Reading List
The most recent articles from a list of feeds I subscribe to.
Some notes on upgrading Hugo
Warning: this is a post about very boring yakshaving, probably only of interest to people who are trying to upgrade Hugo from a very old version to a new version. But what are blogs for if not documenting one’s very boring yakshaves from time to time?
So yesterday I decided to try to upgrade Hugo. There’s no real reason to do this – I’ve been using Hugo version 0.40 to generate this blog since 2018, it works fine, and I don’t have any problems with it. But I thought – maybe it won’t be as hard as I think, and I kind of like a tedious computer task sometimes!
I thought I’d document what I learned along the way in case it’s useful to anyone else doing this very specific migration. I upgraded from Hugo v0.40 (from 2018) to v0.135 (from 2024).
Here are most of the changes I had to make:
change 1: template "theme/partials/thing.html is now partial thing.html
I had to replace a bunch of instances of {{ template "theme/partials/header.html" . }} with {{ partial "header.html" . }}.
This happened in v0.42:
We have now virtualized the filesystems for project and theme files. This makes everything simpler, faster and more powerful. But it also means that template lookups on the form {{ template “theme/partials/pagination.html” . }} will not work anymore. That syntax has never been documented, so it’s not expected to be in wide use.
change 2: .Data.Pages is now site.RegularPages
This seems to be discussed in the release notes for 0.57.2
I just needed to replace .Data.Pages with site.RegularPages in the template on the homepage as well as in my RSS feed template.
change 3: .Next and .Prev got flipped
I had this comment in the part of my theme where I link to the next/previous blog post:
“next” and “previous” in hugo apparently mean the opposite of what I’d think they’d mean intuitively. I’d expect “next” to mean “in the future” and “previous” to mean “in the past” but it’s the opposite
It looks they changed this in ad705aac064 so that “next” actually is in the future and “prev” actually is in the past. I definitely find the new behaviour more intuitive.
downloading the Hugo changelogs with a script
Figuring out why/when all of these changes happened was a little difficult. I ended up hacking together a bash script to download all of the changelogs from github as text files, which I could then grep to try to figure out what happened. It turns out it’s pretty easy to get all of the changelogs from the GitHub API.
So far everything was not so bad – there was also a change around taxonomies that’s I can’t quite explain, but it was all pretty manageable, but then we got to the really tough one: the markdown renderer.
change 4: the markdown renderer (blackfriday -> goldmark)
The blackfriday markdown renderer (which was previously the default) was removed in v0.100.0. This seems pretty reasonable:
It has been deprecated for a long time, its v1 version is not maintained anymore, and there are many known issues. Goldmark should be a mature replacement by now.
Fixing all my Markdown changes was a huge pain – I ended up having to update 80 different Markdown files (out of 700) so that they would render properly, and I’m not totally sure
why bother switching renderers?
The obvious question here is – why bother even trying to upgrade Hugo at all if I have to switch Markdown renderers? My old site was running totally fine and I think it wasn’t necessarily a good use of time, but the one reason I think it might be useful in the future is that the new renderer (goldmark) uses the CommonMark markdown standard, which I’m hoping will be somewhat more futureproof. So maybe I won’t have to go through this again? We’ll see.
Also it turned out that the new Goldmark renderer does fix some problems I had (but didn’t know that I had) with smart quotes and how lists/blockquotes interact.
finding all the Markdown problems: the process
The hard part of this Markdown change was even figuring out what changed. Almost all of the problems (including #2 and #3 above) just silently broke the site, they didn’t cause any errors or anything. So I had to diff the HTML to hunt them down.
Here’s what I ended up doing:
- Generate the site with the old version, put it in
public_old - Generate the new version, put it in
public - Diff every single HTML file in
public/andpublic_oldwith this diff.sh script and put the results in adiffs/folder - Run variations on
find diffs -type f | xargs cat | grep -C 5 '(31m|32m)' | less -rover and over again to look at every single change until I found something that seemed wrong - Update the Markdown to fix the problem
- Repeat until everything seemed okay
(the grep 31m|32m thing is searching for red/green text in the diff)
This was very time consuming but it was a little bit fun for some reason so I kept doing it until it seemed like nothing too horrible was left.
the new markdown rules
Here’s a list of every type of Markdown change I had to make. It’s very possible these are all extremely specific to me but it took me a long time to figure them all out so maybe this will be helpful to one other person who finds this in the future.
4.1: mixing HTML and markdown
This doesn’t work anymore (it doesn’t expand the link):
<small>
[a link](https://example.com)
</small>
I need to do this instead:
<small>
[a link](https://example.com)
</small>
This works too:
<small> [a link](https://example.com) </small>
4.2: << is changed into «
I didn’t want this so I needed to configure:
markup:
goldmark:
extensions:
typographer:
leftAngleQuote: '<<'
rightAngleQuote: '>>'
4.3: nested lists sometimes need 4 space indents
This doesn’t render as a nested list anymore if I only indent by 2 spaces, I need to put 4 spaces.
1. a
* b
* c
2. b
The problem is that the amount of indent needed depends on the size of the list markers. Here’s a reference in CommonMark for this.
4.4: blockquotes inside lists work better
Previously the > quote here didn’t render as a blockquote, and with the new renderer it does.
* something
> quote
* something else
I found a bunch of Markdown that had been kind of broken (which I hadn’t noticed) that works better with the new renderer, and this is an example of that.
Lists inside blockquotes also seem to work better.
4.5: headings inside lists
Previously this didn’t render as a heading, but now it does. So I needed to
replace the # with #.
* # passengers: 20
4.6: + or 1) at the beginning of the line makes it a list
I had something which looked like this:
`1 / (1
+ exp(-1)) = 0.73`
With Blackfriday it rendered like this:
<p><code>1 / (1
+ exp(-1)) = 0.73</code></p>
and with Goldmark it rendered like this:
<p>`1 / (1</p>
<ul>
<li>exp(-1)) = 0.73`</li>
</ul>
Same thing if there was an accidental 1) at the beginning of a line, like in this Markdown snippet
I set up a small Hadoop cluster (1 master, 2 workers, replication set to
1) on
To fix this I just had to rewrap the line so that the + wasn’t the first character.
The Markdown is formatted this way because I wrap my Markdown to 80 characters a lot and the wrapping isn’t very context sensitive.
4.7: no more smart quotes in code blocks
There were a bunch of places where the old renderer (Blackfriday) was doing
unwanted things in code blocks like replacing ... with … or replacing
quotes with smart quotes. I hadn’t realized this was happening and I was very
happy to have it fixed.
4.8: better quote management
The way this gets rendered got better:
"Oh, *interesting*!"
- old: “Oh, interesting!“
- new: “Oh, interesting!”
Before there were two left smart quotes, now the quotes match.
4.9: images are no longer wrapped in a p tag
Previously if I had an image like this:
<img src="https://jvns.ca/images/rustboot1.png">
it would get wrapped in a <p> tag, now it doesn’t anymore. I dealt with this
just by adding a margin-bottom: 0.75em to images in the CSS, hopefully
that’ll make them display well enough.
4.10: <br> is now wrapped in a p tag
Previously this wouldn’t get wrapped in a p tag, but now it seems to:
<br><br>
I just gave up on fixing this though and resigned myself to maybe having some extra space in some cases. Maybe I’ll try to fix it later if I feel like another yakshave.
4.11: some more goldmark settings
I also needed to
- turn off code highlighting (because it wasn’t working properly and I didn’t have it before anyway)
- use the old “blackfriday” method to generate heading IDs so they didn’t change
- allow raw HTML in my markdown
Here’s what I needed to add to my config.yaml to do all that:
markup:
highlight:
codeFences: false
goldmark:
renderer:
unsafe: true
parser:
autoHeadingIDType: blackfriday
Maybe I’ll try to get syntax highlighting working one day, who knows. I might prefer having it off though.
a little script to compare blackfriday and goldmark
I also wrote a little program to compare the Blackfriday and Goldmark output for various markdown snippets, here it is in a gist.
It’s not really configured the exact same way Blackfriday and Goldmark were in my Hugo versions, but it was still helpful to have to help me understand what was going on.
a quick note on maintaining themes
My approach to themes in Hugo has been:
- pay someone to make a nice design for the site (for example wizardzines.com was designed by Melody Starling)
- use a totally custom theme
- commit that theme to the same Github repo as the site
So I just need to edit the theme files to fix any problems. Also I wrote a lot of the theme myself so I’m pretty familiar with how it works.
Relying on someone else to keep a theme updated feels kind of scary to me, I think if I were using a third-party theme I’d just copy the code into my site’s github repo and then maintain it myself.
which static site generators have better backwards compatibility?
I asked on Mastodon if anyone had used a static site generator with good backwards compatibility.
The main answers seemed to be Jekyll and 11ty. Several people said they’d been using Jekyll for 10 years without any issues, and 11ty says it has stability as a core goal.
I think a big factor in how appealing Jekyll/11ty are is how easy it is for you to maintain a working Ruby / Node environment on your computer: part of the reason I stopped using Jekyll was that I got tired of having to maintain a working Ruby installation. But I imagine this wouldn’t be a problem for a Ruby or Node developer.
Several people said that they don’t build their Jekyll site locally at all – they just use GitHub Pages to build it.
that’s it!
Overall I’ve been happy with Hugo – I started using it because it had fast build times and it was a static binary, and both of those things are still extremely useful to me. I might have spent 10 hours on this upgrade, but I’ve probably spent 1000+ hours writing blog posts without thinking about Hugo at all so that seems like an extremely reasonable ratio.
I find it hard to be too mad about the backwards incompatible changes, most of
them were quite a long time ago, Hugo does a great job of making their old
releases available so you can use the old release if you want, and the most
difficult one is removing support for the blackfriday Markdown renderer in
favour of using something CommonMark-compliant which seems pretty reasonable to
me even if it is a huge pain.
But it did take a long time and I don’t think I’d particularly recommend moving 700 blog posts to a new Markdown renderer unless you’re really in the mood for a lot of computer suffering for some reason.
The new renderer did fix a bunch of problems so I think overall it might be a good thing, even if I’ll have to remember to make 2 changes to how I write Markdown (4.1 and 4.3).
Also I’m still using Hugo 0.54 for https://wizardzines.com so maybe these notes will be useful to Future Me if I ever feel like upgrading Hugo for that site.
Hopefully I didn’t break too many things on the blog by doing this, let me know if you see anything broken!
Terminal colours are tricky
Yesterday I was thinking about how long it took me to get a colorscheme in my terminal that I was mostly happy with (SO MANY YEARS), and it made me wonder what about terminal colours made it so hard.
So I asked people on Mastodon what problems they’ve run into with colours in the terminal, and I got a ton of interesting responses! Let’s talk about some of the problems and a few possible ways to fix them.
problem 1: blue on black
One of the top complaints was “blue on black is hard to read”. Here’s an
example of that: if I open Terminal.app, set the background to black, and run
ls, the directories are displayed in a blue that isn’t that easy to read:

To understand why we’re seeing this blue, let’s talk about ANSI colours!
the 16 ANSI colours
Your terminal has 16 numbered colours – black, red, green, yellow, blue, magenta, cyan, white, and “bright” version of each of those.
Programs can use them by printing out an “ANSI escape code” – for example if you want to see each of the 16 colours in your terminal, you can run this Python program:
def color(num, text):
return f"\033[38;5;{num}m{text}\033[0m"
for i in range(16):
print(color(i, f"number {i:02}"))
what are the ANSI colours?
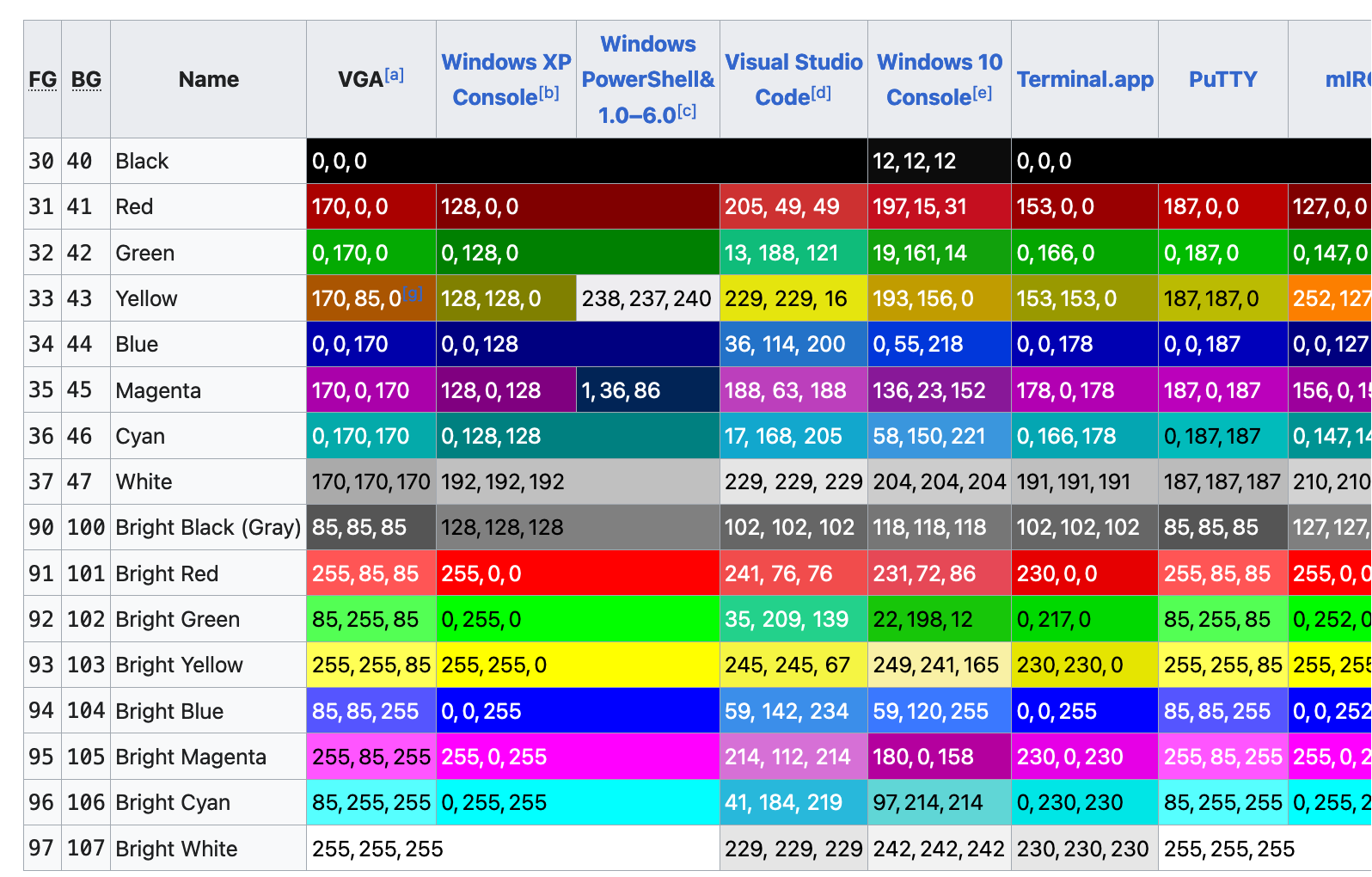
This made me wonder – if blue is colour number 5, who decides what hex color that should correspond to?
The answer seems to be “there’s no standard, terminal emulators just choose colours and it’s not very consistent”. Here’s a screenshot of a table from Wikipedia, where you can see that there’s a lot of variation:
problem 1.5: bright yellow on white
Bright yellow on white is even worse than blue on black, here’s what I get in a terminal with the default settings:

That’s almost impossible to read (and some other colours like light green cause similar issues), so let’s talk about solutions!
two ways to reconfigure your colours
If you’re annoyed by these colour contrast issues (or maybe you just think the default ANSI colours are ugly), you might think – well, I’ll just choose a different “blue” and pick something I like better!
There are two ways you can do this:
Way 1: Configure your terminal emulator: I think most modern terminal emulators have a way to reconfigure the colours, and some of them even come with some preinstalled themes that you might like better than the defaults.
Way 2: Run a shell script: There are ANSI escape codes that you can print
out to tell your terminal emulator to reconfigure its colours. Here’s a shell script that does that,
from the base16-shell project.
You can see that it has a few different conventions for changing the colours –
I guess different terminal emulators have different escape codes for changing
their colour palette, and so the script is trying to pick the right style of
escape code based on the TERM environment variable.
what are the pros and cons of the 2 ways of configuring your colours?
I prefer to use the “shell script” method, because:
- if I switch terminal emulators for some reason, I don’t need to a different configuration system, my colours still Just Work
- I use base16-shell with base16-vim to make my vim colours match my terminal colours, which is convenient
some advantages of configuring colours in your terminal emulator:
- if you use a popular terminal emulator, there are probably a lot more nice terminal themes out there that you can choose from
- not all terminal emulators support the “shell script method”, and even if they do, the results can be a little inconsistent
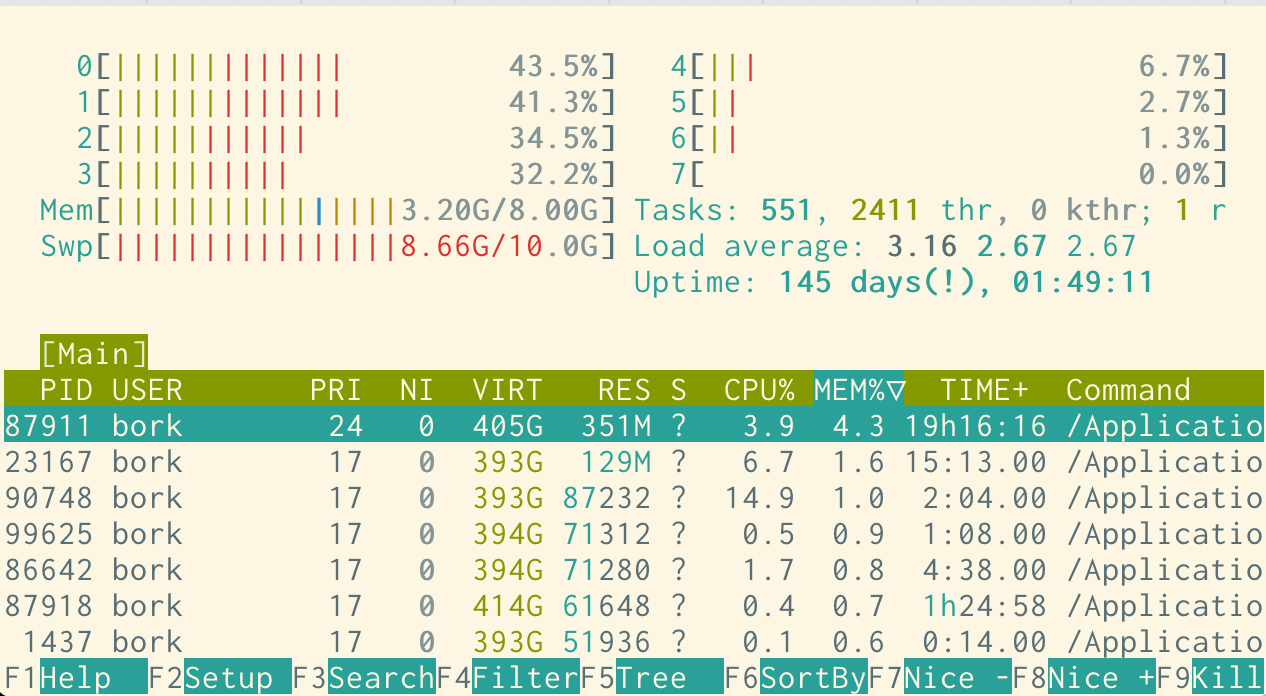
This is what my shell has looked like for probably the last 5 years (using the
solarized light base16 theme), and I’m pretty happy with it. Here’s htop:
Okay, so let’s say you’ve found a terminal colorscheme that you like. What else can go wrong?
problem 2: programs using 256 colours
Here’s what some output of fd, a find alternative, looks like in my
colorscheme:

The contrast is pretty bad here, and I definitely don’t have that lime green in my normal colorscheme. What’s going on?
We can see what color codes fd is using using the unbuffer program to
capture its output including the color codes:
$ unbuffer fd . > out
$ vim out
^[[38;5;48mbad-again.sh^[[0m
^[[38;5;48mbad.sh^[[0m
^[[38;5;48mbetter.sh^[[0m
out
^[[38;5;48 means “set the foreground color to color 48”. Terminals don’t
only have 16 colours – many terminals these days actually have 3 ways of
specifying colours:
- the 16 ANSI colours we already talked about
- an extended set of 256 colours
- a further extended set of 24-bit hex colours, like
#ffea03
So fd is using one of the colours from the extended 256-color set. bat (a
cat alternative) does something similar – here’s what it looks like by
default in my terminal.

This looks fine though and it really seems like it’s trying to work well with a variety of terminal themes.
some newer tools seem to have theme support
I think it’s interesting that some of these newer terminal tools (fd, cat,
delta, and probably more) have support for arbitrary custom themes. I guess
the downside of this approach is that the default theme might clash with your
terminal’s background, but the upside is that it gives you a lot more control
over theming the tool’s output than just choosing 16 ANSI colours.
I don’t really use bat, but if I did I’d probably use bat --theme ansi to
just use the ANSI colours that I have set in my normal terminal colorscheme.
problem 3: the grays in Solarized
A bunch of people on Mastodon mentioned a specific issue with grays in the Solarized theme: when I list a directory, the base16 Solarized Light theme looks like this:

but iTerm’s default Solarized Light theme looks like this:

This is because in the iTerm theme (which is the original Solarized design), colors 9-14 (the “bright blue”, “bright
red”, etc) are mapped to a series of grays, and when I run ls, it’s trying to
use those “bright” colours to color my directories and executables.
My best guess for why the original Solarized theme is designed this way is to make the grays available to the vim Solarized colorscheme.
I’m pretty sure I prefer the modified base16 version I use where the “bright” colours are actually colours instead of all being shades of gray though. (I didn’t actually realize the version I was using wasn’t the “original” Solarized theme until I wrote this post)
In any case I really love Solarized and I’m very happy it exists so that I can use a modified version of it.
problem 4: a vim theme that doesn’t match the terminal background
If I my vim theme has a different background colour than my terminal theme, I get this ugly border, like this:
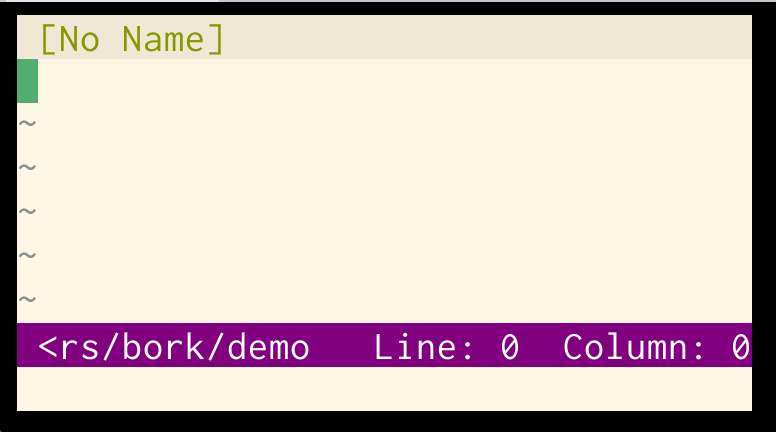
This one is a pretty minor issue though and I think making your terminal background match your vim background is pretty straightforward.
problem 5: programs setting a background color
A few people mentioned problems with terminal applications setting an unwanted background colour, so let’s look at an example of that.
Here ngrok has set the background to color #16 (“black”), but the
base16-shell script I use sets color 16 to be bright orange, so I get this,
which is pretty bad:

I think the intention is for ngrok to look something like this:

I think base16-shell sets color #16 to orange (instead of black)
so that it can provide extra colours for use by base16-vim.
This feels reasonable to me – I use base16-vim in the terminal, so I guess I’m
using that feature and it’s probably more important to me than ngrok (which I
rarely use) behaving a bit weirdly.
This particular issue is a maybe obscure clash between ngrok and my colorschem, but I think this kind of clash is pretty common when a program sets an ANSI background color that the user has remapped for some reason.
a nice solution to contrast issues: “minimum contrast”
A bunch of terminals (iTerm2, tabby, kitty’s text_fg_override_threshold, and folks tell me also Ghostty and Windows Terminal) have a “minimum contrast” feature that will automatically adjust colours to make sure they have enough contrast.
Here’s an example from iTerm. This ngrok accident from before has pretty bad contrast, I find it pretty difficult to read:
With “minimum contrast” set to 40 in iTerm, it looks like this instead:
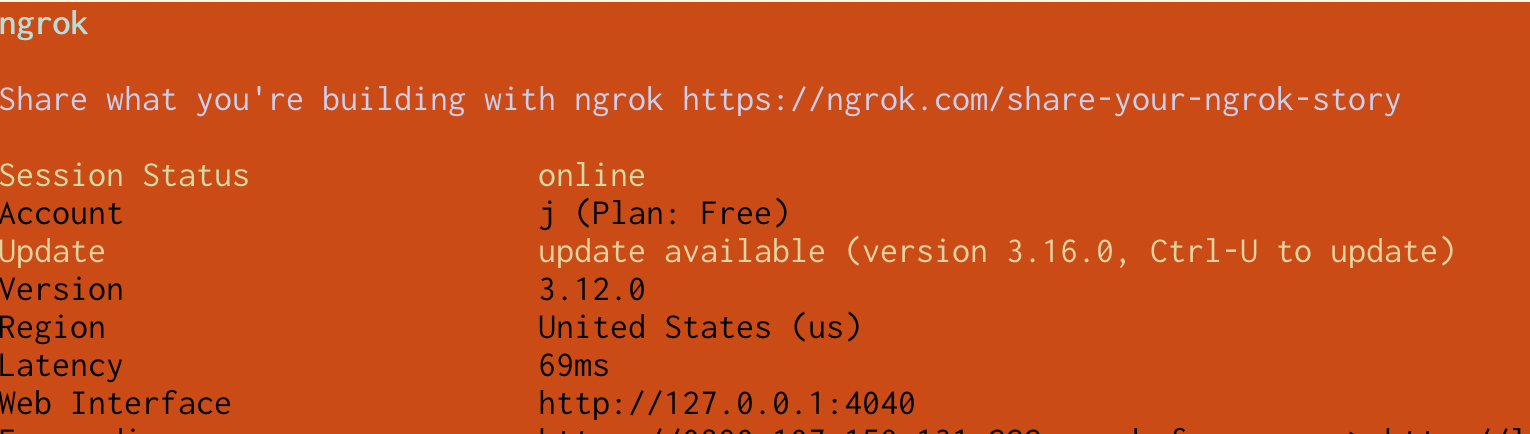
I didn’t have minimum contrast turned on before but I just turned it on today because it makes such a big difference when something goes wrong with colours in the terminal.
problem 6: TERM being set to the wrong thing
A few people mentioned that they’ll SSH into a system that doesn’t support the
TERM environment variable that they have set locally, and then the colours
won’t work.
I think the way TERM works is that systems have a terminfo database, so if
the value of the TERM environment variable isn’t in the system’s terminfo
database, then it won’t know how to output colours for that terminal. I don’t
know too much about terminfo, but someone linked me to this terminfo rant that talks about a few other
issues with terminfo.
I don’t have a system on hand to reproduce this one so I can’t say for sure how
to fix it, but this stackoverflow question
suggests running something like TERM=xterm ssh instead of ssh.
problem 7: picking “good” colours is hard
A couple of problems people mentioned with designing / finding terminal colorschemes:
- some folks are colorblind and have trouble finding an appropriate colorscheme
- accidentally making the background color too close to the cursor or selection color, so they’re hard to find
- generally finding colours that work with every program is a struggle (for example you can see me having a problem with this with ngrok above!)
problem 8: making nethack/mc look right
Another problem people mentioned is using a program like nethack or midnight commander which you might expect to have a specific colourscheme based on the default ANSI terminal colours.
For example, midnight commander has a really specific classic look:
But in my Solarized theme, midnight commander looks like this:
The Solarized version feels like it could be disorienting if you’re very used to the “classic” look.
One solution Simon Tatham mentioned to this is using some palette customization ANSI codes (like the ones base16 uses that I talked about earlier) to change the color palette right before starting the program, for example remapping yellow to a brighter yellow before starting Nethack so that the yellow characters look better.
problem 9: commands disabling colours when writing to a pipe
If I run fd | less, I see something like this, with the colours disabled.

In general I find this useful – if I pipe a command to grep, I don’t want it
to print out all those color escape codes, I just want the plain text. But what if you want to see the colours?
To see the colours, you can run unbuffer fd | less -r! I just learned about
unbuffer recently and I think it’s really cool, unbuffer opens a tty for the
command to write to so that it thinks it’s writing to a TTY. It also fixes
issues with programs buffering their output when writing to a pipe, which is
why it’s called unbuffer.
Here’s what the output of unbuffer fd | less -r looks like for me:

Also some commands (including fd) support a --color=always flag which will
force them to always print out the colours.
problem 10: unwanted colour in ls and other commands
Some people mentioned that they don’t want ls to use colour at all, perhaps
because ls uses blue, it’s hard to read on black, and maybe they don’t feel like
customizing their terminal’s colourscheme to make the blue more readable or
just don’t find the use of colour helpful.
Some possible solutions to this one:
- you can run
ls --color=never, which is probably easiest - you can also set
LS_COLORSto customize the colours used byls. I think some other programs other thanlssupport theLS_COLORSenvironment variable too. - also some programs support setting
NO_COLOR=true(there’s a list here)
Here’s an example of running LS_COLORS="fi=0:di=0:ln=0:pi=0:so=0:bd=0:cd=0:or=0:ex=0" ls:

problem 11: the colours in vim
I used to have a lot of problems with configuring my colours in vim – I’d set up my terminal colours in a way that I thought was okay, and then I’d start vim and it would just be a disaster.
I think what was going on here is that today, there are two ways to set up a vim colorscheme in the terminal:
- using your ANSI terminal colours – you tell vim which ANSI colour number to use for the background, for functions, etc.
- using 24-bit hex colours – instead of ANSI terminal colours, the vim colorscheme can use hex codes like #faea99 directly
20 years ago when I started using vim, terminals with 24-bit hex color support were a lot less common (or maybe they didn’t exist at all), and vim certainly didn’t have support for using 24-bit colour in the terminal. From some quick searching through git, it looks like vim added support for 24-bit colour in 2016 – just 8 years ago!
So to get colours to work properly in vim before 2016, you needed to synchronize
your terminal colorscheme and your vim colorscheme. Here’s what that looked like,
the colorscheme needed to map the vim color classes like cterm05 to ANSI colour numbers.
But in 2024, the story is really different! Vim (and Neovim, which I use now)
support 24-bit colours, and as of Neovim 0.10 (released in May 2024), the
termguicolors setting (which tells Vim to use 24-bit hex colours for
colorschemes) is turned on by default in any terminal with 24-bit
color support.
So this “you need to synchronize your terminal colorscheme and your vim colorscheme” problem is not an issue anymore for me in 2024, since I don’t plan to use terminals without 24-bit color support in the future.
The biggest consequence for me of this whole thing is that I don’t need base16
to set colors 16-21 to weird stuff anymore to integrate with vim – I can just
use a terminal theme and a vim theme, and as long as the two themes use similar
colours (so it’s not jarring for me to switch between them) there’s no problem.
I think I can just remove those parts from my base16 shell script and totally
avoid the problem with ngrok and the weird orange background I talked about
above.
some more problems I left out
I think there are a lot of issues around the intersection of multiple programs, like using some combination tmux/ssh/vim that I couldn’t figure out how to reproduce well enough to talk about them. Also I’m sure I missed a lot of other things too.
base16 has really worked for me
I’ve personally had a lot of success with using
base16-shell with
base16-vim – I just need to add a couple of lines to my
fish config to set it up (+ a few .vimrc lines) and then I can move on and
accept any remaining problems that that doesn’t solve.
I don’t think base16 is for everyone though, some limitations I’m aware of with base16 that might make it not work for you:
- it comes with a limited set of builtin themes and you might not like any of them
- the Solarized base16 theme (and maybe all of the themes?) sets the “bright” ANSI colours to be exactly the same as the normal colours, which might cause a problem if you’re relying on the “bright” colours to be different from the regular ones
- it sets colours 16-21 in order to give the vim colorschemes from
base16-vimaccess to more colours, which might not be relevant if you always use a terminal with 24-bit color support, and can cause problems like the ngrok issue above - also the way it sets colours 16-21 could be a problem in terminals that don’t have 256-color support, like the linux framebuffer terminal
Apparently there’s a community fork of base16 called tinted-theming, which I haven’t looked into much yet.
some other colorscheme tools
Just one so far but I’ll link more if people tell me about them:
- rootloops.sh for generating colorschemes (and “let’s create a terminal color scheme”)
- Some popular colorschemes (according to people I asked on Mastodon): catpuccin, Monokai, Gruvbox, Dracula, Modus (a high contrast theme), Tokyo Night, Nord, Rosé Pine
okay, that was a lot
We talked about a lot in this post and while I think learning about all these details is kind of fun if I’m in the mood to do a deep dive, I find it SO FRUSTRATING to deal with it when I just want my colours to work! Being surprised by unreadable text and having to find a workaround is just not my idea of a good day.
Personally I’m a zero-configuration kind of person and it’s not that appealing to me to have to put together a lot of custom configuration just to make my colours in the terminal look acceptable. I’d much rather just have some reasonable defaults that I don’t have to change.
minimum contrast seems like an amazing feature
My one big takeaway from writing this was to turn on “minimum contrast” in my terminal, I think it’s going to fix most of the occasional accidental unreadable text issues I run into and I’m pretty excited about it.
Some Go web dev notes
I spent a lot of time in the past couple of weeks working on a website in Go that may or may not ever see the light of day, but I learned a couple of things along the way I wanted to write down. Here they are:
go 1.22 now has better routing
I’ve never felt motivated to learn any of the Go routing libraries (gorilla/mux, chi, etc), so I’ve been doing all my routing by hand, like this.
// DELETE /records:
case r.Method == "DELETE" && n == 1 && p[0] == "records":
if !requireLogin(username, r.URL.Path, r, w) {
return
}
deleteAllRecords(ctx, username, rs, w, r)
// POST /records/<ID>
case r.Method == "POST" && n == 2 && p[0] == "records" && len(p[1]) > 0:
if !requireLogin(username, r.URL.Path, r, w) {
return
}
updateRecord(ctx, username, p[1], rs, w, r)
But apparently as of Go 1.22, Go now has better support for routing in the standard library, so that code can be rewritten something like this:
mux.HandleFunc("DELETE /records/", app.deleteAllRecords)
mux.HandleFunc("POST /records/{record_id}", app.updateRecord)
Though it would also need a login middleware, so maybe something more like
this, with a requireLogin middleware.
mux.Handle("DELETE /records/", requireLogin(http.HandlerFunc(app.deleteAllRecords)))
a gotcha with the built-in router: redirects with trailing slashes
One annoying gotcha I ran into was: if I make a route for /records/, then a
request for /records will be redirected to /records/.
I ran into an issue with this where sending a POST request to /records
redirected to a GET request for /records/, which broke the POST request
because it removed the request body. Thankfully Xe Iaso wrote a blog post about the exact same issue which made it
easier to debug.
I think the solution to this is just to use API endpoints like POST /records
instead of POST /records/, which seems like a more normal design anyway.
sqlc automatically generates code for my db queries
I got a little bit tired of writing so much boilerplate for my SQL queries, but I didn’t really feel like learning an ORM, because I know what SQL queries I want to write, and I didn’t feel like learning the ORM’s conventions for translating things into SQL queries.
But then I found sqlc, which will compile a query like this:
-- name: GetVariant :one
SELECT *
FROM variants
WHERE id = ?;
into Go code like this:
const getVariant = `-- name: GetVariant :one
SELECT id, created_at, updated_at, disabled, product_name, variant_name
FROM variants
WHERE id = ?
`
func (q *Queries) GetVariant(ctx context.Context, id int64) (Variant, error) {
row := q.db.QueryRowContext(ctx, getVariant, id)
var i Variant
err := row.Scan(
&i.ID,
&i.CreatedAt,
&i.UpdatedAt,
&i.Disabled,
&i.ProductName,
&i.VariantName,
)
return i, err
}
What I like about this is that if I’m ever unsure about what Go code to write for a given SQL query, I can just write the query I want, read the generated function and it’ll tell me exactly what to do to call it. It feels much easier to me than trying to dig through the ORM’s documentation to figure out how to construct the SQL query I want.
Reading Brandur’s sqlc notes from 2024 also gave me some confidence that this is a workable path for my tiny programs. That post gives a really helpful example of how to conditionally update fields in a table using CASE statements (for example if you have a table with 20 columns and you only want to update 3 of them).
sqlite tips
Someone on Mastodon linked me to this post called Optimizing sqlite for servers. My projects are small and I’m not so concerned about performance, but my main takeaways were:
- have a dedicated object for writing to the database, and run
db.SetMaxOpenConns(1)on it. I learned the hard way that if I don’t do this then I’ll getSQLITE_BUSYerrors from two threads trying to write to the db at the same time. - if I want to make reads faster, I could have 2 separate db objects, one for writing and one for reading
There are a more tips in that post that seem useful (like “COUNT queries are slow” and “Use STRICT tables”), but I haven’t done those yet.
Also sometimes if I have two tables where I know I’ll never need to do a JOIN
beteween them, I’ll just put them in separate databases so that I can connect
to them independently.
Go 1.19 introduced a way to set a GC memory limit
I run all of my Go projects in VMs with relatively little memory, like 256MB or 512MB. I ran into an issue where my application kept getting OOM killed and it was confusing – did I have a memory leak? What?
After some Googling, I realized that maybe I didn’t have a memory leak, maybe I just needed to reconfigure the garbage collector! It turns out that by default (according to A Guide to the Go Garbage Collector), Go’s garbage collector will let the application allocate memory up to 2x the current heap size.
Mess With DNS’s base heap size is around 170MB and the amount of memory free on the VM is around 160MB right now, so if its memory doubled, it’ll get OOM killed.
In Go 1.19, they added a way to tell Go “hey, if the application starts using this much memory, run a GC”. So I set the GC memory limit to 250MB and it seems to have resulted in the application getting OOM killed less often:
export GOMEMLIMIT=250MiB
some reasons I like making websites in Go
I’ve been making tiny websites (like the nginx playground) in Go on and off for the last 4 years or so and it’s really been working for me. I think I like it because:
- there’s just 1 static binary, all I need to do to deploy it is copy the binary. If there are static files I can just embed them in the binary with embed.
- there’s a built-in webserver that’s okay to use in production, so I don’t need to configure WSGI or whatever to get it to work. I can just put it behind Caddy or run it on fly.io or whatever.
- Go’s toolchain is very easy to install, I can just do
apt-get install golang-goor whatever and then ago buildwill build my project - it feels like there’s very little to remember to start sending HTTP responses
– basically all there is are functions like
Serve(w http.ResponseWriter, r *http.Request)which read the request and send a response. If I need to remember some detail of how exactly that’s accomplished, I just have to read the function! - also
net/httpis in the standard library, so you can start making websites without installing any libraries at all. I really appreciate this one. - Go is a pretty systems-y language, so if I need to run an
ioctlor something that’s easy to do
In general everything about it feels like it makes projects easy to work on for 5 days, abandon for 2 years, and then get back into writing code without a lot of problems.
For contrast, I’ve tried to learn Rails a couple of times and I really want to love Rails – I’ve made a couple of toy websites in Rails and it’s always felt like a really magical experience. But ultimately when I come back to those projects I can’t remember how anything works and I just end up giving up. It feels easier to me to come back to my Go projects that are full of a lot of repetitive boilerplate, because at least I can read the code and figure out how it works.
things I haven’t figured out yet
some things I haven’t done much of yet in Go:
- rendering HTML templates: usually my Go servers are just APIs and I make the
frontend a single-page app with Vue. I’ve used
html/templatea lot in Hugo (which I’ve used for this blog for the last 8 years) but I’m still not sure how I feel about it. - I’ve never made a real login system, usually my servers don’t have users at all.
- I’ve never tried to implement CSRF
In general I’m not sure how to implement security-sensitive features so I don’t start projects which need login/CSRF/etc. I imagine this is where a framework would help.
it’s cool to see the new features Go has been adding
Both of the Go features I mentioned in this post (GOMEMLIMIT and the routing)
are new in the last couple of years and I didn’t notice when they came out. It
makes me think I should pay closer attention to the release notes for new Go
versions.
Reasons I still love the fish shell
I wrote about how much I love fish in this blog post from 2017 and, 7 years of using it every day later, I’ve found even more reasons to love it. So I thought I’d write a new post with both the old reasons I loved it and some reasons.
This came up today because I was trying to figure out why my terminal doesn’t break anymore when I cat a binary to my terminal, the answer was “fish fixes the terminal!”, and I just thought that was really nice.
1. no configuration
In 10 years of using fish I have never found a single thing I wanted to configure. It just works the way I want. My fish config file just has:
- environment variables
- aliases (
alias ls eza,alias vim nvim, etc) - the occasional
direnv hook fish | sourceto integrate a tool like direnv - a script I run to set up my terminal colours
I’ve been told that configuring things in fish is really easy if you ever do want to configure something though.
2. autosuggestions from my shell history
My absolute favourite thing about fish is that I type, it’ll automatically suggest (in light grey) a matching command that I ran recently. I can press the right arrow key to accept the completion, or keep typing to ignore it.
Here’s what that looks like. In this example I just typed the “v” key and it guessed that I want to run the previous vim command again.

2.5 “smart” shell autosuggestions
One of my favourite subtle autocomplete features is how fish handles autocompleting commands that contain paths in them. For example, if I run:
$ ls blah.txt
that command will only be autocompleted in directories that contain blah.txt – it won’t show up in a different directory. (here’s a short comment about how it works)
As an example, if in this directory I type bash scripts/, it’ll only suggest
history commands including files that actually exist in my blog’s scripts
folder, and not the dozens of other irrelevant scripts/ commands I’ve run in
other folders.
I didn’t understand exactly how this worked until last week, it just felt like fish was magically able to suggest the right commands. It still feels a little like magic and I love it.
3. pasting multiline commands
If I copy and paste multiple lines, bash will run them all, like this:
[bork@grapefruit linux-playground (main)]$ echo hi
hi
[bork@grapefruit linux-playground (main)]$ touch blah
[bork@grapefruit linux-playground (main)]$ echo hi
hi
This is a bit alarming – what if I didn’t actually want to run all those commands?
Fish will paste them all at a single prompt, so that I can press Enter if I actually want to run them. Much less scary.
bork@grapefruit ~/work/> echo hi
touch blah
echo hi
4. nice tab completion
If I run ls and press tab, it’ll display all the filenames in a nice grid. I can use either Tab, Shift+Tab, or the arrow keys to navigate the grid.
Also, I can tab complete from the middle of a filename – if the filename starts with a weird character (or if it’s just not very unique), I can type some characters from the middle and press tab.
Here’s what the tab completion looks like:
bork@grapefruit ~/work/> ls
api/ blah.py fly.toml README.md
blah Dockerfile frontend/ test_websocket.sh
I honestly don’t complete things other than filenames very much so I can’t speak to that, but I’ve found the experience of tab completing filenames to be very good.
5. nice default prompt (including git integration)
Fish’s default prompt includes everything I want:
- username
- hostname
- current folder
- git integration
- status of last command exit (if the last command failed)
Here’s a screenshot with a few different variations on the default prompt,
including if the last command was interrupted (the SIGINT) or failed.

6. nice history defaults
In bash, the maximum history size is 500 by default, presumably because computers used to be slow and not have a lot of disk space. Also, by default, commands don’t get added to your history until you end your session. So if your computer crashes, you lose some history.
In fish:
- the default history size is 256,000 commands. I don’t see any reason I’d ever need more.
- if you open a new tab, everything you’ve ever run (including commands in open sessions) is immediately available to you
- in an existing session, the history search will only include commands from the current session, plus everything that was in history at the time that you started the shell
I’m not sure how clearly I’m explaining how fish’s history system works here, but it feels really good to me in practice. My impression is that the way it’s implemented is the commands are continually added to the history file, but fish only loads the history file once, on startup.
I’ll mention here that if you want to have a fancier history system in another shell it might be worth checking out atuin or fzf.
7. press up arrow to search history
I also like fish’s interface for searching history: for example if I want to edit my fish config file, I can just type:
$ config.fish
and then press the up arrow to go back the last command that included config.fish. That’ll complete to:
$ vim ~/.config/fish/config.fish
and I’m done. This isn’t so different from using Ctrl+R in bash to search
your history but I think I like it a little better over all, maybe because
Ctrl+R has some behaviours that I find confusing (for example you can
end up accidentally editing your history which I don’t like).
8. the terminal doesn’t break
I used to run into issues with bash where I’d accidentally cat a binary to
the terminal, and it would break the terminal.
Every time fish displays a prompt, it’ll try to fix up your terminal so that you don’t end up in weird situations like this. I think this is some of the code in fish to prevent broken terminals.
Some things that it does are:
- turn on
echoso that you can see the characters you type - make sure that newlines work properly so that you don’t get that weird staircase effect
- reset your terminal background colour, etc
I don’t think I’ve run into any of these “my terminal is broken” issues in a very long time, and I actually didn’t even realize that this was because of fish – I thought that things somehow magically just got better, or maybe I wasn’t making as many mistakes. But I think it was mostly fish saving me from myself, and I really appreciate that.
9. Ctrl+S is disabled
Also related to terminals breaking: fish disables Ctrl+S (which freezes your terminal and then you need to remember to press Ctrl+Q to unfreeze it). It’s a feature that I’ve never wanted and I’m happy to not have it.
Apparently you can disable Ctrl+S in other shells with stty -ixon.
10. nice syntax highlighting
By default commands that don’t exist are highlighted in red, like this.

11. easier loops
I find the loop syntax in fish a lot easier to type than the bash syntax. It looks like this:
for i in *.yaml
echo $i
end
Also it’ll add indentation in your loops which is nice.
12. easier multiline editing
Related to loops: you can edit multiline commands much more easily than in bash (just use the arrow keys to navigate the multiline command!). Also when you use the up arrow to get a multiline command from your history, it’ll show you the whole command the exact same way you typed it instead of squishing it all onto one line like bash does:
$ bash
$ for i in *.png
> do
> echo $i
> done
$ # press up arrow
$ for i in *.png; do echo $i; done ink
13. Ctrl+left arrow
This might just be me, but I really appreciate that fish has the Ctrl+left arrow / Ctrl+right arrow keyboard shortcut for moving between
words when writing a command.
I’m honestly a bit confused about where this keyboard shortcut is coming from
(the only documented keyboard shortcut for this I can find in fish is Alt+left arrow / Alt + right arrow which seems to do the same thing), but I’m pretty
sure this is a fish shortcut.
A couple of notes about getting this shortcut to work / where it comes from:
- one person said they needed to switch their terminal emulator from the “Linux console” keybindings to “Default (XFree 4)” to get it to work in fish
- on Mac OS,
Ctrl+left arrowswitches workspaces by default, so I had to turn that off. - Also apparently Ubuntu configures libreadline in
/etc/inputrcto makeCtrl+left/right arrowgo back/forward a word, so it’ll work in bash on Ubuntu and maybe other Linux distros too. Here’s a stack overflow question talking about that
a downside: not everything has a fish integration
Sometimes tools don’t have instructions for integrating them with fish. That’s annoying, but:
- I’ve found this has gotten better over the last 10 years as fish has gotten more popular. For example Python’s virtualenv has had a fish integration for a long time now.
- If I need to run a POSIX shell command real quick, I can always just run
bashorzsh - I’ve gotten much better over the years at translating simple commands to fish syntax when I need to
My biggest day-to-day to annoyance is probably that for whatever reason I’m
still not used to fish’s syntax for setting environment variables, I get confused
about set vs set -x.
another downside: fish_add_path
fish has a function called fish_add_path that you can run to add a directory
to your PATH like this:
fish_add_path /some/directory
I love the idea of it and I used to use it all the time, but I’ve stopped using it for two reasons:
- Sometimes
fish_add_pathwill update thePATHfor every session in the future (with a “universal variable”) and sometimes it will update thePATHjust for the current session. It’s hard for me to tell which one it will do: in theory the docs explain this but I could not understand them. - If you ever need to remove the directory from your
PATHa few weeks or months later because maybe you made a mistake, that’s also kind of hard to do (there are instructions in this comments of this github issue though).
Instead I just update my PATH like this, similarly to how I’d do it in bash:
set PATH $PATH /some/directory/bin
on POSIX compatibility
When I started using fish, you couldn’t do things like cmd1 && cmd2 – it
would complain “no, you need to run cmd1; and cmd2” instead.
It seems like over the years fish has started accepting a little more POSIX-style syntax than it used to, like:
cmd1 && cmd2export a=bto set an environment variable (though this seems a bit limited, you can’t doexport PATH=$PATH:/whateverso I think it’s probably better to learnsetinstead)
on fish as a default shell
Changing my default shell to fish is always a little annoying, I occasionally get myself into a situation where
- I install fish somewhere like maybe
/home/bork/.nix-stuff/bin/fish - I add the new fish location to
/etc/shellsas an allowed shell - I change my shell with
chsh - at some point months/years later I reinstall fish in a different location for some reason and remove the old one
- oh no!!! I have no valid shell! I can’t open a new terminal tab anymore!
This has never been a major issue because I always have a terminal open somewhere where I can fix the problem and rescue myself, but it’s a bit alarming.
If you don’t want to use chsh to change your shell to fish (which is very reasonable,
maybe I shouldn’t be doing that), the Arch wiki page has a couple of good suggestions –
either configure your terminal emulator to run fish or add an exec fish to
your .bashrc.
I’ve never really learned the scripting language
Other than occasionally writing a for loop interactively on the command line, I’ve never really learned the fish scripting language. I still do all of my shell scripting in bash.
I don’t think I’ve ever written a fish function or if statement.
it seems like fish is getting pretty popular
I ran a highly unscientific poll on Mastodon asking people what shell they use interactively. The results were (of 2600 responses):
- 46% bash
- 49% zsh
- 16% fish
- 5% other
I think 16% for fish is pretty remarkable, since (as far as I know) there isn’t any system where fish is the default shell, and my sense is that it’s very common to just stick to whatever your system’s default shell is.
It feels like a big achievement for the fish project, even if maybe my Mastodon followers are more likely than the average shell user to use fish for some reason.
who might fish be right for?
Fish definitely isn’t for everyone. I think I like it because:
- I really dislike configuring my shell (and honestly my dev environment in general), I want things to “just work” with the default settings
- fish’s defaults feel good to me
- I don’t spend that much time logged into random servers using other shells so there’s not too much context switching
- I liked its features so much that I was willing to relearn how to do a few
“basic” shell things, like using parentheses
(seq 1 10)to run a command instead of backticks or usingsetinstead ofexport
Maybe you’re also a person who would like fish! I hope a few more of the people who fish is for can find it, because I spend so much of my time in the terminal and it’s made that time much more pleasant.
Migrating Mess With DNS to use PowerDNS
About 3 years ago, I announced Mess With DNS in this blog post, a playground where you can learn how DNS works by messing around and creating records.
I wasn’t very careful with the DNS implementation though (to quote the release blog post: “following the DNS RFCs? not exactly”), and people started reporting problems that eventually I decided that I wanted to fix.
the problems
Some of the problems people have reported were:
- domain names with underscores weren’t allowed, even though they should be
- If there was a CNAME record for a domain name, it allowed you to create other records for that domain name, even if it shouldn’t
- you could create 2 different CNAME records for the same domain name, which shouldn’t be allowed
- no support for the SVCB or HTTPS record types, which seemed a little complex to implement
- no support for upgrading from UDP to TCP for big responses
And there are certainly more issues that nobody got around to reporting, for example that if you added an NS record for a subdomain to delegate it, Mess With DNS wouldn’t handle the delegation properly.
the solution: PowerDNS
I wasn’t sure how to fix these problems for a long time – technically I could have started addressing them individually, but it felt like there were a million edge cases and I’d never get there.
But then one day I was chatting with someone else who was working on a DNS server and they said they were using PowerDNS: an open source DNS server with an HTTP API!
This seemed like an obvious solution to my problems – I could just swap out my own crappy DNS implementation for PowerDNS.
There were a couple of challenges I ran into when setting up PowerDNS that I’ll talk about here. I really don’t do a lot of web development and I think I’ve never built a website that depends on a relatively complex API before, so it was a bit of a learning experience.
challenge 1: getting every query made to the DNS server
One of the main things Mess With DNS does is give you a live view of every DNS query it receives for your subdomain, using a websocket. To make this work, it needs to intercept every DNS query before they it gets sent to the PowerDNS DNS server:
There were 2 options I could think of for how to intercept the DNS queries:
- dnstap:
dnsdist(a DNS load balancer from the PowerDNS project) has support for logging all DNS queries it receives using dnstap, so I could put dnsdist in front of PowerDNS and then log queries that way - Have my Go server listen on port 53 and proxy the queries myself
I originally implemented option #1, but for some reason there was a 1 second delay before every query got logged. I couldn’t figure out why, so I implemented my own very simple proxy instead.
challenge 2: should the frontend have direct access to the PowerDNS API?
The frontend used to have a lot of DNS logic in it – it converted emoji domain
names to ASCII using punycode, had a lookup table to convert numeric DNS query
types (like 1) to their human-readable names (like A), did a little bit of
validation, and more.
Originally I considered keeping this pattern and just giving the frontend (more or less) direct access to the PowerDNS API to create and delete, but writing even more complex code in Javascript didn’t feel that appealing to me – I don’t really know how to write tests in Javascript and it seemed like it wouldn’t end well.
So I decided to take all of the DNS logic out of the frontend and write a new DNS API for managing records, shaped something like this:
GET /recordsDELETE /records/<ID>DELETE /records/(delete all records for a user)POST /records/(create record)POST /records/<ID>(update record)
This meant that I could actually write tests for my code, since the backend is in Go and I do know how to write tests in Go.
what I learned: it’s okay for an API to duplicate information
I had this idea that APIs shouldn’t return duplicate information – for example if I get a DNS record, it should only include a given piece of information once.
But I ran into a problem with that idea when displaying MX records: an MX record has 2 fields, “preference”, and “mail server”. And I needed to display that information in 2 different ways on the frontend:
- In a form, where “Preference” and “Mail Server” are 2 different form fields (like
10andmail.example.com) - In a summary view, where I wanted to just show the record (
10 mail.example.com)
This is kind of a small problem, but it came up in a few different places.
I talked to my friend Marco Rogers about this, and based on some advice from him I realized that I could return the same information in the API in 2 different ways! Then the frontend just has to display it. So I started just returning duplicate information in the API, something like this:
{
values: {'Preference': 10, 'Server': 'mail.example.com'},
content: '10 mail.example.com',
...
}
I ended up using this pattern in a couple of other places where I needed to display the same information in 2 different ways and it was SO much easier.
I think what I learned from this is that if I’m making an API that isn’t intended for external use (there are no users of this API other than the frontend!), I can tailor it very specifically to the frontend’s needs and that’s okay.
challenge 3: what’s a record’s ID?
In Mess With DNS (and I think in most DNS user interfaces!), you create, add, and delete records.
But that’s not how the PowerDNS API works. In PowerDNS, you create a zone, which is made of record sets. Records don’t have any ID in the API at all.
I ended up solving this by generate a fake ID for each records which is made of:
- its name
- its type
- and its content (base64-encoded)
For example one record’s ID is brooch225.messwithdns.com.|NS|bnMxLm1lc3N3aXRoZG5zLmNvbS4=
Then I can search through the zone and find the appropriate record to update it.
This means that if you update a record then its ID will change which isn’t usually what I want in an ID, but that seems fine.
challenge 4: making clear error messages
I think the error messages that the PowerDNS API returns aren’t really intended to be shown to end users, for example:
Name 'new\032site.island358.messwithdns.com.' contains unsupported characters(this error encodes the space as\032, which is a bit disorienting if you don’t know that the space character is 32 in ASCII)RRset test.pear5.messwithdns.com. IN CNAME: Conflicts with pre-existing RRset(this talks about RRsets, which aren’t a concept that the Mess With DNS UI has at all)Record orange.beryl5.messwithdns.com./A '1.2.3.4$': Parsing record content (try 'pdnsutil check-zone'): unable to parse IP address, strange character: $(mentions “pdnsutil”, a utility which Mess With DNS’s users don’t have access to in this context)
I ended up handling this in two ways:
- Do some initial basic validation of values that users enter (like IP addresses), so I can just return errors like
Invalid IPv4 address: "1.2.3.4$ - If that goes well, send the request to PowerDNS and if we get an error back, then do some hacky translation of those messages to make them clearer.
Sometimes users will still get errors from PowerDNS directly, but I added some logging of all the errors that users see, so hopefully I can review them and add extra translations if there are other common errors that come up.
I think what I learned from this is that if I’m building a user-facing application on top of an API, I need to be pretty thoughtful about how I resurface those errors to users.
challenge 5: setting up SQLite
Previously Mess With DNS was using a Postgres database. This was problematic
because I only gave the Postgres machine 256MB of RAM, which meant that the
database got OOM killed almost every single day. I never really worked out
exactly why it got OOM killed every day, but that’s how it was. I spent some
time trying to tune Postgres’ memory usage by setting the max connections /
work-mem / maintenance-work-mem and it helped a bit but didn’t solve the
problem.
So for this refactor I decided to use SQLite instead, because the website doesn’t really get that much traffic. There are some choices involved with using SQLite, and I decided to:
- Run
db.SetMaxOpenConns(1)to make sure that we only open 1 connection to the database at a time, to preventSQLITE_BUSYerrors from two threads trying to access the database at the same time (just setting WAL mode didn’t work) - Use separate databases for each of the 3 tables (users, records, and requests) to reduce contention. This maybe isn’t really necessary, but there was no reason I needed the tables to be in the same database so I figured I’d set up separate databases to be safe.
- Use the cgo-free modernc.org/sqlite, which translates SQLite’s source code to Go. I might switch to a more “normal” sqlite implementation instead at some point and use cgo though. I think the main reason I prefer to avoid cgo is that cgo has landed me with difficult-to-debug errors in the past.
- use WAL mode
I still haven’t set up backups, though I don’t think my Postgres database had backups either. I think I’m unlikely to use litestream for backups – Mess With DNS is very far from a critical application, and I think daily backups that I could recover from in case of a disaster are more than good enough.
challenge 6: upgrading Vue & managing forms
This has nothing to do with PowerDNS but I decided to upgrade Vue.js from version 2 to 3 as part of this refresh. The main problem with that is that the form validation library I was using (FormKit) completely changed its API between Vue 2 and Vue 3, so I decided to just stop using it instead of learning the new API.
I ended up switching to some form validation tools that are built into the
browser like required and oninvalid (here’s the code).
I think it could use some of improvement, I still don’t understand forms very well.
challenge 7: managing state in the frontend
This also has nothing to do with PowerDNS, but when modifying the frontend I realized that my state management in the frontend was a mess – in every place where I made an API request to the backend, I had to try to remember to add a “refresh records” call after that in every place that I’d modified the state and I wasn’t always consistent about it.
With some more advice from Marco, I ended up implementing a single global state management store which stores all the state for the application, and which lets me create/update/delete records.
Then my components can just call store.createRecord(record), and the store
will automatically resynchronize all of the state as needed.
challenge 8: sequencing the project
This project ended up having several steps because I reworked the whole integration between the frontend and the backend. I ended up splitting it into a few different phases:
- Upgrade Vue from v2 to v3
- Make the state management store
- Implement a different backend API, move a lot of DNS logic out of the frontend, and add tests for the backend
- Integrate PowerDNS
I made sure that the website was (more or less) 100% working and then deployed it in between phases, so that the amount of changes I was managing at a time stayed somewhat under control.
the new website is up now!
I released the upgraded website a few days ago and it seems to work! The PowerDNS API has been great to work on top of, and I’m relieved that there’s a whole class of problems that I now don’t have to think about at all, other than potentially trying to make the error messages from PowerDNS a little clearer. Using PowerDNS has fixed a lot of the DNS issues that folks have reported in the last few years and it feels great.
If you run into problems with the new Mess With DNS I’d love to hear about them here.