Reading List
The most recent articles from a list of feeds I subscribe to.
Reckoning: Part 4 — The Way Out
Other posts in the series:
Frontend took ill with a bad case of JavaScript fever at the worst possible moment. The predictable consequence is a web that feels terrible most of the time, resulting in low and falling use of the web on smartphones.1

If nothing changes, eventually, the web will become a footnote in the history of computing; a curio along side mainframes and minicomputers — never truly gone but lingering with an ashen palour and a necrotic odour.
We don't have to wait to see how this drama plays out to understand the very real consequences of JavaScript excess on users.2
Everyone in a site's production chain has agency to prevent disaster. Procurement leads, in-house IT staff, and the managers, PMs, and engineers working for contractors and subcontractors building the SNAP sites we examined all had voices that were more powerful than the users they under-served. Any of them could have acted to steer the ship away from the rocks.
Unacceptable performance is the consequence of a chain of failures to put the user first. Breaking the chain usually requires just one insistent advocate. Disasters like BenefitsCal are not inevitable.
The same failures play out in the commercial teams I sit with day-to-day. Failure is not a foregone conclusion, yet there's an endless queue of sites stuck in the same ditch, looking for help to pull themselves out. JavaScript overindulgence is always an affirmative decision, no matter how hard industry "thought leaders" gaslight us.
Marketing that casts highly volatile, serially failed frontend frameworks as "standard" or required is horse hockey. Nobody can force an entire industry to flop so often it limits its future prospects.
These are choices.
Teams that succeed resolve to stand for the users first, then explore techniques that build confidence.
So, assuming we want to put users first, what approaches can even the odds? There's no silver bullet,3 but some techniques are unreasonably effective.
Managers
Engineering managers, product managers, and tech leads can make small changes to turn the the larger ship dramatically.
First, institute critical-user-journey analysis.
Force peers and customers to agree about what actions users will take, in order, on the site most often. Document those flows end-to-end, then automate testing for them end-to-end in something like WebPageTest.org's scripting system. Then define key metrics around these journeys. Build dashboards to track performance end-to-end.
Next, reform your frontend hiring processes.
Never, ever hire for JavaScript framework skills. Instead, interview and hire only for fundamentals like web standards, accessibility, modern CSS, semantic HTML, and Web Components. This is doubly important if your system uses a framework.
The push-back to this sort of change comes from many quarters, but I can assure you from deep experience that the folks you want to hire can learn anything, so the framework on top of the platform is the least valuable part of any skills conversation. There's also a glut of folks with those talents on the market, and they're vastly underpriced vs. their effectiveness, so "ability to hire" isn't a legitimate concern. Teams that can't find those candidates aren't trying.
Some teams are in such a sorry state regarding fundamentals that they can't even vet candidates on those grounds. If that's your group, don't hestitate to reach out.
In addition to attracting the most capable folks at bargain-basement prices, delivering better work more reliably, and spending less on JavaScript treadmill taxes, publicising these criteria sends signals that will attract more of the right talent over time. Being the place that "does it right" generates compound value. The best developers want to work in teams that prize their deeper knowledge. Demonstrate that respect in your hiring process.
Next, issue every product and engineering leader cheap phones and laptops.
Senior leaders should set the expectation those devices will be used regularly and for real work, including visibly during team meetings. If we do not live as our customers, blind spots metastasise.
Lastly, climb the Performance Management Maturity ladder, starting with latency budgets for every project, based on the previously agreed critical user journeys. They are foundational in building a culture that does not backslide.
Engineers and Designers
Success or failure is in your hands, literally. Others in the equation may have authority, but you have power.
Begin to use that power to make noise. Refuse to go along with plans to build YAJSD (Yet Another JavaScript Disaster). Engineering leaders look to their senior engineers for trusted guidance about what technologies to adopt. When someone inevitably proposes the React rewrite, do not be silent. Do not let the bullshit arguments and nonsense justifications pass unchallenged. Make it clear to engineering leadership that this stuff is expensive and is absolutely not "standard".
Demand bakeoffs and testing on low-end devices.
The best thing about cheap devices is they're cheap! So inexpensive that you can likely afford a low-end phone out-of-pocket, even if the org doesn't issue one. Alternatively, WebPageTest.org can generate high-quality, low-noise simulations and side-by-side comparisons of the low-end situation.
Write these comparisons into testing plans early.
Advocate for metrics and measurements that represent users at the margins.
Teams that have climbed the Performance Management Maturity ladder intuitively look at the highest percentiles to understand system performance. Get comfortable doing the same, and build that muscle in your engineering practice.
Build the infrastructure you'll need to show, rather than tell. This can be dashboards or app-specific instrumentation. Whatever it is, just build it. Nobody in a high-performing engineering organisation will be ungrateful for additional visibility.
Lastly, take side-by-side traces and wave them like a red shirt.
Remember, none of the other people in this equation are working to undercut users, but they rely on you to guide their decisions. Be a class traitor; do the right thing and speak up for users on the margins who can't be in the room where decisions are made.
Public Sector Agencies
If your organisation is unfamiliar with the UK Government Digital Service's excellent Service Manual, get reading.
Once everyone has put their copy down, institute the UK's progressive enhancement standard and make it an enforceable requirement in procurement.4 The cheapest architecture errors to fix are the ones that weren't committed.
Next, build out critical-user-journey maps to help bidders and in-house developers understand system health. Insist on dashboards to monitor those flows.
Use tender processes to send clear signals that proposals which include SPA architectures or heavy JS frameworks (React, Angular, etc.) will face acceptance challenges.
Next, make space in your budget to hire senior technologists and give them oversight power with teeth.
The root cause of many failures is the continuation of too-big-to-fail contracting. The antidote is scrutiny from folks versed in systems, not only requirements. An effective way to build and maintain that skill is to stop writing omnibus contracts in the first place.
Instead, farm out smaller bits of work to smaller shops across shorter timelines. Do the integration work in-house. That will necessitate maintaining enough tech talent to own and operate these systems, building confidence over time.
Reforming procurement is always challenging; old habits run deep. But it's possible to start with the very next RFP.
Values Matter
Today's frontend community is in crisis.
If it doesn't look that way, it's only because the instinct to deny the truth is now fully ingrained. But the crisis is incontrovertable in the data. If the web had grown at the same pace as mobile computing, mobile web browsing would be more than a 1/3 larger than it is today. Many things are holding the web back — Apple springs to mind — but pervasive JavaScript-based performance disasters are doing their fair share.
All of the failures I documented in public sector sites are things I've seen dozens of times in industry. When an e-commerce company loses tens or hundreds of millions of dollars because the new CTO fired the old guard out to make way for a bussload of Reactors, it's just (extremely stupid) business. But the consequences of frontend's accursed turn towards all-JavaScript-all-the-time are not so readily contained. Public sector services that should have known better are falling for the same malarkey.
Frontend's culture has more to answer for than lost profits; we consistently fail users and the companies that pay us to serve them because we've let unscrupulous bastards sell snake oil without consequence.
Consider the alternative.
Canadian engineers graduating college are all given an iron ring. It's a symbol of professional responsibility to society. It also recognises that every discipline must earn its social license to operate. Lastly, it serves as a reminder of the consequences of shoddy work and corner-cutting.

I want to be a part of a frontend culture that accepts and promotes our responsibilities to others, rather than wallowing in self-centred "DX" puffery. In the hierarchy of priorities, users must come first.
What we do in the world matters, particularly our vocations, not because of how it affects us, but because our actions improve or degrade life for others. It's hard to imagine that culture while the JavaScript-industrial-complex has seized the commanding heights, but we should try.
And then we should act, one project at a time, to make that culture a reality.
Thanks to Marco Rogers, and Frances Berriman for their encouragement in making this piece a series and for their thoughtful feedback on drafts.
Users and businesses aren't choosing apps because they love downloading apps. They're choosing them because experiences built with these technologies work as advertised as least as often as they fail.
The same cannot be said for contemporary web development. ⇐
This series is a brief, narrow tour of the consequences of these excesses. Situating these case studies in the US, I hope, can dispel the notion that "the problem" is "over there".
It never was and still isn't. Friends, neighbours, and family all suffer when we do as terrible a job as has now become normalized in the JavaScript-first frontend conversation. ⇐
Silver bullets aren't possible at the technical level, but culturally, giving a toss is always the secret ingreedient. ⇐
Exceptions to a blanket policy requiring a Progressive Enhancement approach to frontend development should be carved out narrowly and only for sub-sections of progressively enhanced primary interfaces.
Specific examples of UIs that might need islands of non-progressively enhanced, JavaScript-based UI include:
- Visualisations, including GIS systems, complex charting, and dashboards.
- Editors (rich text, diagramming tools, image editors, IDEs, etc.).
- Real-time collaboration systems.
- Hardware interfaces to legacy systems.
- Videoconferencing.
In cases where an exception is granted, a process must be defined to characterise and manage latency. ⇐
Reckoning: Part 3 — Caprock
Other posts in the series:
Last time, we looked at how JavaScript-based web development compounded serving errors on US public sector service sites, slowing down access to critical services. These defects are not without injury. The pain of accessing SNAP assistance services in California, Massachusetts, Maryland, Tennessee, New Jersey, and Indiana likely isn't dominated by the shocking performance of their frontends, but their glacial delivery isn't helping.
Waits are a price that developers ask users to pay and loading spinners only buy so much time.
Complexity Perplexity
These SNAP application sites create hurdles to access because the departments procuring them made or green-lit inappropriate architecture choices. In fairness, those choices may have seemed reasonable given JavaScript-based development's capture of the industry.
Betting on JavaScript-based, client-side rendered architectures leads to complex and expensive tools. Judging by the code delivered over the wire, neither CalSAWS nor Deloitte understand those technologies well enough to operate them proficiently.
From long experience and a review of the metrics (pdf) the CalSAWS Joint Management Authority reports, it is plain as day that the level of organisational and cultural sophistication required to deploy a complex JavaScript frontend is missing in Sacramento:
It's safe to assume a version of the same story played out in Annapolis, Nashville, Boston, Trenton, and Indianapolis.
JavaScript-based UIs are fundamentally more challenging to own and operate because the limiting factors on their success are outside the data center and not under the control of procuring teams. The slow, flaky networks and low-end devices that users bring to the party define the envelope of success for client-side rendered UI.
This means that any system that puts JavaScript in the critical path starts at a disadvantage. Not only does JavaScript cost 3x more in processing power, byte-for-byte, than HTML and CSS, but it also removes the browser's ability to parallelise page loading. SPA-oriented stacks also preload much of the functionality needed for future interactions by default. Preventing over-inclusion of ancilliary code generally requires extra effort; work that is not signposted up-front or well-understood in industry.
This, in turn, places hard limits on scalability that arrive much sooner than with HTML-first progressive enhancement.
Consider today's 75-percentile mobile phone1, a device like the Galaxy A50 or the Nokia G100:

This isn't much of a an improvement on the Moto G4 I recommended for testing in 2016, and it's light years from the top-end of the market today.
A device like this presents hard limits on network, RAM, and CPU resources. Because JavaScript is more expensive than HTML and CSS to process, and because SPA architectures frontload script, these devices create a cap on the scalability of SPAs.2 Any feature that needs to be added once the site's bundle reaches the cap is in tension with every other feature in the site until exotic route-based code-splitting tech is deployed.
JavaScript bundles tend to grow without constraint in the development phase and can easily tip into territory that creates an unacceptable experience for users on slow devices.
Only bad choices remain once a project has reached this state. I have worked with dozens of teams surprised to have found themselves in this ditch. They all feel slightly ashamed because they've been led to believe they're the first; that the technology is working fine for other folks.3 Except it isn't.
I can almost recite the initial remediation steps in my sleep.4
The remaining options are bad for compounding reasons:
- Digging into an experience that has been broken with JS inevitably raises a litany of issues that all need unplanned remediation.
- Every new feature on the backlog would add to, rather than subtract from, bundle size. This creates pressure on management as feature work grinds to a halt.
- Removing code from the bundle involves investigating and investing in new tools and deeply learning parts of the tower of JS complexity everyone assumed was "fine".
These problems don't generally arise in HTML-first, progressively-enhanced experiences because costs are lower at every step in the process:
- HTML and CSS are byte-for-byte cheaper for building an equivalent interface.
- "Routing" is handled directly by the browser and the web platform through forms, links, and REST. This removes the need to load code to rebuild it.
- Component definitions can live primarily on the server side, reducing code sent to the client.
- Many approaches to progressive enhancement (rather than "rehydration") use browser-native Web Components, eliminating both initial and incremental costs of larger, legacy-oriented frameworks.
- Because there isn't an assumption that script is critical to the UX, users succeed more often when it isn't there.
This model reduces the initial pressure level and keeps the temperature down by limiting the complexity of each page to what's needed.
Teams remediating underperforming JavaScript-based sites often make big initial gains, but the difficulty ramps up once egregious issues are fixed. The residual challenges highlight the higher structural costs of SPA architectures, and must be wrestled down the hard (read: "expensive") way.
Initial successes also create cognitive dissonance within the team. Engineers and managers armed with experience and evidence will begin to compare themselves to competitors and, eventually, question the architecture they adopted. Teams that embark on this journey can (slowly) become masters of their own destinies.
From the plateau of enlightenment, it's simple to look back and acknowledge that for most sites, the pain, chaos, churn, and cost associated with SPA technology stacks are entirely unnecessary. From that vantage point, a team can finally, firmly set policy.
Carrying Capacity
Organisations that purchase and operate technology all have a base carrying capacity. The cumulative experience, training, and OpEx budgets of teams set the level.
Traditional web development presents a model that many organisations have learned to manage. The incremental costs of additional HTML-based frontends are well understood, from authorisation to database capacity to the intricacies of web servers
SPA-oriented frameworks? Not so much.
In practice, the complex interplay of bundlers, client-side routing mechanisms, GraphQL API endpoints, and the need to rebuild monitoring and logging infrastructure creates wholly unowned areas of endemic complexity. This complexity is experienced as a shock to the operational side of the house.
Before, developers deploying new UIs would cabin the complexity and cost within the data center, enabling mature tools to provide visibility. SPAs and client-side rendered UIs invalidate all of these assumptions. A common result is that the operational complexity of SPA-based technologies creates new, additive points of poorly monitored system failure — failures like the ones we have explored in this series.
This is an industry-wide scandal. Promoters of these technologies have not levelled with their customers. Instead, they continue to flog each new iteration as "the future" despite the widespread failure of these models outside sophisticated organisations.
The pitch for SPA-oriented frameworks like React and Angular has always been contingent — we might deliver better experiences if long chains of interactions can be handled faster on the client.
It's time to acknowledge this isn't what is happening. For most organisations building JavaScript-first, the next dollar spent after launch day is likely go towards recovering basic functionality rather than adding new features.
That's no way to run a railroad.
Should This Be An SPA?
Public and private sector teams I consult with regularly experience ambush-by-JavaScript.
This is the predictable result of buying into frontend framework orthodoxy. That creed hinges on the idea that toweringly complex and expensive stacks of client-side JavaScript are necessary to deliver better user experiences.
But this has always been a contingent claim, at least among folks introspective enough to avoid suggesting JS frameworks for every site. Indeed, most web experiences should explicitly avoid both client-side rendered SPA UI and the component systems built to support them. Nearly all sites would be better off opting for progressive enhancement instead.
Doing otherwise is to invite the complexity fox into the OpEx henhouse. Before you know it, you're fighting with "SSR" and "islands" and "hybrid rendering" and "ISR" to get back to the sorts of results a bit of PHP or Ruby and some CSS deliver for a tenth the price.
So how can teams evaluate the appropriateness of SPAs and SPA-inspired frameworks? By revisiting the arguments offered by the early proponents of these approaches.
The entirety of SPA orthodoxy springs from the logic of the Ajax revolution. As a witness to, and early participant in, that movement, I can conclusively assert that the buzz around GMail and Google Maps and many other "Ajax web apps" was their ability to reduce latency for subsequent interactions once an up-front cost had been paid.
The logic of this trade depends, then, on the length of sessions. As we have discussed before, it's not clear that even GMail clears the bar in all cases.
The utility of the next quanta of script is intensely dependent on session depth.

Very few sites match the criteria for SPA architectures.
Questions managers can use to sort wheat from chaff:
- Does the average session feature more than 20 updates to, or queries against, the same subset of global data?
- Does this UI require features that naturally create long-lived sessions (e.g., chat, videoconferencing, etc.), and are those the site's primary purpose?
- Is there a reason the experience can't be progressively enhanced (e.g., audio mixing, document editing, photo manipulation, video editing, mapping, hardware interaction, or gaming)?
Answering these questions requires understanding critical user journeys. Flows that are most important to a site or project should be written down, and then re-examined through the lens of the marginal networks and devices of the user base.
The rare use-cases that are natural fits for today's JS-first dogma include:
- Document editors of all sorts
- Chat and videoconferencing apps
- Maps, geospatial, and BI visualisations
Very few sites should lead with JS-based, framework-centric development.
Teams can be led astray when sites include mutliple apps under a single umberella. The canonical example is WordPress; a blog reading experience for millions and a blog editing UI for dozens. Treating these as independent experiences with their own constraints and tech stacks is more helpful than pretending that they're actually a "single app". This is also the insight behind the "islands architecture", and transfers well to other contexts, assuming the base costs of an experience remain low.
The Pits
DevTools product managers use the phrase "pit of success" to describe how they hope teams experience their tools. The alternative is the (more common) "pit of ignorance".
The primary benefit of progressive enhancement over SPAs and SPA-begotten frameworks is that they leave teams with simpler problems, closer to the metal. Those challenges require attention and focus on the lived experience, which can be remediated cheaply once identified.
The alternative is considerably worse. In a previous post I claimed that:
SPAs are "YOLO" for web development.
This is because an over-reliance on JavaScript moves responsibility for everything into the main thread in the most expensive way.
Predictably, teams whose next PR adds to JS weight rather than HTML and CSS payloads will find themselves in the drink faster, and with tougher path out.
What's gobsmacking is that so many folks have seen these bets go sideways, yet continue to participate in the pantomime of JavaScript framework conformism. These tools aren't delivering except in the breach, but nobody will say so.
And if we were only lighting the bonuses of overpaid bosses on fire through under-delivery, that might be fine. But the JavaScript-industrial-complex is now hurting families in my community trying to access the help they're entitled to.
It's not OK.
Aftermath
Frontend is mired in a practical and ethical tar pit.
Not only are teams paying unexpectedly large premiums to keep the lights on, a decade of increasing JavaScript complexity hasn't even delivered the better user experiences we were promised.
We are not getting better UX for the escalating capital and operational costs. Instead, the results are getting worse for folks on the margins. JavaScript-driven frontend complexity hasn't just driven out the CSS and semantic-markup experts that used to deliver usable experiences for everyone, it is now a magnifier of inequality.
As previously noted, engineering is designing under constraint to develop products that serve users and society. The opposite of engineering is bullshitting, substituting fairy tales for inquiry and evidence.
For the frontend to earn and keep its stripes as an engineering discipline, frontenders need to internalise the envelope of what's possible on most devices.
Then we must take responsibility.
Next: The Way Out.
Thanks to Marco Rogers, and Frances Berriman for their encouragement in making this piece a series and for their thoughtful feedback on drafts.
3/4 of all devices are faster than this phone, which means 1/4 of phones are slower. Teams doing serious performance work tend to focus on even higher percentiles (P90, P95, etc.).
The Nokia G100 is by no means a hard target. Teams aspiring to excellence should look further down the price and age curves for representative compute power. Phones with 28nm-fabbed A53 cores are still out there in volume. ⇐
One response to the regressive performance of the sites enumerated here is a version of "they're just holding it wrong; everybody knows you should use Server-Side Rendering (SSR) to paint content quickly".
Ignoring the factual inaccuracies undergirding SPA apologetics5, the promised approaches ("SSR + hydration", "concurrent mode", etc.) have not worked.
We can definitively see they haven't worked because the arrival of INP has shocked the body politic. INP has created a disturbance in the JS ecosystem because, for the first time, it sets a price on main-thread excesses backed by real-world data.
Teams that adopt all these techniques are still are not achieving minimally good results. This is likely why "React Server Components" exists; it represents a last-ditch effort to smuggle some of the most costly aspects of the SPA-based tech stack back to the server where it always belonged.
At the risk of tedious repetition, what these INP numbers mean is that these are bad experiences for real users. And these bad experiences can be laid directly at the feet of tools and architectures that promised better experiences.
Putting the lie to SPA theatrics doesn't require inventing a new, more objective value system. The only petard needed to hoist the React ecosystem into the stratosphere is its own sales pitch, which it has miserably and consistently failed to achieve in practice. ⇐
The JavaScript community's omertà regarding the consistent failure of frontend frameworks to deliver reasonable results at acceptable cost is likely to be remembered as one of the most shameful aspects of frontend's lost decade.
Had the risks been prominently signposted, dozens of teams I've worked with personally could have avoided months of painful remediation, and hundreds more sites I've traced could have avoided material revenue losses.
Too many engineering leaders have found their teams beached and unproductive for no reason other than the JavaScript community's dedication to a marketing-over-results ethos of toxic positivity.
Shockingly, cheerleaders for this pattern of failure have not recanted, even when confronted with the consequences. They are not trustworthy. An ethical frontend practice will never arise from this pit of lies and half-truths. New leaders who reject these excesses are needed, and I look forward to supporting their efforts. ⇐
The first steps in remediating JS-based performance disasters are always the same:
- Audit server configurations, including:
- Check caching headers and server compression configurations.
- Enable HTTP/2 (if not already enabled).
- Removing extraneous critical-path connections, e.g. by serving assets from the primary rather than a CDN host.
- Audit the contents of the main bundle and remove unneeded or under-used dependencies.
- Implement code-splitting and dynamic imports.
- Set bundle size budgets and implement CI/CD enforcement.
- Form a group of senior engineers to act as a "latency council".
- Require the group meet regularly to review key performance metrics.
- Charter them to approve all changes that will impact latency.
- Have them institute an actionable "IOU" system for short-term latency regression.
- Require their collective input when drafting or grading OKRs.
- Beg, borrow, or
stealbuy low-end devices for all product managers and follow up to ensure they're using them regularly.
There's always more to explore. SpeedCurve's Performance Guide and WebPageTest.org's free course make good next steps. ⇐
- Audit server configurations, including:
Apologists for SPA architectures tend to trot out arguments with the form "nobody does X any more" or "everybody knows not to do Y" when facing concrete evidence that sites with active maintenance are doing exactly the things they have recently dissavowed, proving instead that not only are wells uncapped, but the oil slicks aren't even boomed.
It has never been true that in-group disfavour fully contains the spread of once-popular techniques. For chrissake, just look at the CSS-in-JS delusion! This anti-pattern appears in a huge fraction of the traces I look at from new projects today, and that fraction has only gone up since FB hipsters (who were warned directly by browser engineers that it was a terrible idea) finally declared it a terrible idea.
Almost none of today's regretted projects carry disclaimers. None of the frameworks that have led to consistent disasters have posted warnings about their appropriate use. Few boosters for these technologies even outline what they had to do to stop the bleeding (and there is always bleeding) after adopting these complex, expensive, and slow architectures.
Instead, teams are supposed to have followed every twist and turn of inscrutable faddism, spending effort to upgrade huge codebases whenever the new hotness changes.
Of course, when you point out that this is what the apologists are saying, no-true-Scotsmanship unfurls like clockwork.
It's irresponsibility theatre.
Consulting with more than a hundred teams over the past eight years has given me ring-side season tickets to the touring production of this play. The first few performances contained frission, some mystery...but now it's all played out. There's no paradox — the lies by omission are fully revealed, and the workmanlike retelling by each new understudy is as charmless as the last.
All that's left is to pen scathing reviews in the hopes that the tour closes for good. ⇐
Reckoning: Part 2 — Object Lesson
Other posts in the series:
The Golden Wait
BenefitsCal is the state of California's recently developed portal for families that need to access SNAP benefits (née "food stamps"):1
Code for America's getcalfresh.org performs substantially the same function, providing a cleaner, faster, and easier-to-use alternative to California county and state benefits applications systems:
The like-for-like, same-state comparison getcalfresh.org provides is unique. Few public sector services in the US have competing interfaces, and only Code for America was motivated to build one for SNAP applications.
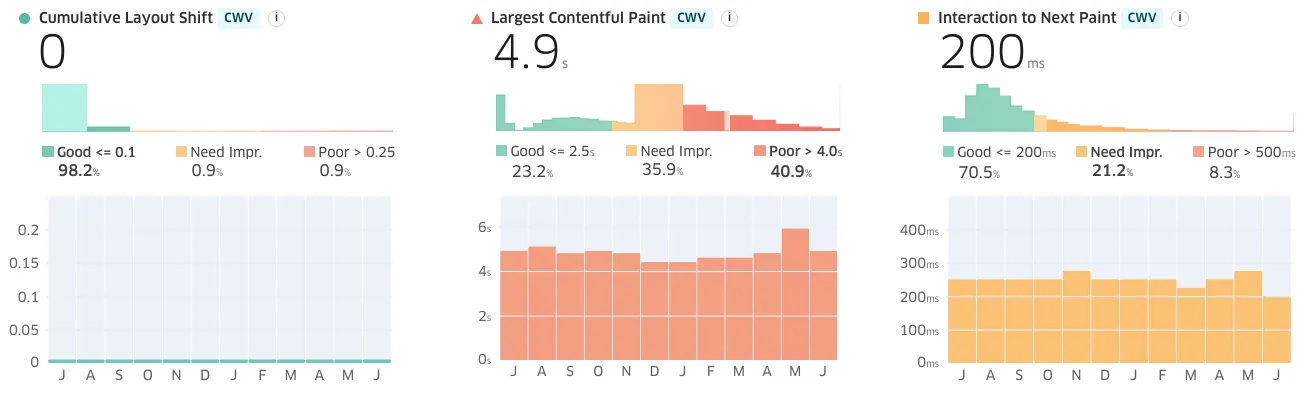
WebPageTest.org timelines document a painful progression. Users can begin to interact with getcalfresh.org before the first (of three) BenefitsCal loading screens finish (scroll right to advance):
Google's Core Web Vitals data backs up test bench assessments. Real-world users are having a challenging time accessing the site:

But wait! There's more. It's even worse than it looks.
The multi-loading-screen structure of BenefitsCal fakes out Chrome's heuristic for when to record Largest Contentful Paint.

The real-world experience is significantly worse than public CWV metrics suggest.
Getcalfresh.org uses a simpler, progressively enhanced, HTML-first architecture to deliver the same account and benefits signup process, driving nearly half of all signups for California benefits (per CalSAWS).
The results are night-and-day:2

And this is after the state spent a million dollars on work to achieve "GCF parity".
The Truth Is In The Trace
No failure this complete has a single father. It's easy to enumerate contributing factors from the WebPageTest.org trace, and a summary of the site's composition and caching make for a bracing read:
| File Type | First View | Repeat View | |||||
|---|---|---|---|---|---|---|---|
| Wire (KB) | Disk | Ratio | Wire | Disk | Ratio | Cached | |
| JavaScript | 17,435 | 25,865 | 1.5 | 15,950 | 16,754 | 1.1 | 9% |
| Other (text) | 1,341 | 1,341 | 1.0 | 1,337 | 1,337 | 1.0 | 1% |
| CSS | 908 | 908 | 1.0 | 844 | 844 | 1.0 | 7% |
| Font | 883 | 883 | N/A | 832 | 832 | N/A | 0% |
| Image | 176 | 176 | N/A | 161 | 161 | N/A | 9% |
| HTML | 6 | 7 | 1.1 | 4 | 4 | 1.0 | N/A |
| Total | 20,263 | 29,438 | 1.45 | 18,680 | 19,099 | 1.02 | 7% |
The first problem is that this site relies on 25 megabytes of JavaScript (uncompressed, 17.4 MB on over the wire) and loads all of it before presenting any content to users. This would be unusably slow for many, even if served well. Users on connections worse than the P75 baseline emulated here experience excruciating wait times. This much script also increases the likelihood of tab crashes on low-end devices.3
Very little of this code is actually used on the home page, and loading the home page is presumably the most common thing users of the site do:4
As bad as that is, the wait to interact at all is made substantially worse by inept server configuration. Industry-standard gzip compression generally results in 4:1-8:1 data savings for text resources (HTML, CSS, JavaScript, and "other") depending on file size and contents. That would reduce ~28 megabytes of text, currently served in 19MB of partially compressed resources, to between 3.5MB and 7MB.
But compression is not enabled for most assets, subjecting users to wait for 19MB of content. If CalSAWS built BenefitsCal using progressive enhancement, early HTML and CSS would become interactive while JavaScript filigrees loaded in the background. No such luck for BenefitsCal users on slow connections.

Thanks to the site's React-centric, JavaScript-dependent, client-side rendered, single-page-app (SPA) architecture, nothing is usable until nearly the entire payload is downloaded and run, defeating built-in browser mitigations for slow pages. Had progressive enhancement been employed, even egregious server misconfigurations would have had a muted effect by comparison.5
Zip It
Gzip compression has been industry standard on the web for more than 15 years, and more aggressive algorithms are now available. All popular web servers support compression, and some enable it by default. It's so common that nearly every web performance testing tool checks for it, including Google's PageSpeed Insights.6
Gzip would have reduced the largest script from 2.1MB to a comparatively svelte 340K; a 6.3x compression ratio:
$ gzip -k main.2fcf663c.js
$ ls -l
> total 2.5M
> ... 2.1M Aug 1 17:47 main.2fcf663c.js
> ... 340K Aug 1 17:47 main.2fcf663c.js.gz
Not only does the site require a gobsmacking amount of data on first visit, it taxes users nearly the same amount every time they return.
Because most of the site's payload is static, the fraction cached between first and repeat views should be near 100%. BenefitsCal achieves just 7%.
This isn't just perverse; it's so far out of the norm that I struggled to understand how CalSAWS managed to so thoroughly misconfigure a web server modern enough to support HTTP/2.
The answer? Overlooked turnkey caching options in CloudFront's dashboard.7
This oversight might have been understandable at launch. The mystery remains how it persisted for nearly three years (pdf). The slower the device and network, the more sluggish the site feels. Unlike backend slowness, the effects of ambush-by-JavaScript can remain obscured by the fast phones and computers used by managers and developers.
But even if CalSAWS staff never leave the privilege bubble, there has been plenty of feedback:

'And it's so f'n slow.'
Having placed a bet on client-side rendering, CalSAWS, Gainwell, and Deloitte staff needed to add additional testing and monitoring to assess the site as customers experience it. This obviously did not happen.
The most generous assumption is they were not prepared to manage the downsides of the complex and expensive JavaScript-based architecture they chose over progressive enhancement.89
Near Peers
Analogous sites from other states point the way. For instance, Wisconsin's ACCESS system:
There's a lot that could be improved about WI ACCESS's performance. Fonts are loaded too late, and some of the images are too large. They could benefit from modern formats like WebP or AVIF. JavaScript could be delay-loaded and served from the same origin to reduce connection setup costs. HTTP/2 would left-shift many of the early resources fetched in this trace.

But the experience isn't on fire, listing, and taking on water.

Because the site is built in a progressively enhanced way, simple fixes can cheaply and quickly improve on an acceptable baseline.
Even today's "slow" networks and phones are so fast that sites can commit almost every kind of classic error and still deliver usable experiences. Sites like WI ACCESS would have felt sluggish just 5 years ago but work fine today. It takes extra effort to screw up as badly as BenefitsCal has.
Blimey
To get a sense of what's truly possible, we can compare a similar service from the world leader in accessible, humane digital public services: gov.uk, a.k.a., the UK Government Digital Service (GDS).
California enjoys a larger GDP and a reputation for technology excellence, and yet the UK consistently outperforms the Golden State's public services.
There are layered reasons for the UK's success:
- GDS's Service Manual is an enforceable guide for how government services should be built and delivered continuously. This liberates each department from reinventing processes or rediscovering how best to deliver through trial and error.
- The GDS Service Manual requires progressive-enhancement.
- Progressive Enhancement is baked into infrastructure and practice by patterns long documented in the official GDS design system and reference implementation.
- The parallel Service Standard clearly articulates the egalitarian, open values that every delivery team is held to.
- The Service Manual and Service Standard nearly shout "do not write an omnibus contract!" if you can read between the lines. The interlocking processes, spend controls, and agile activism serve to grind down too-big-to-fail procurement into a fine powder, one contract at a time.10
The BenefitsCal omnishambles should trigger a fundamental rethink. Instead, the prime contractors have just been awarded another $1.3BN over a long time horizon. CalSAWS is now locked in an exclusive arrangement with the very folks that broke the site with JavaScript. Any attempt at fixing it now looks set to reward easily-avoided failure.
Too-big-to-fail procurement isn't just flourishing in California; it's thriving across public benefits application projects nationwide. No matter how badly service delivery is bungled, the money keeps flowing.
JavaScript Masshattery
CalSAWS is by no means alone.
For years, I have been documenting the inequality exacerbating effects of JS-based frontend development based on the parade of private-sector failures that cross my desk.11
Over the past decade, those failures have not elicited a change in tone or behaviour from advocates for frameworks, but that might be starting to change, at least for high-traffic commercial sites.
Core Web Vitals is creating pressure on slow sites that value search engine traffic. It's less clear what effect it will have on public-sector monopsonies. The spread of unsafe-at-any-scale JavaScript frameworks into government is worrying as it's hard to imagine what will dislodge them. There's no comparison shopping for food stamps.12
The Massachusetts Executive Office of Health and Human Services (EOHHS) seems to have fallen for JavaScript marketing hook, line, and sinker.
DTA Connect is the result, a site so slow that it frequently takes me multiple attempts to load it from a Core i7 laptop attached to a gigabit network.
From the sort of device a smartphone-dependent mom might use to access the site? It's lookin' slow.
I took this trace multiple times, as WebPageTest.org kept timing out. It's highly unusual for a site to take this long to load. Even tools explicitly designed to emulate low-end devices and networks needed coaxing to cope.
The underlying problem is by now familiar:

Vexingly, whatever hosting infrastructure Massachusetts uses for this project throttles serving to 750KB/s. This bandwidth restriction combines with server misconfigurations to ensure the site takes forever to load, even on fast machines.13
It's a small mercy that DTA Connect sets caching headers, allowing repeat visits to load in "only" several seconds. Because of the SPA architecture, nothing renders until all the JavaScript gathers its thoughts at the speed of the local CPU.
The slower the device, the longer it takes.14

A page this simple, served entirely from cache, should render in much less than a second on a device like this.15
Maryland Enters The Chat
The correlation between states procuring extremely complex, newfangled JavaScript web apps and fumbling basic web serving is surprisingly high.
Case in point, the residents of Maryland wait seconds on a slow connection for megabytes of uncompressed JavaScript, thanks to the Angular 9-based SPA architecture of myMDTHINK.16

American legislators like to means test public services. In that spirit, perhaps browsers should decline to load multiple megabytes of JavaScript from developers that feel so well-to-do they can afford to skip zipping content for the benefit of others.
Chattanooga Chug Chug
Tennessee, a state with higher-than-average child poverty, is at least using JavaScript to degrade the accessibility of its public services in unique ways.
Instead of misconfiguring web servers, The Volunteer State uses Angular to synchronously fetch JSON files that define the eventual UI in an onload event handler.


Needless to say, this does not read to the trained eye as competent work.
SNAP? In Jersey? Fuhgeddaboudit
New Jersey's MyNJHelps.gov (yes, that's the actual name) mixes the old-timey slowness of multiple 4.5MB background stock photos with a nu-skool render-blocking Angular SPA payload that's 2.2MB on the wire (15.7MB unzipped), leading to first load times north of 20 seconds.
Despite serving the oversized JavaScript payload relatively well, the script itself is so slow that repeat visits take nearly 13 seconds to display fully:
What Qualcomm giveth, Angular taketh away.

Debugging the pathologies of this specific page are beyond the scope of this post, but it is a mystery how New Jersey managed to deploy an application that triggers a debugger; statement on every page load with DevTools open whilst also serving a 1.8MB (13.8MB unzipped) vendor.js file with no minification of any sort.
One wonders if anyone involved in the deployment of this site are developers, and if not, how it exists.
Hoosier Hospitality
Nearly half of the 15 seconds required to load Indiana's FSSA Benefits Portal is consumed by a mountain of main-thread time burned in its 4.2MB (16MB unzipped) Angular 8 SPA bundle.
Combined with a failure to set appropriate caching headers, both timelines look identically terrible:
Can you spot the difference?


Deep Breaths
The good news is that not every digital US public benefits portal has been so thoroughly degraded by JavaScript frameworks. Code for America's 2023 Benefits Enrollment Field Guide study helpfully ran numbers on many benefits portals, and a spot check shows that those that looked fine last year are generally in decent shape today.
Still, considering just the states examined in this post, one in five US residents will hit underperforming services, should they need them.
None of these sites need to be user hostile. All of them would be significantly faster if states abandoned client-side rendering, along with the legacy JavaScript frameworks (React, Angular, etc.) built to enable the SPA model.
GetCalFresh, Wisconsin, and the UK demonstrate a better future is possible today. To deliver that better future and make it stick, organisations need to learn the limits of their carrying capacity for complexity. They also need to study how different architectures fail in order to select solutions that degrade more gracefully.
Next: Caprock: Development without constraints isn't engineering.
Thanks to Marco Rogers, and Frances Berriman for their encouragement in making this piece a series and for their thoughtful feedback on drafts.
If you work on a site discussed in this post, I offer (free) consulting to public sector services. Please get in touch.
The JavaScript required to render anything on BenefitsCal embodies nearly every anti-pattern popularised (sometimes inadvertently, but no less predictably) by JavaScript influencers over the past decade, along with the most common pathologies of NPM-based, React-flavoured frontend development.
A perusal of the code reveals:
- Multiple reactive systems, namely React, Vue, and RxJS.
- "Client-side routing" metadata for the entire site bundled into the main script.
- React components for all UI surfaces across the site, including:
- Components for every form, frontloaded. No forms are displayed on the home page.
- An entire rich-text editing library. No rich-text editing occurs on the home page.
- A complete charting library. No charts appear on the home page.
- Sizable custom scrolling and drag-and-drop libraries. No custom scrolling or drag-and-drop interactions occur on the home page.
- A so-called "CSS-in-JS" library that does not support compilation to an external stylesheet. This is categorically the slowest and least efficient way to style web-based UIs. On its own, it would justify remediation work.
- Unnecessary polyfills and transpilation overhead, including:
classsyntax transpilation.- Generator function transpilation and polyfills independently added to dozens of files.
- Iterator transpilation and polyfills.
- Standard library polyfills, including obsolete userland implementations of
ArrayBuffer,Object.assign()and repeated inlining of polyfills for many others, including a litany of outdated TypeScript-generated polyfills, bloating every file. - Obselete DOM polyfills, including a copy of Sizzle to provide emulation for
document.querySelectorAll()and a sizable colourspace conversion system, along with userland easing functions for all animations supported natively by modern CSS.
- No fewer than
2...wait...5...no, 6 large — seemingly different! —User-Agentparsing libraries that support browsers as weird and wonderful as WebOS, Obigo, and iCab. What a delightful and unexpected blast from the past! (pdf) - What appears to be an HTML parser and userland DOM implementation!?!
- A full copy of Underscore.
- A full copy of Lodash.
- A full copy of
core-js. - A userland elliptic-curve cryptography implementation. Part of an on-page chatbot, naturally.
- A full copy of Moment.js. in addition to the custom date and time parsing functions already added via bundling of the (overlarge)
react-date-pickerlibrary. - An unnecessary OAuth library.
- An emulated version of the Node.js
bufferclass, entirely redundant on modern browsers. - The entire Amazon Chime SDK, which includes all the code needed to do videoconferencing. This is loaded in the critical path and alone adds multiple megabytes of JS spread across dozens of webpack-chunked files. No features of the home page appear to trigger videoconferencing.
- A full copy of the AWS JavaScript SDK, weighing 2.6MB, served separately.
- Obviously, nothing this broken would be complete without a Service Worker that only caches image files.
This is, to use the technical term, whack.
The users of BenefitsCal are folks on the margins — often working families — trying to feed, clothe, and find healthcare for kids they want to give a better life. I can think of few groups that would be more poorly served by such baffling product and engineering mismanagement. ⇐ ⇐
getcalfresh.org isn't perfect from a performance standpoint.
The site would feel considerably snappier if the heavy chat widget it embeds were loaded on demand with the facade pattern and if the Google Tag Manager bundle were audited to cut cruft. ⇐
Browser engineers sweat the low end because that's where users are17, and when we do a good job for them, it generally translates into better experiences for everyone else too. One of the most durable lessons of that focus has been that users having a bad time in one dimension are much more likely to be experiencing slowness in others.
Slow networks correlate heavily with older devices that have less RAM, slower disks, and higher taxes from "potentially unwanted software" (PUS). These machines may experience malware fighting with invasive antivirus, slowing disk operations to a crawl. Others may suffer from background tasks for app and OS updates that feel fast on newer machines but which drag on for hours, stealing resources from the user's real work the whole time.
Correlated badness also means that users in these situations benefit from any part of the system using fewer resources. Because browsers are dynamic systems, reduced RAM consumption can make the system faster, both through reduced CPU load from zram, as well as rebalancing in auto-tuning algorithms to optimise for speed rather than space.
The pursuit of excellent experiences at the margins is deep teacher about the systems we program, and a frequently humbling experience. If you want to become a better programmer or product manager, I recommend focusing on those cases. You'll always learn something. ⇐
It's not surprising to see low code coverage percentages on the first load of an SPA. What's shocking is that the developers of BenefitsCal confused it with a site that could benefit from this architecture.
To recap: the bet that SPA-oriented JavaScript frameworks make is that it's possible to deliver better experiences for users when the latency of going to the server can be shortcut by client-side JavaScript.
I cannot stress this enough: the premise of this entire wing of web development practice is that expensive, complex, hard-to-operate, and wicked-to-maintain JavaScript-based UIs lead to better user experiences.
It is more than fair to ask: do they?
In the case of BenefitsCal and DTA Connect, the answer is "no".
The contingent claim of potentially improved UI requires dividing any additional up-front latency by the number of interactions, then subtracting the average improvement-per-interaction from that total. It's almost impossible to imagine any app with sessions long enough to make 30-second up-front waits worthwhile, never mind a benefits application form.
These projects should never have allowed "frontend frameworks" within a mile of their git repos. That they both picked React (a system with a lurid history of congenital failure) is not surprising, but it is dispiriting.
Previous posts here have noted that site structure and critical user journeys largely constrain which architectures make sense:
Sites with short average sessions cannot afford much JS up-front. These portals serve many functions: education, account management, benefits signup, and status checks. None of these functions exhibit the sorts of 50+ interaction sessions of a lived-in document editor (Word, Figma) or email client (Gmail, Outlook). They are not "toothbrush" services that folks go to every day, or which they use over long sessions.
Even the sections that might benefit from additional client-side assistance (rich form validation, e.g.) cannot justify loading all of that code up-front for all users.
The failure to recognise how inappropriate JavaScript-based SPA architectures are for most sites is an industry-wide scandal. In the case of these services, that scandal takes on whole new dimension of reckless irresponsibility. ⇐
JavaScript-based SPAs yank the reins away from the browser while simultaneously frontloading code at the most expensive time.
SPA architectures and the frameworks built to support them put total responsibility for all aspects of site performance squarely on the shoulders of the developer. Site owners who are even occasionally less than omniscient can quickly end up in trouble. It's no wonder many teams I work with are astonished at how quickly these tools lead to disastrous results.
SPAs are "YOLO" for web development.
Their advocates' assumption of developer perfection is reminiscent of C/C++'s approach to memory safety. The predictable consequences should be enough to disqualify them from use in most new work. The sooner these tools and architectures are banned from the public sector, the better. ⇐
Confoundingly, while CalSAWS has not figured out how to enable basic caching and compression, it has rolled out firewall rules that prevent many systems like PageSpeed Insights from evaluating the page through IP blocks.
The same rules also prevent access from IPs geolocated to be outside the US. Perhaps it's also a misconfiguration? Surely CalSAWS isn't trying to cut off access to services for users who are temporarialy visiting family in an emergency, right? ⇐
There's a lot to say about BenefitsCal's CloudFront configuration debacle.
First, and most obviously: WTF, Amazon?
It's great that these options are single-configuration and easy to find when customers go looking for them, but they should not have to go looking for them. The default for egress-oriented projects should be to enable this and then alert on easily detected double-compression attempts.
Second: WTF, Deloitte?
What sort of C-team are you stringing CalSAWS along with? Y'all should be ashamed. And the taxpayers of California should be looking to claw back funds for obscenely poor service.
Lastly: this is on you, CalSAWS.
As the procurer and approver of delivered work items, the failure to maintain a minimum level of in-house technical skill necessary to call BS on vendors is inexcusable.
New and more appropriate metrics for user success should be integrated into public reporting. That conversation could consume an entire blog post; the current reports are little more than vanity metrics. The state should also redirect money it is spending with vendors to enhance in-house skills in building and maintaining these systems directly.
It's an embarrassment that this site is as broken as it was when I began tracing it three years ago. It's a scandal that good money is being tossed after bad. Do better. ⇐
It's more likely that CalSAWS are inept procurers and that Gainwell + Deloitte are hopeless developers.
The alternative requires accepting that one or all of these parties knew better and did not act, undermining the struggling kids and families of California in the process. I can't square that with the idea of going to work every day for years to build and deliver these services. ⇐
In fairness, building great websites doesn't seem to be Deloitte's passion.
Deloitte.com performs poorly for real-world users, a population that presumably includes a higher percentage of high-end devices than other sites traced in this post. But even Deloitte could have fixed the BenefitsCal mess had CalSAWS demanded better. ⇐
It rankles a bit that what the UK's GDS has put into action for the last decade is only now being recognised in the US.
If US-centric folks need to call these things "products" instead of "services" to make the approach legible, so be it! Better late than never. ⇐
I generally have not not posted traces of the private sector sites I have spent much of the last decade assisting, preferring instead to work quietly to improve their outcomes.
The exception to this rule is the public sector, where I feel deeply cross-pressured about the sort of blow-back that underpaid civil servants may face. However, sunlight is an effective disinfectant, particularly for services we all pay for. The tipping point in choosing to post these traces is that by doing so, we might spark change across the whole culture of frontend development. ⇐
getcalfresh.org is the only direct competitor I know of to a state's public benefits access portal, and today it drives nearly half of all SNAP signups in California. Per BenefitsCal meeting notes (pdf), it is scheduled to be decommissioned next year.
Unless BenefitsCal improves dramatically, the only usable system for SNAP signup in the most populous state will disappear when it goes. ⇐
Capping the effective bandwidth of a server is certainly one way to build solidarity between users on fast and slow devices.
It does not appear to have worked.
The glacial behaviour of the site for all implies managers in EOHHS must surely have experienced DTA Connect's slowness for themselves and declined to do anything about it. ⇐
The content and structure of DTA Connect's JavaScript are just as horrifying as BenefitsCal's1:1 and served just as poorly. Pretty-printed, the main bundle runs to 302,316 lines.
I won't attempt nearly as exhaustive inventory of the #fail it contains, but suffice to say, it's a Create React App special. CRAppy, indeed.
Many obsolete polyfills and libraries are bundled, including (but not limited to):
- A full copy of core-js
- Polyfills for features as widely supported as
fetch() - Transpilation down to ES5, with polyfills to match
- A full userland elliptic-curve cryptography library
- A userland implementation of BigInt
- A copy of zlib.js
- A full copy of the Public Suffix List
- A full list of mime types (thousands of lines).
- What appears to be a relatively large rainbow table.
Seasoned engineers reading this list may break out in hives, and that's an understandable response. None of this is necessary, and none of it is useful in a modern browser. Yet all of it is in the critical path.
Some truly unbelievable bloat is the result of all localized strings for the entire site occurring in the bundle. In every supported language.
Any text ever presented to the user is included in English, Spanish, Portuguese, Chinese, and Vietnamese, adding megabytes to the download.
A careless disregard for users, engineering, and society permeates this artefact. Massachusetts owes citizens better. ⇐
Some junior managers still believe in the myth of the "10x" engineer, but this isn't what folks mean when they talk about "productivity". Or at least I hope it isn't. ⇐
Angular is now on version 18, meaning Maryland faces a huge upgrade lift whenever it next decides to substantially improve myMDTHINK. ⇐
Browsers port to macOS for CEOs, hipster developers, and the tech press. Macs are extremely niche devices owned exclusively by the 1-2%. Its ~5% browsing share is inflated by the 30% not yet online, almost none of whom will be able to afford Macs.
Wealth-related factors also multiply the visibility of high-end devices (like Macs) in summary statistics. These include better networks and faster hardware, both of which correlate with heavier browsing. Relatively high penetration in geographies with strong web use also helps. For example, Macs have 30% share of desktop-class sales in the US, vs 15% worldwide..
The overwhelming predominance of smartphones vs. desktops seals the deal. In 2023, smartphones outsold desktops and laptops by more than 4:1. This means that smartphones outnumber laptops and desktops to an even greater degree worldwide than they do in the US.
Browser makers keep Linux ports ticking over because that's where developers live (including many of their own). It's also critical for the CI/CD systems that power much of the industry.
Those constituencies are vocal and wealthy, giving them outsized influence. But iOS and and macOS aren't real life; Android and Windows are, particularly their low-end, bloatware-filled expressions.
Them's the breaks. ⇐
Reckoning: Part 1 — The Landscape
Instead of an omnibus mega-post, this investigation into JavaScript-first frontend culture and how it broke US public services has been released in four parts. Other posts in the series:
When you live in the shadow of a slow-moving crisis, it's natural to tell people about it. At volume. Doubly so when engineers can cheaply and easily address the root causes with minor tweaks. As things worsen, it's also hard not to build empathy for Cassandra.
In late 2011, I moved to London, where the Chrome team was beginning to build Google's first "real" browser for Android.1 The system default Android Browser had, up until that point, been based on the system WebView, locking its rate of progress to the glacial pace of device replacement.2
In a world where the Nexus 4's 2GB of RAM and 32-bit, 4-core CPU were the high-end, the memory savings the Android Browser achieved by reusing WebView code mattered immensely.3 Those limits presented enormous challenges for Chromium's safer (but memory-hungry) multi-process sandboxing. Android wasn't just spicy Linux; it was an entirely new ballgame.
Even then, it was clear the iPhone wasn't a fluke. Mobile was clearly on track to be the dominant form-factor, and we needed to adapt. Fast.4
Browsers made that turn, and by 2014, we had made enough progress to consider how the web could participate in mobile's app-based model. This work culminated in 2015's introduction of PWAs and Push Notifications.
Disturbing patterns emerged as we worked with folks building on this new platform. A surprisingly high fraction of them brought slow, desktop-oriented JavaScript frameworks with them to the mobile web. These modern, mobile-first projects neither needed nor could afford the extra bloat frameworks included to paper over the problems of legacy desktop browsers. Web developers needed to adapt the way browser developers had, but consistently failed to hit the mark.
By 2016, frontend practice had fully lapsed into wish-thinking. Alarms were pulled, claxons sounded, but nothing changed.
It could not have come at a worse time.
By then, explosive growth at the low end was baked into the cake. Billions of feature-phone users had begun to trade up. Different brands endlessly reproduced 2016's mid-tier Androids under a dizzying array of names. The only constants were the middling specs and ever-cheaper prices. Specs that would set punters back $300 in 2016, sold for only $100 a few years later, opening up the internet to hundreds of millions along the way. The battle between the web and apps as the dominant platform was well and truly on.
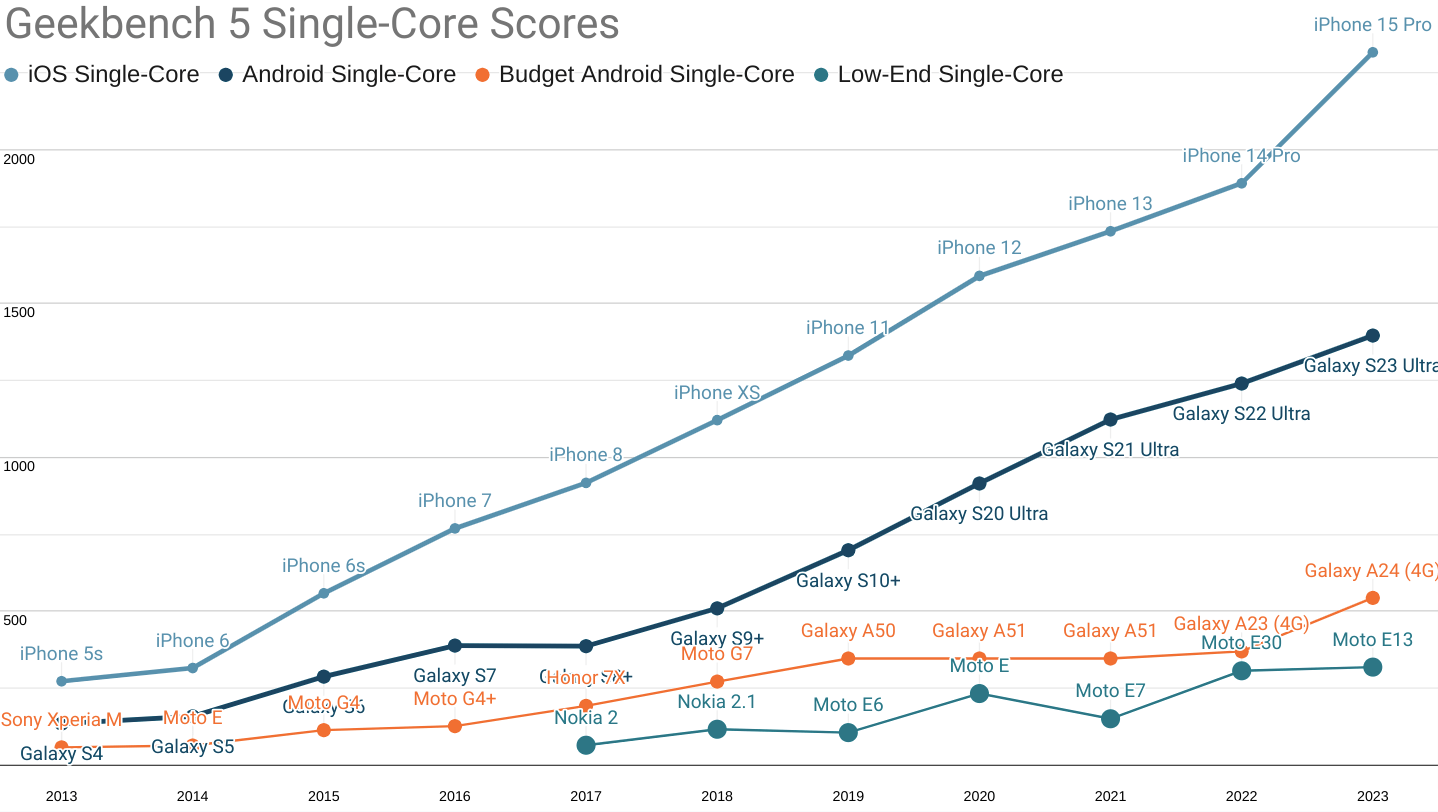
Geekbench 5 single-core scores for 'fastest iPhone', 'fastest Android', 'budget', and 'low-end' segments.
Nearly all growth in smartphone sales volume since the mid '10s occured in the 'budget' and 'low-end' categories.
But the low-end revolution barely registered in web development circles. Frontenders poured JavaScript into the mobile web at the same rate as desktop, destroying any hope of a good experience for folks on a budget.

As this blog has covered at length, median device specs were largely stagnant between 2014 and 2022. Meanwhile, web developers made sure the "i" in "iPhone" stood for "inequality."
Prices at the high end accelerated, yet average selling prices remained stuck between $300 and $350. The only way the emergence of the $1K phone didn't bump the average up was the explosive growth at the low end. To keep the average selling price at $325, three $100 low-end phones needed to sell for each $1K iPhone; which is exactly what happened.
And yet, the march of JavaScript-first, framework-centric dogma continued, no matter how incompatible it was with the new reality. Predictably, tools sold on the promise they would deliver "app-like experiences" did anything but.5
Billions of cheap phones that always have up-to-date browsers found their CPUs and networks clogged with bloated scripts designed to work around platform warts they don't have.
Environmental Factors
In 2019, Code for America published the first national-level survey of online access to benefits programs, which are built and operated by each state. The follow-up 2023 study provides important new data on the spread of digital access to benefits services.
One valuable artefact from CFA's 2019 research is a post by Dustin Palmer, documenting the missed opportunity among many online benefits portals to design for the coming mobile-first reality that was already the status quo in the rest of the world.


Moving these systems online only reduces administrative burdens in a contingent sense; if portals fail to work well on phones, smartphone-dependent folks are predictably excluded:

But poor design isn't the only potential administrative burden for smartphone-dependent users.6
The networks and devices folks use to access public support aren't latest-generation or top-of-the-line. They're squarely in the tail of the device price, age, and network performance distributions. Those are the overlapping conditions where the consistently falsified assumptions of frontend's lost decade have played out disastrously.
It would be tragic if public sector services adopted the JavaScript-heavy stacks that frontend influencers have popularised. Framework-based, "full-stack" development is now the default in Silicon Valley, but should obviously be avoided in universal services. Unwieldy and expensive stacks that have caused agony in the commercial context could never be introduced to the public sector with any hope of success.
Right?
Next: Object Lesson: a look at California's digital benefits services.
Thanks to Marco Rogers, and Frances Berriman for their encouragement in making this piece a series and for their thoughtful feedback on drafts.
A "real browser", as the Chrome team understood the term circa 2012, included:
- Chromium's memory-hungry multi-process architecture which dramatically improved security and stability
- Winning JavaScript performance using our own V8 engine
- The Chromium network stack, including support for SPDY and experiments like WebRTC
- Updates that were not locked to OS versions
Of course, the Chrome team had wanted to build a proper mobile browser sooner, but Android was a paranoid fiefdom separate from Google's engineering culture and systems. And the Android team were intensely suspicious of the web, verging into outright hostility at times.
But internal Google teams kept hitting the limits of what the Android Browser could do, including Search. And when Search says "jump", the only workable response is "how high?"
WebKit-based though it was (as was Chrome), OS-locked features presented a familiar problem, one the Chrome team had solved with auto-update and Chrome Frame. A deal was eventually struck, and when Chrome for Android was delivered, the system WebView also became a Chromium-based, multi-process, sandboxed, auto-updating system. For most, that was job done.
This made a certain sort of sense. From the perspective of Google's upper management, Android's role was to put a search box in front of everyone. If letting Andy et al. play around with an unproven Java-based app model was the price, OK. If that didn't work, the web would still be there. If it did, then Google could go from accepting someone else's platform to having one it owned outright.7 Win/win.
Anyone trying to suggest a more web-friendly path for Android got shut down hard. The Android team always had legitimate system health concerns that they could use as cudgels, and they weilded them with abandon.
The launch of PWAs in 2015 was an outcome Android saw coming a mile away and worked hard to prevent. But that's a story for another day. ⇐
Android devices were already being spec'd with more RAM than contemporary iPhones, thanks to Dalvik's chonkyness. This, in turn, forced many OEMs to cut corners in other areas, including slower CPUs.
This effect has been a silent looming factor in the past decade's divergence in CPU performance between top-end Android and iPhones. Not only did Android OEMs have to pay a distinct profit margin to Qualcomm for their chips, but they also had to dip into the Bill Of Materials (BOM) budget to afford more memory to keep things working well, leaving less for the CPU.
Conversely, Apple's relative skimpiness on memory and burning desire to keep BOM costs low for parts it doesn't manufacture are reasons to oppose browser engine choice. If real browsers were allowed, end users might expect phones with decent specs. Apple keeps that in check, in part, by maximising code page reuse across browsers and apps that are forced to use the system WebView.
That might dig into margins ever so slightly, and we can't have that, can we? ⇐
It took browsers that were originally architected in a desktop-only world many years to digest the radically different hardware that mobile evolved. Not only were CPU speeds and memory budgets cut dramatically — nevermind the need to port to ARM, including JS engine JITs that were heavily optimised for x86 — but networks suddenly became intermittent and variable-latency.
There were also upsides. Where GPUs had been rare on the desktop, every phone had a GPU. Mobile CPUs were slow enough that what had felt like a leisurely walk away from CPU-based rendering on desktop became an absolute necessity on phones. Similar stories played out across input devices, sensors, and storage.
It's no exaggeration to say that the transition to mobile force-evolved browsers in a compressed time frame. If only websites had made the same transition. ⇐
Let's take a minute to unpack what the JavaScript framework claims of "app-like experiences" were meant to convey.
These were code words for more responsive UI, building on the Ajax momentum of the mid-naughties. Many boosters claimed this explicitly and built popular tools to support these specific architectures.
As we wander through the burning wreckage of public services that adopted these technologies, remember one thing: they were supposed to make UIs better. ⇐
When confronted with nearly unusable results from tools sold on the idea that they make sites easier, better, and faster to use, many technologists offer the variants of "but at least it's online!" and "it's fast enough for most people". The most insipid version implies causality, constructing a strawman but-for defense; "but these sites might not have even been built without these frameworks."9
These points can be both true and immaterial at the same time. It isn't necessary for poor performance to entirely exclude folks at the margins for it to be a significant disincentive to accessing services.
We know this because it has been proven and continually reconfirmed in commercial and lab settings. ⇐
The web is unattractive to every Big Tech company in a hurry, even the ones that owe their existence to it.
The web's joint custody arrangement rankles. The standards process is inscrutable and frustrating to PMs and engineering managers who have only ever had to build technology inside one company's walls. Playing on hard mode is unappealing to high-achievers who are used to running up the score.
And then there's the technical prejudice. The web's languages offend "serious" computer scientists. In the bullshit hierarchy of programming language snobbery, everyone looks down on JavaScript, HTML, and CSS (in that order).
The web's overwhelmingly successful languages present a paradox: for the comfort of the snob, they must simultaneously be unserious toys beneath the elevated palettes of "generalists" and also Gordian Knots too hard for anyone to possibly wield effectively. This dual posture justifies treating frontend as a less-than discipline, and browsers as anything but a serious application platform.
This isn't universal, but it is common, particularly in Google's C++/Java-pilled upper ranks.8 Endless budgetary space for projects like the Android Framework, Dart, and Flutter were the result. ⇐
Someday I'll write up the tale of how Google so thoroughly devalued frontend work that it couldn't even retain the unbelievably good web folks it hired in the mid-'00s. Their inevitable departures after years of being condescended to went hand-in-hand with an inability to hire replacements.
Suffice to say, by the mid '10s, things were bad. So bad an exec finally noticed. This created a bit of space to fix it. A team of volunteers answered the call, and for more than a year we met to rework recruiting processes and collateral, interview loop structures, interview questions, and promotion ladder criteria.
The hope was that folks who work in the cramped confines of someone else's computer could finally be recognised for their achievements. And for a few years, Google's frontends got markedly better.
I'm told the mean has reasserted itself. Prejudice is an insidious thing. ⇐
The but-for defense for underperforming frontend frameworks requires us to ignore both the 20 years of web development practice that preceeded these tools and the higher OpEx and CapEx costs associated with React-based stacks.
Managers sometimes offer a hireability argument, suggesting they need to adopt these univerally more expensive and harder to operate tools because they need to be able to hire. This was always nonsense, but never more so than in 2024. Some of the best, most talented frontenders I know are looking for work and would leap at the chance to do good things in an organisation that puts user experience first.
Others sometimes offer the idea that it would be too hard to retrain their teams. Often, these are engineering groups comprised of folks who recently retrained from other stacks to the new React hotness or who graduated boot camps armed only with these tools. The idea that either cohort cannot learn anything else is as inane as it is self-limiting.
Frontenders can learn any framework and are constantly retraining just to stay on the treadmill. The idea that there are savings to be had in "following the herd" into Next.js or similar JS-first development cul-de-sacs has to meet an evidentiary burden that I have rarely seen teams clear.
Managers who want to avoid these messes have options.
First, they can crib Kellan's tests for new technologies. Extra points for digesting Glyph's thoughts on "innovation tokens."
Next, they should identify the critical user journeys in their products. Technology choices are always situated in product constraints, but until the critical user journeys are enunciated, the selection of any specific architecture is likely to be wrong.
Lastly, they should always run bakeoffs. Once critical user journeys are outlined and agreed, bakeoffs can provide teams with essential data about how different technology options will perform under those conditions. For frontend technologies, that means evaluating them under representative market conditions.
And yes, there's almost always time to do several small prototypes. It's a damn sight cheaper than the months (or years) of painful remediation work. I'm sick to death of having to hand-hold teams whose products are suffocating under unusably large piles of cruft, slowly nursing their code-bases back to something like health as their management belatedely learns the value of knowing their systems deeply.
Managers that do honest, user-focused bakeoffs for their frontend choices can avoid adding their teams to the dozens I've consulted with who adopted extremely popular, fundamentally inappropriate technologies that have had disasterous effects on their businesses and team velocity. Discarding popular stacks from consideration through evidence isn't a career risk; it's literally the reason to hire engineers and engineering leaders in the first place. ⇐
Misfire
The W3C Technical Architecture Group1 is out with a blog post and an updated Finding regarding Google's recent announcement that it will not be imminently removing third-party cookies.
The current TAG members are competent technologists who have a long history of nuanced advice that looks past the shouting to get at the technical bedrock of complex situations. The TAG also plays a uniquely helpful role in boiling down the guidance it issues into actionable principles that developers can easily follow.
All of which makes these pronouncements seem like weak tea. To grok why, we need to walk through the threat model, look at the technology options, and try to understand the limits of technical interventions.
But before that, I should stipulate my personal position on third-party cookies: they aren't great!
They should be removed from browsers when replacements are good and ready, and Google's climbdown isn't helpful. That said, we have seen nothing of the hinted-at alternatives, so the jury's out on what the impact will be in practice.2
So why am I dissapointed in the TAG, given that my position is essentially what they wrote? Because it failed to acknowledge the limited and contingent upside of removing third-party cookies, or the thorny issues we're left with after they're gone.
Unmasking The Problem
So, what do third-party cookies do? And how do they relate to the privacy theat model?
Like a lot of web technology, third-party cookies have both positive and negative uses. Owing to a historcal lack of platform-level identity APIs, they form the backbone of nearly every large Single Sign-On (SSO) system. Thankfully, replacements have been developed and are being iterated on.
Unfortunately, some browsers have unilaterally removed them without developing such replacements, disrupting sign-in flows across the web, harming users and pushing businesses toward native mobile apps. That's bad, as native apps face no limits on communicating with third parties and are generally worse for tracking. They're not even subject to pro-user interventions like browser extensions. The TAG should have called out this aspect of the current debate in its Finding, encouraging vendors to adopt APIs that will make the transition smoother.
The creepy uses of third-party cookies relate to advertising. Third-party cookies provide ad networks and data brokers the ability to silently reidentify users as they browse the web. Some build "shadow profiles", and most target ads based on sites users visit. This targeting is at the core of the debate around third-party cookies.
Adtech companies like to claim targeting based on these dossiers allows them to put ads in front of users most likely to buy, reducing wasted ad spending. The industry even has a shorthand: "right people, right time, right place."
Despite the bold claims and a consensus that "targeting works," there's reason to believe pervasive surveillence doesn't deliver, and even when it does, isn't more effective.
Assuming the social utility of targeted ads is low — likely much lower than adtech firms claim — shouldn't we support the TAG's finding? Sadly, no. The TAG missed a critical opportunity to call for legislative fixes to the technically unfixable problems it failed to enumerate.
Privacy isn't just about collection, it's about correlation across time. Adtech can and will migrate to the server-side, meaning publishers will become active participants in tracking, funneling data back to ad networks directly from their own logs. Targeting pipelines will still work, with the largest adtech vendors consolidating market share in the process.
This is why "give us your email address for 30% discount" popups and account signup forms are suddenly everywhere. Email addresses are stable, long-lived reidentifiers. Overt mechanisms like this are already replacing third-party cookies. Make no mistake: post-removal, tracking will continue for as long as reidentification has perceived positive economic value. The only way to change that equation is legislation; anything else is a band-aid.
Pulling tracking out of the shadows is good, but a limited and contingent good. Users have a terrible time recognising and mitigating risk on the multi-month time-scales where privacy invasions play out. There's virtually no way to control or predict where collected data will end up in most jurisdictions, and long-term collection gets cheaper by the day.
Once correlates are established, or "consent" is given to process data in ways that facilitate unmasking, re-identification becomes trivial. It only takes giving a phone number to one delivery company, or an email address to one e-commerce site to suddenly light up a shadow profile, linking a vast amount of previously un-attributed browsing to a user. Clearing caches can reset things for a little while, but any tracking vendor that can observe a large proportion of browsing will eventually be able to join things back up.
Removal of third-party cookies can temporarily disrupt this reidentification while collection funnels are rebuilt to use "first party" data, but that's not going to improve the situation over the long haul. The problem isn't just what's being collected now, it's the ocean of dormant data that was previously slurped up.3 The only way to avoid pervasive collection and reidentification over the long term is to change the economics of correlation.
The TAG surely understands the only way to make that happen is for more jurisdictions to pass privacy laws worth a damn. It should say so.
Fire And Movement
The goal of tracking is to pick users out of crowds, or at least bucket them into small unique clusters. As I explained on Mastodon, this boils down to bits of entropy, and those bits are everywhere. From screen resolution and pixel density, to the intrinsic properties of the networks, to extensions, to language and accessibility settings that folks rely on to make browsing liveable. Every attribute that is even subtly different can be a building block for silent reidentification; A.K.A., "fingerprinting."4
In jurisdictions where laws allow collected data to remain the property of the collector, the risks posed by data-at-rest is only slightly attenuated by narrowing the funnel through which collection takes place.
It's possible to imagine computing that isn't fingerprintable, but that isn't what anyone is selling. For complex reasons, even the most cautious use of commodity computers is likely to be uniquely identifiable with enough time. This means that the question to answer isn't "do we think tracking is bad?", it's "given that we can't technically eliminate it, how can we rebuild privacy?". The TAG's new Finding doesn't wrestle with that question, doing the community a disservice in the process.
The most third-party cookie removal can deliver is temporary disruption. That disruption will affect distasteful collectors, costing them money in the short run. Many think of this as a win, I suspect because they fail to think through the longer-term consequences. The predictable effect will be a recalibration and entrenchment of surveillence methods. It will not put the panopticon out of business; only laws can do that.
For a preview of what this will look like, think back on Apple's "App Tracking Transparency" kayfabe, which did not visibly dent Facebook's long-term profits.
So this is not a solution to privacy, it's fire-and-movement tactics against corporate enemies. Because of the deep technical challenges in defeating fingerprinting4:1, even the most outspoken vendors have given up, introducing "nutrition labels" to shift responsibility for privacy onto consumers.
If the best vertically-integrated native ecosystems can do is to shift blame, the TAG should call out posturing about ineffective changes and push for real solutions. Vendors should loudly lobby for stronger laws that can truly change the game and the TAG should join those calls. The TAG should also advocate for the web, rather than playing into technically ungrounded fearmongering by folks trying to lock users into proprietary native apps whilst simultaneously depriving users of more private browsers.
Finding A Way Forward
The most generous take I can muster is that the TAG's work is half-done. Calling on vendors to drop third-party cookies has the virtue of being technical and actionable, properties I believe all TAG writing should embody. But having looked deeply at the situation, the TAG should have also called on browser vendors to support further reform along several axes — particularly vendors that also make native OSes.
First, if the TAG is serious about preventing tracking and improving the web ecosystem, it should call on all OS vendors to prohibit the use of "in-app browsers" when displaying third-party content within native apps.
It is not sufficient to prevent JavaScript injection because the largest native apps can simply convince the sites to include their scripts directly. For browser-based tracking attenuation to be effective, these side-doors must be closed. Firms grandstanding about browser privacy features without ensuring users can reliably enjoy the protections of their browser need to do better. The TAG is uniquely positioned to call for this erosion of privacy and the web ecosystem to end.
Next, the TAG should have outlined the limits of technical approaches to attenuating data collection. It should also call on browser vendors to adopt scale-based interventions (rather than absolutism) in mitigating high-entropy API use.5 The TAG should go first in moving past debates that don't acknowledge impossibilities in removing all reidentification, and encourage vendors to do the same. There's no solution to the privacy puzzle that can be solved by the purchase of a new phone, and the TAG should be clarion about what will end our privacy nightmare: privacy laws worth a damn.
Lastly, the TAG should highlight discrepancies between privacy marketing and the failure of vendors to push for strong privacy laws and enforcement. Because the threat model of privacy intrusion renders solely techincal interventions ineffective on long timeframes, this is the rare case in which the TAG should push past providing technical advice.
The TAG's role is to explain complex things with rigor and signpost credible ways forward. It has not done that yet regarding third-party cookies, but it's not too late.
Praise, as well as concern, in this post is specific to today's TAG's, not the output of the group while I served. I surely got a lot of things wrong, and the current TAG is providing a lot of value. My hope here is that it can extend this good work by expanding its new Finding. ⇐
Also, James Roswell can go suck eggs. ⇐
It's neither here nor there, but the TAG also failed in these posts to encourage users and developers to move their use of digital technology into real browsers and out of native apps which invasively track and fingerprint users to a degree web adtech vendors only fantasize about.
A balanced finding would call on Apple to stop stonewalling the technologies needed to bring users to safer waters, including PWA installation prompts. ⇐
As part of the drafting of the 2015 finding on Unsanctioned Web Tracking, the then-TAG (myself included) spent a great deal of time working through the details of potential fingerprinting vectors. What we came to realise was that only the Tor Browser had done the work to credibly analyise fingerprinting vectors and produce a coherent threat model. To the best of my knowledge, that remains true today.
Other vendors continue to publish gussied-up marketing documents and stroppy blog posts that purport to cover the same ground, but consistently fail to do so. It's truly objectionable that those same vendors also prevent users from chosing disciplined privacy-focused browsers.
To understand the difference, we can do a small thought experiment, enumerating what would be necessary to sand off currently-identifiable attributes of individual users. Because only 31 or 32 bits are needed to uniquely identify anybody (often less), we want a high safety factor. This means bundling users into very large crowds by removing distinct observable properties. To sand off variations between users, a truly private browser might:
- Run the entire browser in a VM in order to:
- Cap the number of CPU cores, frequency, and centralise on a single instruction set (e.g., emulating ARM when running on x86). Will likely result in a 2-5x slowdown.
- Ensure (high) fixed latency for all disk access.
- Set a uniform (low) cap on total memory.
- Disable hardware acceleration for all graphics and media.
- Disable JIT. Will slow JavaScript by 3-10x.
- Only allow a fixed set of fonts, screen sizes, pixel densities, gamuts, and refresh rates; no more resizing browsers with a mouse. The web will pixelated and drab and animations will feel choppy.
- Remove most accessibility settings.
- Remove the ability to install extensions.
- Eliminate direct typing and touch-based interactions, as those can leak timing information that's unique.
- Run all traffic through Tor or a similarly high-latency VPN egress nodes.
- Disable all reidentifying APIs (no more web-based video conferencing!)
Only the Tor project is shipping a browser anything like this today, and it's how you can tell that most of what passes for "privacy" features in other browsers are anti-annoyance and anti-creep-factor interventions; they matter, but won't end the digital panopticon. ⇐ ⇐
- Run the entire browser in a VM in order to:
It's not a problem that sign-in flows need third-party cookies today, but it is a problem that they're used for pervasive tracking.
Likewise, the privacy problems inherent in email collection or camera access or filesystem folders aren't absolute, they're related to scale of use. There are important use-cases that demand these features, and computers aren't going to stop supporting them. This means the debate is only whether or not users can use the web to meet those needs. Folks who push an absolutist line are, in effect, working against the web's success. This is anti-user, as the alternatives are generally much more invasive native apps.
Privacy problems arise at scale and across time. Browsers should be doing more to discourage high-quality reidentifiaction across cache clearing and in ways that escalate with risk. The first site you grant camera access isn't the issue; it's the 10th. Similarly, speed bumps should be put in place for use of reidentifying APIs on sites across cache clearing where possible.
The TAG can be instrumental is calling for this sort of change in approach. ⇐