy of the commit with a new message, and the old commit continues to exist)
- commits can be moved to have a different base (similarly, they’re copied)
I feel like there’s a whole very coherent “wrong” set of ideas you can have about git that are pretty well supported by Git’s UI and not very problematic most of the time. I think it can get messy when you want to undo a change or when something goes wrong though.
some advantages of “commit as diff”
Personally even though I know that in Git commits are snapshots, I probably think of them as diffs most of the time, because:
- most of the time I’m concerned with the change I’m making – if I’m just changing 1 line of code, obviously I’m mostly thinking about just that 1 line of code and not the entire current state of the codebase
- when you click on a Git commit on GitHub or use
git show, you see the diff, so it’s just what I’m used to seeing - I use rebase a lot, which is all about replaying diffs
some advantages of “commit as snapshot”
I also think about commits as snapshots sometimes though, because:
- git often gets confused about file moves: sometimes if I move a file and edit
it, Git can’t recognize that it was moved and instead will show it as
“deleted old.py, added new.py”. This is because git only stores snapshots, so
when it says “moved old.py -> new.py”, it’s just guessing because the
contents of
old.pyandnew.pyare similar. - it’s conceptually much easier to think about what
git checkout COMMIT_IDis doing (the idea of replaying 10000 commits just feels stressful to me) - merge commits kind of make more sense to me as snapshots, because the merged commit can actually be literally anything (it’s just a new snapshot!). It helps me understand why you can make arbitrary changes when you’re resolving a merge conflict, and why it’s so important to be careful about conflict resolution.
some other ways to think about commits
Some folks in the Mastodon replies also mentioned:
- “extra” out-of-band information about the commit, like an email or a GitHub pull request or just a conversation you had with a coworker
- thinking about a diff as a “before state + after state”
- and of course, that lots of people think of commits in lots of different ways depending on the situation
some other words people use to talk about commits might be less ambiguous:
- “revision” (seems more like a snapshot)
- “patch” (seems more like a diff)
that’s all for now!
It’s been very difficult for me to get a sense of what different mental models people have for git. It’s especially tricky because people get really into policing “wrong” mental models even though those “wrong” models are often really useful, so folks are reluctant to share their “wrong” ideas for fear of some Git Explainer coming out of the woodwork to explain to them why they’re Wrong. (these Git Explainers are often well-intentioned, but it still has a chilling effect either way)
But I’ve been learning a lot! I still don’t feel totally clear about how I want to talk about commits, but we’ll get there eventually.
Thanks to Marco Rogers, Marie Flanagan, and everyone on Mastodon for talking to me about git commits.
Some notes on NixOS
Hello! Over the holidays I decided it might be fun to run NixOS on one of my servers, as part of my continuing experiments with Nix.
My motivation for this was that previously I was using Ansible to provision the server, but then I’d ad hoc installed a bunch of stuff on the server in a chaotic way separately from Ansible, so in the end I had no real idea of what was on that server and it felt like it would be a huge pain to recreate it if I needed to.
This server just runs a few small personal Go services, so it seemed like a good candidate for experimentation.
I had trouble finding explanations of how to set up NixOS and I needed to cobble together instructions from a bunch of different places, so here’s a very short summary of what worked for me.
why NixOS instead of Ansible?
I think the reason NixOS feels more reliable than Ansible to me is that NixOS is the operating system. It has full control over all your users and services and packages, and so it’s easier for it to reliably put the system into the state you want it to be in.
Because Nix has so much control over the OS, I think that if I tried to make
any ad-hoc changes at all to my Nix system, Nix would just blow them away the
next time I ran nixos-rebuild. But with Ansible, Ansible only controls a few
small parts of the system (whatever I explicitly tell it to manage), so it’s
easy to make changes outside Ansible.
That said, here’s what I did to set up NixOS on my server and run a Go service on it.
step 1: install NixOS with nixos-infect
To install NixOS, I created a new Hetzner instance running Ubuntu, and then ran nixos-infect on it to convert the Ubuntu installation into a NixOS install, like this:
curl https://raw.githubusercontent.com/elitak/nixos-infect/master/nixos-infect | PROVIDER=hetznercloud NIX_CHANNEL=nixos-23.11 bash 2>&1 | tee /tmp/infect.log
I originally tried to do this on DigitalOcean, but it didn’t work for some reason, so I went with Hetzner instead and that worked.
This isn’t the only way to install NixOS (this wiki page lists options for setting up NixOS cloud servers), but it seemed to work. It’s possible that there are problems with installing that way that I don’t know about though. It does feel like using an ISO is probably better because that way you don’t have to do this transmogrification of Ubuntu into NixOS.
I definitely skipped Step 1 in nixos-infect’s README (“Read and understand
the script”), but I didn’t feel too worried because I was running it on a
new instance and I figured that if something went wrong I’d just delete it.
step 2: copy the generated Nix configuration
Next I needed to copy the generated Nix configuration to a new local Git repository, like this:
scp root@SERVER_IP:/etc/nixos/* .
This copied 3 files: configuration.nix, hardware-configuration.nix, and networking.nix. configuration.nix is the main file. I didn’t touch anything in hardware-configuration.nix or networking.nix.
step 3: create a flake
I created a flake to wrap configuration.nix. I don’t remember why I did this
(I have some idea of what the advantages of flakes are, but it’s not clear to
me if any of them are actually relevant in this case) but it seems to work. Here’s
my flake.nix:
{ inputs.nixpkgs.url = "github:NixOS/nixpkgs/23.11";
outputs = { nixpkgs, ... }: {
nixosConfigurations.default = nixpkgs.lib.nixosSystem {
system = "x86_64-linux";
modules = [ ./configuration.nix ];
};
};
}
The main gotcha about flakes that I needed to remember here was that you need
to git add every .nix file you create otherwise Nix will pretend it doesn’t
exist.
The rules about git and flakes seem to be:
- you do need to
git addyour files - you don’t need to commit your changes
- unstaged changes to files are also fine, as long as the file has been
git added
These rules feel very counterintuitive to me (why require that you git add
files but allow unstaged changes?) but that’s how it works. I think it might be
an optimization because Nix has to copy all your .nix files to the Nix store for some
reason, so only copying files that have been git added makes the copy faster. There’s a GitHub issue tracking it here so maybe the way this works will change at some point.
step 4: figure out how to deploy my configuration
Next I needed to figure out how to deploy changes to my configuration. There are a bunch
of tools for this, but I found the blog post Announcing nixos-rebuild: a “new” deployment tool for NixOS
that said you can just use the built-in nixos-rebuild, which has
--target-host and --build-host options so that you can specify which host
to build on and deploy to, so that’s what I did.
I wanted to be able to get Go repositories and build the Go code on the target host, so I created a bash script that runs this command:
nixos-rebuild switch --fast --flake .#default --target-host my-server --build-host my-server --option eval-cache false
Making --target-host and --build-host the same machine is certainly not
something I would do for a Serious Production Machine, but this server is
extremely unimportant so it’s fine.
This --option eval-cache false is because Nix kept not showing me my errors
because they were cached – it would just say error: cached failure of attribute 'nixosConfigurations.default.config.system.build.toplevel' instead
of showing me the actual error message. Setting --option eval-cache false
turned off caching so that I could see the error messages.
Now I could run bash deploy.sh on my laptop and deploy my configuration to the server! Hooray!
step 5: update my ssh config
I also needed to set up a my-server host in my ~/.ssh/config. I set up SSH
agent forwarding so that the server could download the private Git repositories
it needed to access.
Host my-server
Hostname MY_IP_HERE
User root
Port 22
ForwardAgent yes
AddKeysToAgent yes
step 6: set up a Go service
The thing I found the hardest was to figure out how to compile and configure a Go web service to run on the server. The norm seems to be to define your package and define your service’s configuration in 2 different files, but I didn’t feel like doing that – I wanted to do it all in one file. I couldn’t find a simple example of how to do this, so here’s what I did.
I’ve replaced the actual repository name with my-service because it’s a
private repository and you can’t run it anyway.
{ pkgs ? (import <nixpkgs> { }), lib, stdenv, ... }:
let myservice = pkgs.callPackage pkgs.buildGoModule {
name = "my-service";
src = fetchGit {
url = "git@github.com:jvns/my-service.git";
rev = "efcc67c6b0abd90fb2bd92ef888e4bd9c5c50835"; # put the right git sha here
};
vendorHash = "sha256-b+mHu+7Fge4tPmBsp/D/p9SUQKKecijOLjfy9x5HyEE"; # nix will complain about this and tell you the right value
}; in {
services.caddy.virtualHosts."my-service.example.com".extraConfig = ''
reverse_proxy localhost:8333
'';
systemd.services.my-service = {
enable = true;
description = "my-service";
after = ["network.target"];
wantedBy = ["multi-user.target"];
script = "${myservice}/bin/my-service";
environment = {
DB_FILENAME = "/var/lib/my-service/db.sqlite";
};
serviceConfig = {
DynamicUser = true;
StateDirectory = "my-service"; # /var/lib/my-service
};
};
}
Then I just needed to do 2 more things:
- add
./my-service.nixto the imports section ofconfiguration.nix - add
services.caddy.enable = true;toconfiguration.nixto enable Caddy
and everything worked!!
Some notes on this service configuration file:
- I used
extraConfigto configure Caddy because I didn’t feel like learning Nix’s special Caddy syntax – I wanted to just be able to refer to the Caddy documentation directly. - I used systemd’s
DynamicUserto create a user dynamically to run the service. I’d never used this before but it seems like a great simple way to create a different user for every service without having to write a bunch of repetitive boilerplate and being really careful to choose unique UID and GIDs. The blog post Dynamic Users with systemd talks about how it works. - I used
StateDirectoryto get systemd to create a persistent directory where I could store a SQLite database. It creates a directory at/var/lib/my-service/
I’d never heard of DynamicUser or StateDirectory before Kamal told me about
them the other day but they seem like cool systemd features and I wish
I’d known about them earlier.
why Caddy?
One quick note on Caddy: I switched to Caddy a while back from nginx because it automatically sets up Let’s Encrypt certificates. I’ve only been using it for tiny hobby services, but it seems pretty great so far for that, and its configuration language is simpler too.
problem: “fetchTree requires a locked input”
One problem I ran into was this error message:
error: in pure evaluation mode, 'fetchTree' requires a locked input, at «none»:0
I found this really perplexing – what is fetchTree? What is «none»:0? What did I do wrong?
I learned 4 things from debugging this (with help from the folks in the Nix discord):
- In Nix,
fetchGitcalls an internal function calledfetchTree. So errors that sayfetchTreemight actually be referring tofetchGit. - Nix truncates long stack traces by default. Sometimes you can get more information with
--show-trace. - It seems like Nix doesn’t always give you the line number in your code which caused the error, even if you use
--show-trace. I’m not sure why this is. Some people told me this is becausefetchTreeis a built in function but – why can’t I see the line number in my nix code that called that built in function? - Like I mentioned before, you can pass
--option eval-cache falseto turn off caching so that Nix will always show you the error message instead oferror: cached failure of attribute 'nixosConfigurations.default.config.system.build.toplevel'
Ultimately the problem turned out to just be that I forgot to pass the Github
revision ID (rev = "efcc67c6b0abd90fb2bd92ef888e4bd9c5c50835";) to fetchGit
which was really easy to fix.
nix syntax is still pretty confusing to me
I still don’t really understand the nix language syntax that well, but I
haven’t felt motivated to get better at it yet – I guess learning new language
syntax just isn’t something I find fun. Maybe one day I’ll learn it. My plan
for now with NixOS is to just keep copying and pasting that my-service.nix
file above forever.
some questions I still have
I think my main outstanding questions are:
- When I run
nixos-rebuild, Nix checks that my systemd services are still working in some way. What does it check exactly? My best guess is that it checks that the systemd service starts successfully, but if the service starts and then immediately crashes, it won’t notice. - Right now to deploy a new version of one of my services, I need to manually copy and paste the Git SHA of the new revision. There’s probably a better workflow but I’m not sure what it is.
that’s all!
I really do like having all of my service configuration defined in one file, and the approach Nix takes does feel more reliable than the approach I was taking with Ansible.
I just started doing this a week ago and as with all things Nix I have no idea if I’ll end up liking it or not. It seems pretty good so far though!
I will say that I find using Nix to be very difficult and I really struggle
when debugging Nix problems (that fetchTree problem I mentioned sounds
simple, but it was SO confusing to me at the time), but I kind of like it
anyway. Maybe because I’m not using Linux on my laptop right now I miss having
linux evenings and Nix feels
like a replacement for that :)
2023: Year in review
Hello! This was my 4th year working full time on Wizard Zines! Here are a few of the things I worked on this year.
a zine!
I published How Integers and Floats Work, which I worked on with Marie.
This one started out its life as “how your computer represents things in memory”, but once we’d explained how integers and floats were represented in memory the zine was already long enough, so we just kept it to integers and floats.
This zine was fun to write: I learned about why signed integers are represented in memory the way they are, and I’m really happy with the explanation of floating point we ended up with.
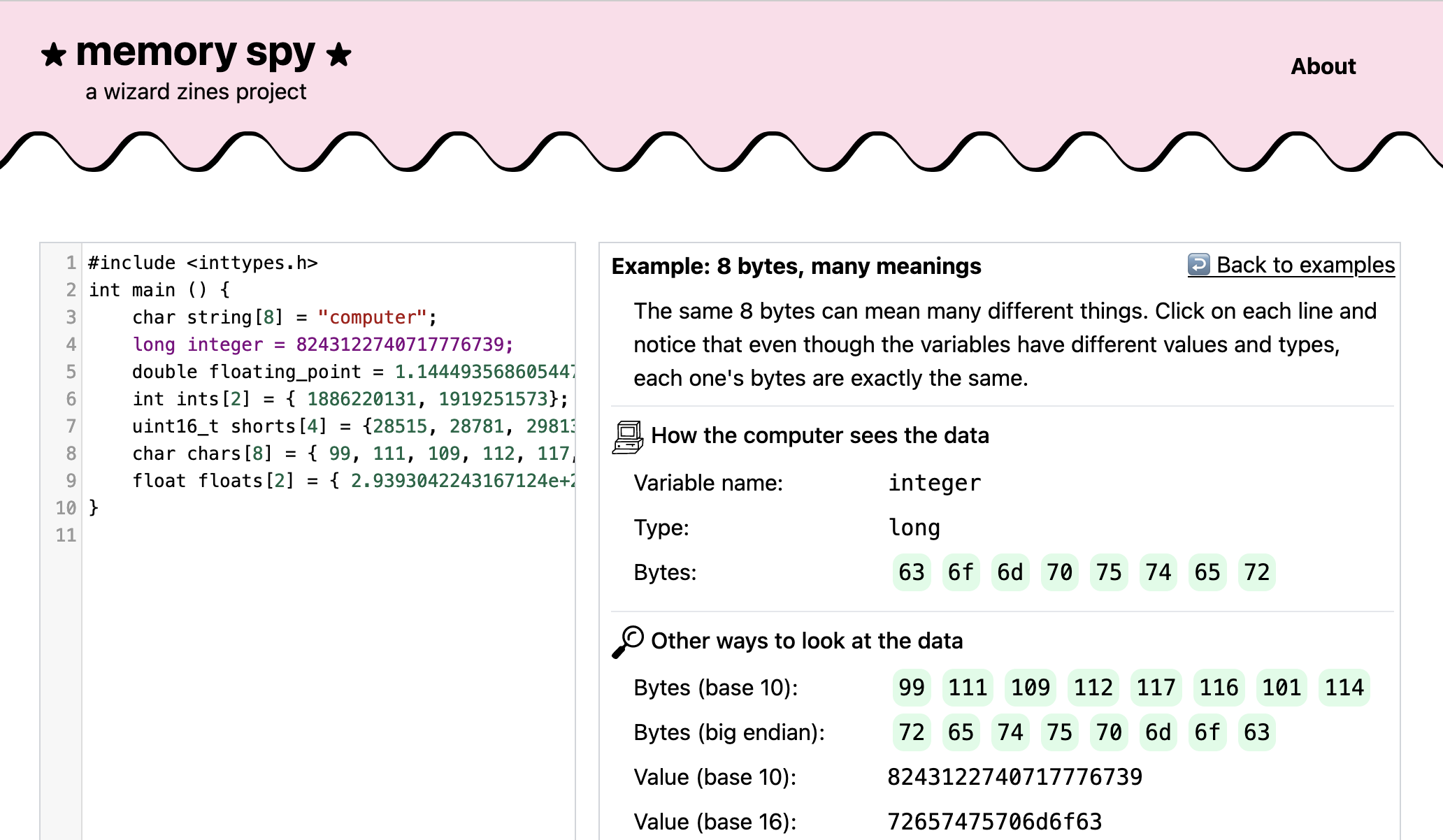
a playground: memory spy!
When explaining to people how your computer represents people in memory, I kept
wanting to open up gdb or lldb and show some example C programs and how the
variables in those C programs are represented in memory.
But gdb is kind of confusing if you’re not used to looking at it! So me and
Marie made a cute interface on top of lldb, where you can put in any C program,
click on a line, and see what the variable looks like. It’s called memory spy and here’s what it looks like:
a playground: integer exposed!
I got really obsessed with float.exposed by Bartosz Ciechanowski for seeing how floats are represented in memory. So with his permission, I made a copy of it for integers called integer.exposed.
Here’s a screenshot:
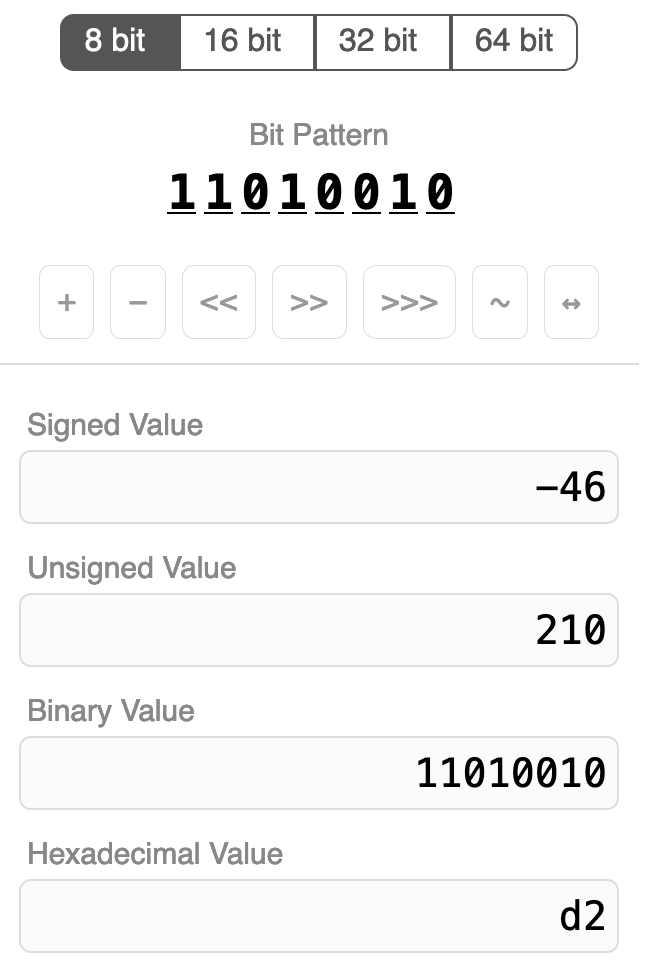
It was pretty straightforward to make (copying someone else’s design is so much easier than making your own!) but I learned a few CSS tricks from analyzing how he implemented it.
Implement DNS in a Weekend
I’ve been working on a big project to show people how to implement a working networking stack (TCP, TLS, DNS, UDP, HTTP) in 1400 lines of Python, that you can use to download a webpage using 100% your own networking code. Kind of like Nand to Tetris, but for computer networking.
This has been going VERY slowly – writing my own working shitty implementations was relatively easy (I finished that in October 2022), but writing clear tutorials that other people can follow is not.
But in March, I released the first part: Implement DNS in a Weekend. The response was really good – there are dozens of people’s implementations on GitHub, and people have implemented it in Go, C#, C, Clojure, Python, Ruby, Kotlin, Rust, Typescript, Haskell, OCaml, Elixir, Odin, and probably many more languages too. I’d like to see more implementations in less systems-y languages like vanilla JS and PHP, need to think about what I can do to encourage that.
I think “Implement IPv4 in a Weekend” might be the next one I release. It’s going to come with bonus guides to implementing ICMP and UDP too.
a talk: Making Hard Things Easy!
I gave a keynote at Strange Loop this year called Making Hard Things Easy (video + transcript), about why some things are so hard to learn and how we can make them easier. I’m really proud of how it turned out.
a lot of blog posts about Git!
In September I decided to work on a second zine about Git, focusing more on how Git works. This is one of the hardest projects I’ve ever worked on, because over the last 10 years of using it I’d completely lost sight of what’s hard about Git.
So I’ve been doing a lot of research to try to figure out why Git is hard, and I’ve been writing a lot of blog posts. So far I’ve written:
- In a git repository, where do your files live?
- Some miscellaneous git facts
- Confusing git terminology
- git rebase: what can go wrong?
- How git cherry-pick and revert use 3-way merge
- git branches: intuition & reality
- Mounting git commits as folders with NFS
What’s been most surprising so far is that I originally thought “to understand Git, people just need to learn git’s internal data model!”. But the more I talk to people about their struggles with Git, the less I think that’s true. I’ll leave it at that for now, but there’s a lot of work still to do.
some Git prototypes!
I worked on a couple of fun Git tools this year:
- git-commit-folders: a way to mount your Git commits as (read-only) folders using FUSE or NFS. This one came about because someone mentioned that they think of Git commits as being folders with old versions of the code, and it made me wonder – why can’t you just have a virtual folder for every commit? It turns out that it can and it works pretty well.
- git-oops: an experimental prototype of an
undo system for git. This one came out of me wondering “why can’t we just
have a
git undo?”. I learned a bunch of things about why that’s not easy through writing the prototype, I might write a longer blog post about it later.
I’ve been trying to put a little less pressure on myself to release software that’s Amazing and Perfect – sometimes I have an idea that I think is cool but don’t really have the time or energy to fully execute on it. So I decided to just put these both on Github in a somewhat unfinished state, so I can come back to them if later if I want. Or not!
I’m also working on another Git software project, which is a collaboration with a friend.
hired an operations manager!
This year I hired an Operations Manager for Wizard Zines! Lee is incredible and has done SO much to streamline the logistics of running the company, so that I can focus more on writing and coding. I don’t talk much about the mechanics of running the business on here, but it’s a lot and I’m very grateful to have some help.
A few of the many things Lee has made possible:
- run a Black Friday sale!
- we added a review system to the website! (it’s so nice to hear about how people loved getting zines for Christmas!)
- the store has been reorganized to be way clearer!
- we’re more consistent about sending out the new comics newsletter!
- I can take a vacation and not worry about support emails!
migrated to Mastodon!
I spent 10 years building up a Twitter presence, but with the Recent Events, I spent a lot of time in 2023 working on building up a Mastodon account. I’ve found that I’m able to have more interesting conversations about computers on Mastodon than on Twitter or Bluesky, so that’s where I’ve been spending my time. We’ve been having a lot of great discussions about Git there recently.
I’ve run into a few technical issues with Mastodon (which I wrote about at Notes on using a single-person Mastodon server) but overall I’m happy there and I’ve been spending a lot more time there than on Twitter.
some questions for 2024
one of my questions for 2022 was:
- What’s hard for developers about learning to use the Unix command line in 2022? What do I want to do about it?
Maybe I’ll work on that in 2024! Maybe not! I did make a little bit of progress on that question this year (I wrote What helps people get comfortable on the command line?).
Some other questions I’m thinking about on and off:
- Could man pages be a more useful form of documentation? Do I want to try to do anything about that?
- What format do I want to use for this “implement all of computer networking in Python” project? (is it a website? a book? is there a zine? what’s the deal?) Do I want to run workshops?
- What community guidelines do I want to have for discussions on Mastodon?
- Could I be marketing Mess With DNS (from 2021) more? How do I want to do that?
moving slowly is okay
I’ve started to come to terms with the fact that projects always just take longer than I think they will. I started working this “implement your own terrible networking stack” project in 2022, and I don’t know if I’ll finish it in 2024. I’ve been working on this Git zine since September and I still don’t completely understand why Git is hard yet. There’s another small secret project that I initally thought of 5 years ago, made a bunch of progress on this year, but am still not done with. Things take a long time and that’s okay.
As always, thanks for reading and for making it possible for me to do this weird job.