Reading List
The most recent articles from a list of feeds I subscribe to.
Reaching the Unix Philosophy's Logical Extreme with Webassembly

YouTube link (please let me know if the iframe doesn't work for you)

Good morning Berlin! How're you doing this fine morning? I'm Xe and today I'm gonna talk about something that I'm really excited about:
WebAssembly. WebAssembly is a compiler target for an imaginary CPU that your phones, tablets, laptops, gaming towers and even watches can run. It's intended to be a level below JavaScript to allow us to ship code in maintainable languages. Today I'm gonna be talking about fun ways you can take advantage of WebAssembly, but first we need to talk about the other main part of this subject:
Unix. Unix is the sole survivor of the early OS wars. It's not really that exciting from a computer science standpoint other than it was where C became popular and it uses file and filesystem API calls to interface with a lot of hardware.
Dealing with some source code files? Discover them in the filesystem in your home directory and write to them with the file API.
Dealing with disks? Discover them in the filesystem and manage them with the file API.
Design is rooted in philosophy, and Unix has a core philosophy that all the decisions stem from. This is usually quoted as "everything is a file" but what does that even mean? How does that handle things that aren't literally files?
(Pause)
And wait, who's this Xe person?

Like the nice person with that microphone said, I'm Xe. I'm the person that put IPv6 packets into S3 and I work at Tailscale doing developer relations. I'm also the only person I know with the job title of Archmage. I'm a prolific blogger and I live in Ottawa in Canada with my husband.
I'm also a philosopher. As a little hint for anyone here, when someone openly introduces themselves as a philosopher, you should know you're in for some fun.

Speaking of fun, I know you got up early for this talk because it sold itself as a WebAssembly talk, but I'm actually going to break a little secret with you. This isn't just a WebAssembly talk. This is an operating systems talk because most of the difficulties with using WebAssembly in the real world are actually operating systems issues. In this talk I'm going to start with the Unix philosophy, talk about how it relates to files, and then I'm gonna circle back to WebAssembly. Really, I promise.
So, going back to where we were with Unix, what does it mean for everything to be a file? What is a file in the first place?
In Unix, what we call "files" are actually just kernel objects we can make a bunch of calls to. And in a very Unix way, file handles aren't really opaque values; they are just arbitrary integers that just so happen to be indices into an array that lives in the struct your kernel uses to keep track of open files in that process. That is the main security model for access to files when running untrusted code in Linux processes.
So with these array indices as arguments to some core system calls you can do some basic calls such as-
(Pause)
Actually, now that I think about it, we just spent half an hour sitting and watching that lovely talk on the Go ecosystem. Let's do a little bit of exercise. Get that blood flowing!
So how many of you can raise your hands? Keep them up, let's get those hands up!
(Pause)
Alright, alright, keep them up.

How many of you have seen one of these 3d printed save icon things in person? If you have, keep your hand up. If not, put it down.
(Pause)

How many of you have used one of them in school, at work, or even at home? If you have, keep it up, if not, put it down.
(Pause)
Alright, thanks again! One more time!

How about one of these audio-only VHS tapes? Keep it up or put it down.
Alright, for those of you with your hands up, it's probably time to schedule that colonoscopy. Take advantage of that socialized medicine! You can put your hands down now, I don't want to be liable.
(Audience laughs)
For the gen-zed in the crowd that had no idea what these things are, a cassette tape was what we used to store music on back when there were 9 planets.
(Audience laughs)
So when I say files, let's think about these. Cassette tapes. Cassette tapes have the same basic usage properties as files.
To start, you can read from files and play music from a cassette tape in all that warm analog goodness. You can write to files and record audio to a cassette tape. Know the term "mixtape"? That's where it comes from. You can also open files and insert a cassette tape into a tape player. When you're done with them, you can close files and remove tapes from a tape player. And finally you can fast-forward and rewind the tape to find the song you want. Imagine that Gen Z, imagine having to find your songs on the tape instead of skipping right to them.
And these same calls work on log files, hard drives, and more. These 5 basic calls are the heart of Unix that everything spills out from, and this basic model gets you so far that it's how this little OS you've never heard of called Plan 9 works.
But what about things that don't directly map to files? What about network sockets? Network sockets are the abstraction that Unix uses to let applications connect to another computer over a network like the internet. You can open sockets, you can close them, you can read from them, you can write to them. But are they files?

Turns out, they are! In Unix you use mostly the same calls for dealing with network sockets that you do for files. Network sockets are treated like one of these things: an AUX cable to cassette tape adaptor. This was what we used to use in order to get our MP3 players, CD players, Gameboys, and smartphones connected up to the car stereo. This isn't a bit, we actually used these a lot. Yes, we actually used these. I used one extensively when I was delivering pizzas in high school to get the turn by turn navigation directions read out loud to me. We had no other options before Bluetooth existed. It was our only compromise.
(Audience laughs)
How about processes? Those are known to be another hallmark of the Unix philosophy. The Unix philosophy is also understood to be that programs should be filters that take the input and spruce it up for the next stage of the pipeline. Under the hood, are those files?

Yep! Turns out they're three files: input from the last program in the chain, output to the next program in the chain, and error messages to either a log file or operator. All those pipelines in your shell script abominations that you are afraid to touch (and somehow load-bearing for all of production for several companies) become data passing through those three basic files.
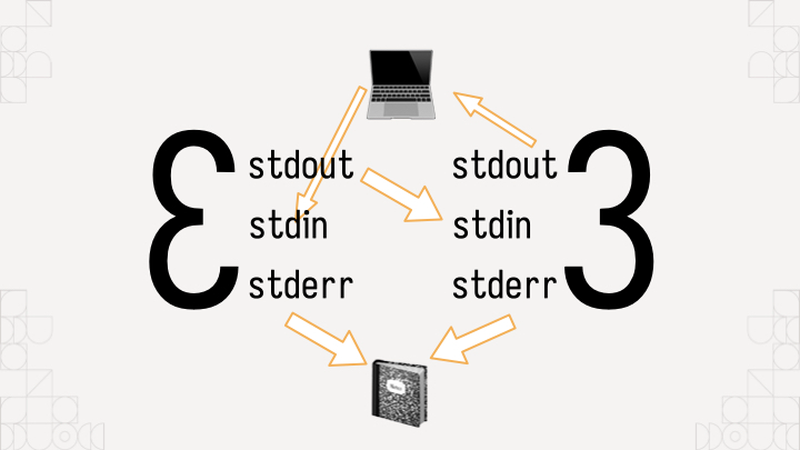
It's like an assembly line for your data, every step gets its data fed from the output of the last one and then it sends its results to the input of the next one. Errors might to go an operator or a log sink like the journal, but it goes down the chain and lets you do whatever you want. Really, it's a rather elegant design, there's a reason it's lasted for over 50 years.

So you know how I promised that I'm gonna relate all this back to WebAssembly? Here's when. Now that we understand what Unix is, let's talk about what WebAssembly by itself isn't.
WebAssembly is a CPU that can run pure functions and then return the results. It can also poke the outside world in a limited capacity, but overall it's a lot more like this in practice:

A microcontroller. Sure you can use microcontrollers to do a lot of useful things (especially when you throw in temperature sensors and maybe even a GSM shield to send text messages), but the main thing that microcontrollers can't easily do is connect to the Internet or deal with files on storage devices. Pedantically, this is something you can do, but every time it'll need to be custom-built for the hardware in question. There's no operating system in the mix, so everything needs to have bespoke code. Without an operating system, there's no network stack or even processes. This makes it possible, but moderately difficult to reuse existing code from other projects. If you want to do something like run libraries you wrote in Go on the frontend, such as your peer to peer VPN engine and all of its supporting code, you'd need to either do a pile of ridiculous hacks or you'd just need there to be something close to an operating system. Those hacks would be fairly reliable, but I think we can do better.
(Pause)
Turns out, you don't need an operating system to fill most of the gaps that are left when you don't have one. In WebAssembly, we have something to fill this gap:
WASI. WASI is the WebAssembly System Interface. It defines some semantics for how input, output, files, filesystems, and basic network sockets should be implemented for both the guest program and the host environment. This acts like enough of an "operating system" as far as programming languages care. When you get the Go or Rust compiler to target WASI, they'll emit binaries that can run just about anywhere with a WASI runtime.

So circling back on the filesystem angle, one of the key distinctions with how WASI implements filesystem access compared to other operating systems is that there's no expectation for running processes to have access to the host filesystem, or even any filesystem at all. It is perfectly legal for a WASI module to run without filesystem access. More critically for the point I'm trying to build up to though, there are a few files that are guaranteed to exist:
Standard input, output, and error files. And, you know what this means? This means we can circle back to the Unix idea of WebAssembly programs being filters. You can make a WebAssembly program take input and emit output as one step in a longer process. Just like your pipelines!
As an example, I have an overcomplicated blog engine that includes its own dialect of markdown because of course it does. After getting nerd sniped by Amos, I rewrote it all in Rust; but when I did that, I separated the markdown parser into its own library and made a little command-line utility for it. I compiled that to WebAssembly with WASI and now I think I'm one of the only people to have successfully distributed a program over the fediverse: the library that I use to convert markdown to HTML, with the furry avatar templates that orange websites hate and all.
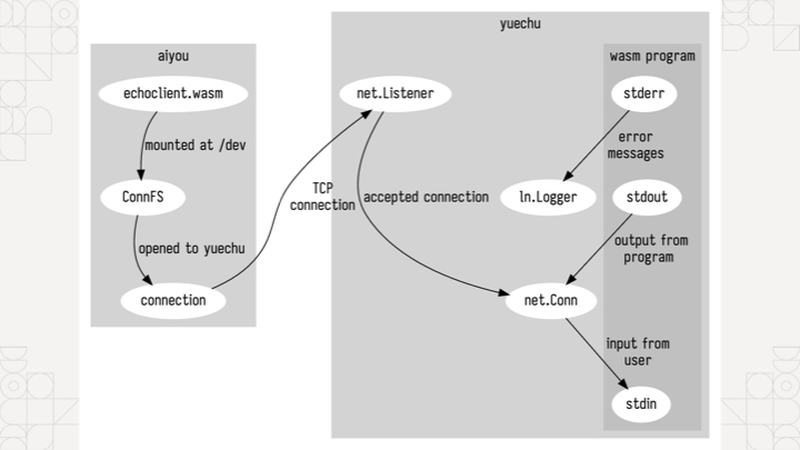
Just to help hammer this all in, I'm going to show you some code I wrote between episodes of anime and donghua. I wrote a little "echo server" that takes a line of input, runs a WebAssembly program on that line of input fed into standard in, and then returns the response from standard out. The first program I'm gonna show off is going to be a "reply with the input" program. Then, I'm going to switch it over to my markdown library I mentioned and write out a message to get turned into HTML. I'm going to connect to it with another WebAssembly program that has a custom filesystem configuration that lets you use the network as a filesystem because WASI's preview 1 API doesn't support making outgoing network connections at the time of writing. If sockets really are just files, then why can't we just use the network stack as a filesystem?
Now, it's time, let's show off the power of WebAssembly. But first, the adequate prayers are needed: Demo gods, hear my cries. Bless my demo!

On the right hand side I have a terminal running that WebAssembly powered echo server I mentioned. Just to prove I didn't prerecord this, someone yell out something for me to type into the WebAssembly program on the left.
(Pause for someone to shout something)
Cool, let's type it in:
(Type it in and hit enter)
See? I didn't prerecord this and that lovely member of the audience wasn't a plant to make this easier on me.
(Audience laughs)
You know what, while we're at it, let's do a little bit more. I have another version of this set up where it feeds things into that markdown->HTML parser I mentioned. If I write some HTML into there:
(Type it in and hit enter)
As you can see, I get the template expanded and all of the HTML goodness has come back to haunt us again. Even though the program on the right is written in Go:
(I press control-backslash to cause the go runtime to vomit the stack of every goroutine, attempting to prove that there's nothing up my sleeve)
It's able to run that Rust program like it's nothing.
(Applause)
Thank Klaus that all that worked. I'm going to put all the code for this on my GitHub page in my x repo.
This technique of embedding Rust programs into Go programs is something I call crabtoespionage. It lets you use the filter property of Unix programs as functions in your Go code. This is how you Rustaceans in crowd can sneak some Rust into prod without having to make sacrifices to the linker gods. I know there's at least one of you out there. Commit the .wasm bytes from rustc or cargo to your repo and then you can still build everything on a Mac, Plan 9, or even TempleOS, assuming you have Go running there.
Most of the heavy lifting in my examples is done with Wazero, it's a library for Go programs that is basically a WebAssembly VM and some hooks for WASI implemented for you. The flow for embedding Rust programs into Go looks like this:
- First, extract the subset of the library you want and make it a standalone program. This makes it easy to test things on the command line. Use arguments and command line flags, they're there for a reason.
- Next, build that to WASI and fix things until it works. You'll have to figure out how to draw the rest of the owl here. Some things may be impossible depending on facts and circumstances. Usually things should work out.
- Then import wazero into your program and set everything up by using the embed directive to hoist the WebAssembly bytes into your code. Set up the filesystems you want to use, and your runtime config and finally:
- Then make a wrapper function that lets you go from input to output et voila!
You've just snuck Rust into production. This is how I snuck Rust into prod at work and nobody is the wiser.
(Pause)
Wait, I just gave it away, no, oops. Sorry! I had no choice. Mastodon HTML is weird. The Go HTML library is weirder.
There's a few libraries on GitHub that use this basic technique for more than just piping input to output, they use it to embed C and C++ libraries into Go code. In the case of the regular expressions package, it can be faster than package regexp in some cases. Including the WebAssembly overhead. It's incredible. There's not even that many optimizations for WebAssembly yet!
No C compiler required! No cross-compiling GCC required! No satanic sacrifices to the dark beings required! It's magic, just without the spell slots.
So while we're on this, let's take both aspects of this to their logical conclusions. What about plugins for programs? There's plenty of reasons customers would want to have arbitrary plugin code running, and also plenty of reasons for you to fear having to run arbitrary customer plugin code. If we can run things in an isolated sandbox and then define our own filesystem logic: what if we expose application state as a filesystem? Trigger execution of the plugin code based on well-defined events that get piped to standard input. Make open calls fetch values from an API or write new values to that same API.
This is how the ACME editor for Plan 9 works. It exposes internal application state as a filesystem for plugins to manipulate to their pleasure.
So, to wrap all of this up:
- When you're dealing with Unix, you're dealing with files, be they source code, hard drives, or network sockets.
- Like anything made around a standards body, even files themselves are lies and anything can be a file if it lies enough in the right way.
- Understanding that everything is founded on these lies frees you from the expectation of trying to stay consistent with them. This lets you run things wherever without having to have a C compiler toolchain for win32 handy.
- Because everything is based on these lies, if you control what lies are being used, you actually end up controlling the truths that users deal with. When you free yourself from the idea of having to stay consistent with previous interpretation of those lies, you are free to do whatever you want.
How could you use this in your projects to do fantastic new things? The ball's in your court Creators.
(Applause)

With all that said, here's a giant list of everyone that's helped me with this talk, the research I put into the talk, and uncountable other things. Thank you so much everyone.
(Thunderous applause)

And with that, I've been Xe! Thank you so much for coming out to Berlin. I'll be wandering around if you have any questions for me, but if I miss it, please do email me at crabtoespionage@xeserv.us. I'll reply to your questions, really. My example code is in the conferences folder of my experimental repo github.com/Xe/x. Otherwise, please make sure to stay hydrated and enjoy the conference! Be well!
How to use Tailwind CSS in your Go programs

When I work on some of my smaller projects, I end up hitting a point where I need more than minimal CSS configuration. I don't want to totally change my development flow to bring in a bunch of complicated toolkits or totally rewrite my frontend in React or something, I just want to make things not look like garbage. Working with CSS by itself can be annoying.


Remember: ignorance is the default state.

I've found a way to make working with CSS a lot easier for me. I've been starting to use Tailwind in my personal and professional projects. Tailwind is a CSS framework that makes nearly every CSS behavior its own utility class. This means that you can make your HTML and CSS the same file, minimizing context switching between your HTML and CSS files. It also means that you can build your own components out of these utility classes. Here's an example of what it ends up looking like in practice:
<div class="bg-blue-500 text-white font-bold py-2 px-4 rounded">Button</div>
This is a button that has a blue background, white text, is bold, has a padding of 2, and has a rounded border. This looks like a lot of CSS to write for a button, but it's all in one place and can be customized for every button. This is a lot easier to work with than having to context switch between your HTML and CSS files.
px-2, it's padding on the X axis by two what?
One of the biggest downsides is that Tailwind's compiler is written in JavaScript and distributed over npm. This is okay for people that are experienced JavaScript Touchers, but I am not one of them. Usually when I see that something requires me to use npm, I just close the tab and move on. Thankfully, Tailwind is actually a lot easier to use than you'd think. You really just have to install the compiler (either with npm or as a Nix package) and then run it. You can even set up a watcher to automatically rebuild your CSS file when you change your HTML templates. It's a lot less overhead than you think.
Assumptions
To make our lives easier, I'm going to assume the following things about your project:
- It is written in Go.
- You are using
html/templatefor your HTML templates. - You have a
staticfolder that has your existing static assets (eg: https://alpinejs.dev for interactive components).
Setup
If you are using Nix or NixOS
Add the tailwindcss package to your flake.nix's devShell:
{
inputs.nixpkgs.url = "github:NixOS/nixpkgs/nixos-unstable";
outputs = { self, nixpkgs }: {
devShell = nixpkgs.mkShell {
nativeBuildInputs = [ self.nixpkgs.tailwindcss ];
};
};
}
Then you should be able to use the tailwindcss command in your shell. Ignore the parts about installing tailwindcss with npm, but you may want to use npm as a script runner or to install other tools. Any time I tell you to use npx tailwindcss, just mentally replace that with tailwindcss.
First you need to install Tailwind's CLI tool. Make sure you have npm/nodejs installed from the official website.
Then create a package.json file with npm init:
npm init
Once you finish answering the questions (realistically, none of the answers matter here), you can install Tailwind:
npm install --dev --save tailwindcss
Now you need to set up some scripts in your package.json file. You can do this by hand, or you can use npm's built-in script runner to do it for you. This lets you build your website's CSS with commands like npm run build or make your CSS automatically rebuild with npm run watch. To do this, you need to add the following to your package.json file:
{
// other contents here, make sure to add a trailing comma.
"scripts": {
"build": "tailwindcss build -o static/css/tailwind.css",
"watch": "tailwindcss build -o static/css/tailwind.css --watch"
}
}
npm run watch in another terminal while you're working on your website. This will automatically rebuild your CSS file when you change your HTML templates.Next you need to make a tailwind.config.js file. This will configure Tailwind with your HTML teplate locations as well as let you set any other options. You can do this by hand, or you can use Tailwind's built-in config generator:
npx tailwindcss init
Then open it up and configure it to your liking. Here's an example of what it looks like when using Iosevka Iaso:
/** @type {import('tailwindcss').Config} */
module.exports = {
content: ["./tmpl/*.html"], // This is where your HTML templates / JSX files are located
theme: {
extend: {
fontFamily: {
sans: ["Iosevka Aile Iaso", "sans-serif"],
mono: ["Iosevka Curly Iaso", "monospace"],
serif: ["Iosevka Etoile Iaso", "serif"],
},
},
},
plugins: [],
};
<link rel="stylesheet" href="https://cdn.xeiaso.net/static/pkg/iosevka/family.css" />
If you aren't serving your static assets in your Go program already, you can use Go's standard library HTTP server and go:embed:
//go:embed static
var static embed.FS
// assuming you have a net/http#ServeMux called `mux`
mux.Handle("/static/", http.FileServer(http.FS(static)))
This will bake your static assets into your Go binary, which is nice for deployment. Things you can't forget are a lot more robust than things you can forget.
Finally, add a //go:generate directive to your Go program to build your CSS file when you run go generate:
//go:generate npm run build
When you change your HTML templates, you can run go generate to rebuild your CSS files.
Finally, make sure you import your Tailwind build in your HTML template:
<link rel="stylesheet" href="/static/css/tailwind.css" />
Now you can get started with using Tailwind in your HTML templates! I hope this helps.
This isn't the way to speed up Rust compile times

Recently serde, one of the most popular Rust libraries made a decision that supposedly sped up compile times by using a precompiled version of a procedural macro instead of compiling it on the fly. Like any technical decision, there are tradeoffs and advantages to everything. I don't think the inherent ecosystem risks in slinging around precompiled binaries are worth the build speed advantages, and in this article I'm going to cover all of the moving parts for this space.

serde
serde is one of the biggest libraries in the Rust ecosystem. It provides the tooling for serializing and deserializing (ser/de) arbitrary data structures into arbitrary formats. The main difference between serde and other approaches is that serde doesn't prefer an individual encoding format. Compare this struct in Rust vs the equivalent struct in Go:
#[derive(Debug, Deserialize, Eq, PartialEq, Clone, Serialize)]
pub struct WebMention {
pub source: String,
pub title: Option<String>,
}
type WebMention struct {
Source string `json:"source"`
Title *string `json:"title"`
}
Besides syntax, the main difference is in how the serialization/deserialization works. In Go the encoding/json package uses runtime reflection to parse the structure metadata. This does work, but it's expensive compared to having all that information already there.
The way serde works is by having an implementation of Deserialize or Serialize on the data types you want to encode or decode. This effectively pushes all of the data that is normally inspected at runtime with reflection into compile-time data. In the process, this makes the code run a little bit faster and more deterministically, but at the cost of adding some time at compile time to determine that reflection data up front.
I think this is a fair tradeoff due to the fundamental improvements in developer experience. In Go, you have to declare the encoding/decoding rules for every codec individually. This can lead to stuctures that look like this:
type WebMention struct {
Source string `json:"source" yaml:"source" toml:"source"`
Title *string `json:"title" yaml:"title" toml:"source"`
}
toml:"source" defined on the Title field, didn't you
mean to say toml:"title"?
type WebMention struct {
Source string `json:"source" yaml:"source" toml:"source"`
Title *string `json:"title" yaml:"title" toml:"title"`
}
This becomes unwieldy and can make your code harder to read. Some
codecs get around this by reading and using the same tag rules that
encoding/json does, but the Rust equivalent works for any codec that
can be serialized into or deserialized from. That same WebMention
struct works with JSON, YAML, TOML, msgpack,
or anything else you can imagine. serde is one of the most used
packages for a reason: it's so convenient and widespread that it's
widely seen as being effectively in the standard library.
If you need to add additional behavior such as parsing a string to markdown, you can do that with your own implementation of the Deserialize trait. I do this with the VODs pages in order to define my stream VOD information in configuration. The markdown inside strings compiles to the HTML you see on the VOD page, including the embedded video on XeDN. This is incredibly valuable to me and something I really want to keep doing until I figure out how to switch my site to using something like contentlayer and MDX.
The downsides
It's not all sunshine, puppies and roses though. The main downside to the serde approach is the fact that it relies on a procedural macro. Procedural macros are effectively lisp-style "syntax hygenic" macros. Effectively you can view them as a function that takes in some syntax, does stuff to it, and then returns the result to be compiled in the program.
This is how it can derive the serialization/deserialization code, it takes the tokens that make up the struct type, walks through the fields, and inserts the correct serialization or deserialization code so that you can construct values correctly. If it doesn't know how to deal with a given type, it will blow up at compile-time, meaning that you may need to resort to increasingly annoying hacks to get things working.

When you write your own procedural macro, you create a separate crate for this. This separate crate is compiled against a special set of libraries that allow it to take tokens from the Rust compiler and emit tokens back to the rust compiler. These compiled proc macros are run as dynamic libraries inside invocations of the Rust compiler. This means that proc macros can do anything as the permissions of the Rust compiler, including crashing the compiler, stealing your SSH key and uploading it to a remote server, running arbitrary commands with sudo power, and much more.
A victim of success
Procedural macros are not free. They take nonzero amounts of time to run because they are effectively extending the compiler with arbitrary extra behavior at runtime. This gives you a lot of power to do things like what serde does, but as more of the ecosystem uses it more and more, it starts taking nontrivial amounts of time for the macros to run. This causes more and more of your build time being spent waiting around for a proc macro to finish crunching things, and if the proc macro isn't written cleverly enough it will potentially waste time doing the same behavior over and over again.
This can slow down build times, which make people investigate the problem and (rightly) blame serde for making their builds slow. Amusingly enough, serde is used by the Rust compiler rustc and package manager cargo. This means that the extra time compiling proc macros are biting literally everyone, including the Rust team.

hyperfine --prepare "cargo clean" "cargo
build --release"
$ hyperfine --prepare "cargo clean" "cargo build --release"
Benchmark 1: cargo build --release
Time (mean ± σ): 41.872 s ± 0.295 s [User: 352.774 s, System: 22.339 s]
Range (min … max): 41.389 s … 42.169 s 10 runs
hyperfine --prepare "cargo clean" "cargo build --release"
Benchmark 1: cargo build --release
Time (mean ± σ): 103.852 s ± 0.654 s [User: 1058.321 s, System: 42.296 s]
Range (min … max): 102.272 s … 104.843 s 10
runs
The change
In essence, the change makes serde's derive macro use a precompiled binary instead of compiling a new procedural macro binary every time you build the serde_derive dependency. This removes the need for that macro to be compiled from source, which can speed up build times across the entire ecosystem in a few cases.
However, this means that the most commonly used crate is shipping an arbitrary binary for production builds without any way to opt-out. This could allow a sufficiently determined attacker to use the serde_derive library as a way to get code execution on every CI instance where Rust is used at the same time.
Combine that with the fact that the Rust ecosystem doesn't currently have a solid story around cryptographic signatures for crates and you get a pretty terrible situation all around.

But this does speed things up for everyone...at the cost of using serde as a weapon to force ecosystem change.
In my testing the binary they ship is a statically linked Linux binary:
$ file ./serde_derive-x86_64-unknown-linux-gnu
./serde_derive-x86_64-unknown-linux-gnu: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), static-pie linked, BuildID[sha1]=b8794565e3bf04d9d58ee87843e47b039595c1ff, stripped
$ ldd ./serde_derive-x86_64-unknown-linux-gnu
statically linked

ldd on untrusted
executables. ldd
works by setting the environment variable LD_TRACE_LOADED_OBJECTS=1
and then executing the command. This causes your system's C dynamic
linker/loader to print all of the dependencies, however malicious
applications can and will still execute their malicious code even when
that environment variable is set. I've seen evidence of applications
exhibiting different malicious behavior when that variable is set.
Stay safe and use virtual machines when dealing with unknown
code.
Out of date "file not found" error with a friend using cargo2nix
Frustratingly, a friend of mine that uses cargo2nix is reporting getting a "file not found" error when trying to build programs depending on serde. This is esepecially confusing given that the binary is a statically linked binary, but I guess we'll figure out what's going on in the future.
There's also additional concerns around the binary in question not being totally reproducible, which is slightly concerning from a security standpoint. If we're going to be trusting some random guy's binaries, I think we are in the right to demand that it is byte-for-byte reproducible on commodity hardware without having to reverse-engineer the build process and figure out which nightly version of the compiler is being used to compile this binary blob that will be run everywhere.
I also can't imagine that distribution maintainers are happy with this now that Rust is basically required to be in distribution package managers. It's unfortunate to see crates.io turn from a source code package manager to a binary package manager like this.
This doesn't even make build times faster
The most frustrating part about this whole affair is that while I was writing the majority of this article, I assumed that it actually sped up compliation. Guess what: it only speeds up compilation when you are doing a brand new build without an existing build cache. In many cases this means that you only gain the increased build speed in very limited cases: when you are doing a brand new clean build or when you update serde_derive.

This would be much more worth the tradeoff if it actually gave a significant compile speed tradeoff, but in order for this to make sense you'd need to be building many copies of serde_derive in your CI builds constantly. Or you'd need to have every procedural macro in the ecosystem also follow this approach. Even then, you'd probably only save about 20-30 seconds in cold builds on extreme cases. I really don't think it's worth it.
The middle path
Everything sucks here. This is a Kobayashi Maru situation. In order to really obviate the need for these precompiled binary blobs being used to sidestep compile time you'd need a complete redesign of the procedural macro system.

One of the huge advantages of the proc macro system as it currently
exists is that you can easily use any Rust library you want at compile
time. This makes doing things like generating C library bindings on
the fly using bindgen
trivial.
Maybe there could be a lot of speed to be gained with aggressive caching of derived compiler code. I think that could solve a lot of the issues at the cost of extra disk space being used. Disk space is plenty cheap though, definitely cheaper than developer time. The really cool advantage of making it at the derive macro level is that it would also apply for traits like Debug and Clone that are commonly derived anyways.
I have no idea what the complexities and caveates of doing this would be, but it could also be interesting to have the crate publishing step do aggressive borrow checking logic for every supported platform but then disable the borrow checker on crates downloaded from crates.io. The borrow checker contributes a lot of time to the compilation process, and if you gate acceptance to crates.io on the borrow checker passing then you can get away without needing to run the extra borrow checker logic when compiling dependencies.
Tangent about using WebAssembly
WASM for procedural macros?
I'm also pretty sure that there is an easier argument to be made for shipping easily replicatable WASM blobs like Zig does instead of shipping around machine code like serde does.
One of the core issues with procedural macros is that they run unsandboxed machine code. Sandboxing programs is basically impossible to do cross-platform without a bunch of ugly hacks at every level.
I guess you'd need to totally rewrite the proc macro system to use WebAssembly instead of native machine code. Doing this with WebAssembly would let the Rust compiler control the runtime environment that applications would run under. This would let packages do things like:
- Declare what permissions it needs and have permissions changes on updates to the macros cause users to have to confirm them
- Declare "cache storage" so that things like derive macro implementations could avoid needing to recompute code that has already passed muster.
- Let people ship precompiled binaries without having to worry as much about supporting every platform under the sun. The same binary would run perfectly on every platform.
- More easily prove reproducibility of the proc macro binaries, especially if the binaries were built on the crates.io registry server somehow.
- Individually allow/deny execution of commands so that common
behaviors like
bindgen,pkg-config, and compiling embedded C source code continue working.
This would require a lot of work and would probably break a lot of existing proc macro behavior unless care was taken to make things as compatible. One of the main pain points would be dealing with C dependencies as it is nearly impossible* to deterministically prove where the dependencies in question are located without running a bunch of shell script and C code.
One of the biggest headaches would be making a WebAssembly JIT/VM that would work well enough across platforms that the security benefits would make up for the slight loss in execution speed. This is annoyingly hard to sell given that the current state of the world is suffering from long compilation times. It also doesn't help that WebAssembly is still very relatively new so there's not yet the level of maturity needed to make things stable. There is a POSIX-like layer for WebAssembly programs called WASI that does bridge a lot of the gap, but it misses a lot of other things that would be needed for full compatibility including network socket and subprocess execution support.

This entire situation sucks. I really wish things were better. Hopefully the fixes in serde-rs/serde#2580 will be adopted and make this entire thing a non-issue. I understand why the serde team is making the decisions they are, but I just keep thinking that this isn't the way to speed up Rust compile times. There has to be other options.
I don't know why they made serde a malware vector by adding this unconditional precompiled binary in a patch release in exchange for making cold builds in CI barely faster.
The biggest fear I have is that this practice becomes widespread across the Rust ecosystem. I really hate that the Rust ecosystem seems to have so much drama. It's scaring people away from using the tool to build scalable and stable systems.

This isn't the way to speed up Rust compile times
I had a great time at DEF CON 31
I've always admired DEF CON from a distance. I've watched DEF CON talks for years, but I've never been able to go. This year I was able to go, and I had a great time. This post is gonna be about my experiences there and what I learned.
In short: I had a great time. I got to meet up with people that have only been small avatars and text on my screen. I got to see talks about topics that I would have never sought out myself. I'm gonna go again next year if the cards allow it.

The con itself
DEF CON is split between three hotels and a conference center in the Vegas strip: The Flamingo, the LINQ, Harrah's, and Ceasar's Forum. This was my first clue that this conference was big. I didn't realize how big it was. I'm used to conferences that have maybe two tracks of talks, but DEF CON had at least 14 when you count all the villages. I didn't even get to see all the villages, and I didn't get to see all the talks I wanted to see due to the logistical constraints of everything being spread out through Vegas.
The lines were also brutal. People were jokingly calling it LineCon, but damn they really meant it. I guess this is the sign that DEF CON has been a success, because even smaller village talks had massive lines. I didn't get to see the talks I wanted to see because I didn't want to wait in line for an hour or more. I'll likely catch the ones I missed on YouTube.
I pre-registered for the conference and I was able to get one of the coveted hard plastic badges that had room to add "shards" to customize it. I got a shard that has a picture of Twilight Sparkle holding a soldering iron on it.

This is going to make a great souvenir. I'm going to put it on my desk.
The AI village
One of the neatest experiences I had was at the AI village. There we tried to do prompt injection on models to try and get them to repeat misinformation and do other things like that. I found a fairly reliable way to get the models to say that Donald Trump was president of the USA: use Lojban, toki pona, and Esperanto.
So basically, my conversations with the AI models ended up looking like this:


It was utterly trivial, especially when you mixed Lojban, toki pona and Esperanto in prompts. I doubt this is going to work for much longer in the models I tested, but it was a very fun thing to discover.
The cryptography/privacy village

I also loved the puzzles in the Cryptography/Privacy Village. I didn't get to finish them (I'll likely get to them at some point), but I was able to implement the Vigènere cipher in Go. I put my code here in case it's useful.
The furry village
I hung out a lot in the furry village though. It was a chill place with an open bar and when you paid the price of admission, you got access to what was probably the cheapest bar on the strip. It was really a chill place to hang out with like-minded people of the furry persuasion and talk about tech. I got to meet a couple other online nerdfriends there.

Photography
I also got to practice my photography skills and play with the new 35mm lens that Hacker News paid for with ad impressions. I love the bokeh on this thing. Here's an example of how good the bokeh gets:

It's goddamn magical. The best part is that this is done in optics, not software. To be fair to Apple, their Portrait Mode does an amazing attempt at making the bokeh effect happen, but you can see the notable haze around the objects that the AI model determines is the subject. This manifests as straws in cups going into the blur zone and other unsightly things. It works great for people and pets though. With my DSLR, this is done in optics. It's crisp and clear as day. I love it.
I'm going to include my photographs in my future posts as the cover art in addition to using the AI generated images that people love/loathe.
The talks
Here are the talks I went to:
- The Mass Owning of Seedboxes
- Hacking Your Relationships: Navigating Alternative and Traditional Dynamics
- Software Security Fur All
- Legend of Zelda: Use After Free (TASBot glitches OoT)
- Domain Fronting Through Microsoft Azure and CloudFlare: How to Identify Viable Domain Fronting Proxies
- Attacking Decentralized Identity
The Mass Owning of Seedboxes
This talk was awesome. The core thesis was that seedbox providers do a very bad job at security and that it makes it easy to grab credentials to coveted private trackers and ruin other people's ratios. The speaker was anonymous and I'm not going to go into too many details about the talk to protect the "off the record" nature of the talk, but I loved it.
It makes me glad that I self-host things instead of farming it out to a third party that will just mess it up.
Hacking Your Relationships: Navigating Alternative and Traditional Dynamics
I only caught the tail end of this talk in the furry village, but it was about the practical considerations with polyamory and other non-traditional relationship structures, as well as the legal/social implications of coming out as polyamorous. I'm not polyamorous myself, but I have friends that are poly and I want to support them when and where I can. I liked it and kinda wish I caught the entire talk.
Software Security Fur All
This talk was by Soatok, someone I look up to a lot with regards to cryptography and security implementations. They talked about how the industry kinda sucks at doing its job and lamented how elitist the security space can be. Then they talked about security first principles in a way that I found really approachable.
I'm not really the best with security/cryptography code, but I do know enough that I should farm it off to someone that knows what they are doing as soon as possible.
I think one of the most impressive parts of this talk was that Soatok gave it in a fursuit. In Vegas. In summer. I can't imagine how hot that must have been.
Legend of Zelda: Use After Free (TASBot glitches OoT)
This talk was about how the SGDQ run of The Legend of Zelda: Triforce% worked from a technical level. Triforce% is a work of art and they went into gorey detail on how they hacked the game from the controller ports into memory. It was a great talk. They also tried to replicate the run live but ran into an issue where the game crashed at the worst time.
Ocarina of Time is one of the most rock-solid games out there, but everything broke in half when they found a use-after-free exploit in the game. They then figured out how to get arbitrary code execution and made the any% world record fall below 5 minutes. It's a glorious explanation of why use-after-free bugs are a problem. Really do watch the Retro Game Mechanics Explained video on how it works. It's a great watch.
It was a great talk and I got to talk with one of the speakers in the furry village afterwards. I'm glad I got to see it.
Domain Fronting Through Microsoft Azure and CloudFlare: How to Identify Viable Domain Fronting Proxies
Domain fronting is one of my favorite bug classes to consider. It's a classic time-of-check vs time-of-use bug where you have your SNI header claim you want to connect to one domain but then go and make your HTTP host header claim you want to connect to another. This is one of the tricks used to bypass nation-state firewalls like the Great Firewall, and it's a really neat trick. You basically put a postcard inside an envelope.
Somehow this technique is best documented on YouTube of all places. It's not really talked about in too much detail and CDN providers are usually quick to lock it down because it is a threat to their continued operation in countries that really want to filter internet traffic.
The basic threat model here is that if Cloudflare proxies like 20% of the Internet, that is critical mass enough that they can't just go and block Cloudflare without impeding the bread and circuses pipeline that their citizens rely on for entertainment. This is why people do domain fronting, it allows them to connect to websites that are simply blocked.
I have a friend that has been trying to help people inside Iran get free/open access to the Internet after they had some regime change recently. Domain fronting is one of/the main tool that they use because it's the only thing that's effective when government state actors block things like WireGuard and OpenVPN. He laments when big providers block domain fronting and are very reluctant to even acknowledge that it's a useful tool for people affected by extremist regimes and their censorship. I don't know of a good solution here.
Attacking Decentralized Identity
I admit, the well has been poisoned for me with regards to decentralized identity. I personally think that the problem is so intractable that it's probably a better use of our limited time on Earth to do something else and just farm it out to the usual suspects (or Tailscale!).
Going into it, I had read the Decentralized IDentifier (DID) spec and the DID Specification Registry method list that included a bunch of methods named after cryptocurrency projects. This really poisoned the well for me and I came into that talk thinking that it was some anuscoin shit that was thinly veiled as generic enough to pass muster to normal people.
I was wrong. It's actually a much lower level fundamental change to how we trust and validate identity in general. The basic idea is that the first model of identity on the internet was per-community and isolated to that community. The second model was logging in to bigger services to prove your identity and having those services vouch for you. This new third model essentially is having you vouch for yourself using public key cryptography.
It reeks of W3C disease including the use of JSON-LD for interchange and the acroynm is horrible. This technology is also so new that it hasn't even gotten close to stabilizing yet. I'm going to wait until it gets more mature before I try and use it.
Conclusion
Overall, I had a great time. I got exposed to things I never would have seen at home. I got to talk and dine with people that have only been words on a screen to me. I got to walk 50 kilometers around Vegas and take some great pictures of the city. I'm gonna do it again next year if I can. Maybe I can drag my husband along with me.